

Ключевые моменты
Gemma 3 27B — это последняя открытая большая языковая модель Google с 27 миллиардами параметров, выпущенная в марте 2025 года.
Оснащена продвинутой архитектурой interleaved local-global attention и контекстным окном до 128K токенов.
Многоязычная и мультимодальная: поддерживает 140+ языков и задачи преобразования изображений в текст.
Инференс возможен на одном GPU H100, но для обучения требуется гораздо больше VRAM (более 500 ГБ).
Доступ через API обеспечивает экономичный и масштабируемый способ использования Gemma 3 27B без проблем с оборудованием, например, Novita AI.
Gemma 3 27B — это передовая открытая большая языковая модель, разработанная Google. Обладая мощными многоязычными и мультимодальными возможностями, она предназначена для продвинутых рассуждений, генерации контента и широкого корпоративного использования.
Что такое Gemma 3 27B?
Обзор Gemma 3 27B
Ключевые особенности и инновации последней открытой большой модели
📅Основная информация
Дата выпуска: 12 марта 2025
Размер модели: 27B параметров
Открытый исходный код: Да (Google)
🧠Архитектура и контекст
Архитектура: Interleaved Local-Global Attention
Контекстное окно: до 128K токенов (модель 1B: 32K)
Оптимизация памяти: увеличенное соотношение local/global attention и минимизация взрыва KV-кэша значительно снижают потребление памяти.
Более длинный контекст и эффективность памяти для масштабного ввода и инференса.
🌐Мультимодальность и языки
Многоязычность: поддержка 140+ языков
Мультимодальность: преобразование изображений в текст с помощью кодировщика SigLIP обеспечивает эффективную обработку визуальных данных.
Мультимодальность: преобразование изображений в текст и поддержка многих языков для широкого спектра сценариев.
⚡Производительность и обучение
Улучшенная производительность: инструктивная версия на 4B достигает производительности Gemma 2 27B — более эффективна при меньшем масштабе.
Обучающие данные: 14 триллионов токенов
Методы обучения: дистилляция знаний, продвинутое обучение с учетом квантования (QAT) и RLHF.
Дистилляция и QAT снижают потребление VRAM, сохраняя высокую производительность.
Бенчмарки Gemma 3 27B
Gemma 3 27B достигла впечатляющего рейтинга Elo 1339 на LMSys Chatbot Arena, войдя в топ-10 моделей наряду с ведущими закрытыми конкурентами, такими как o3-mini. Примечательно, что Gemma 3 27B показывает такую исключительную производительность, работая всего на одном NVIDIA H100 GPU — что резко контрастирует с другими моделями своего класса.
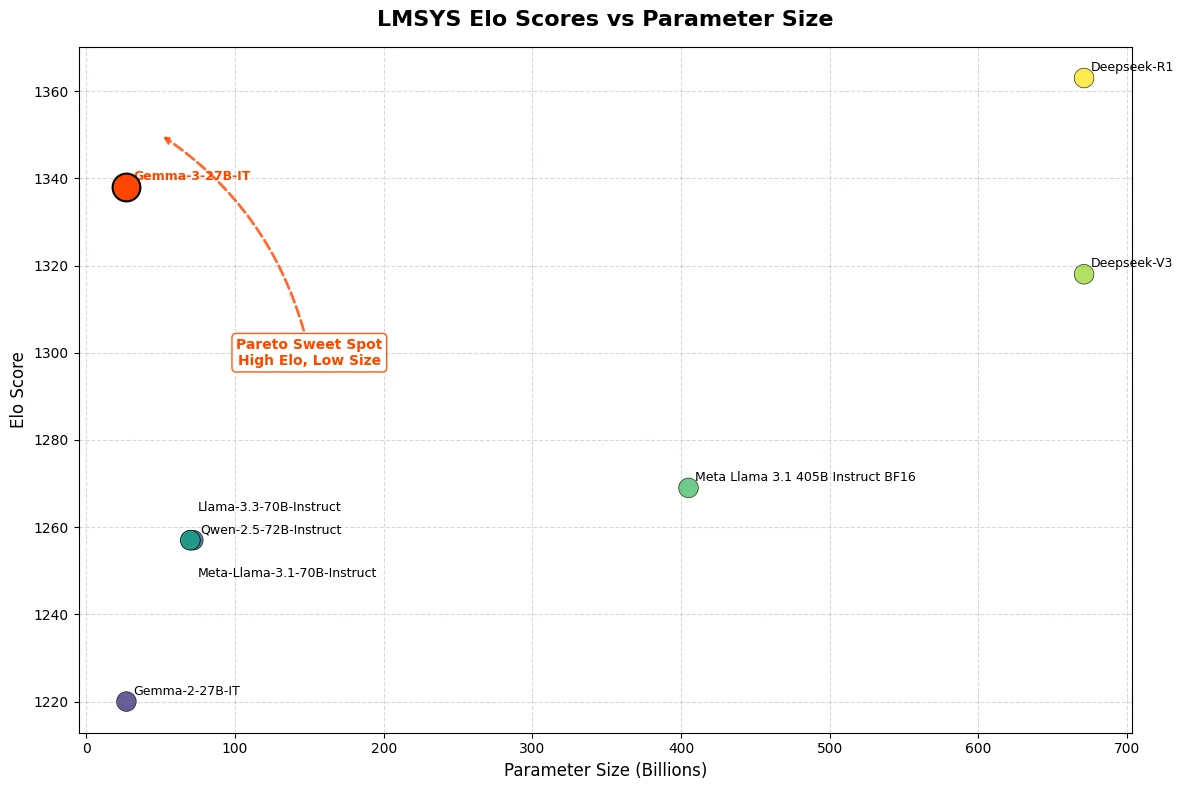
Из Hugging Face
Достаточно ли VRAM одного H100 для Gemma 3 27B?
Обзор VRAM
VRAM (видеопамять с произвольным доступом) — это выделенная память на графической карте, используемая для хранения данных изображений, параметров модели, текстур и другой информации, необходимой для высокопроизводительных задач, таких как глубокое обучение, рендеринг графики и обработка видео.
Что на самом деле означает большой объём VRAM?
- Поддержка более крупных моделей: позволяет загружать и запускать нейросетевые модели с большим количеством параметров или входными данными более высокого разрешения.
- Обработка больших пакетов (batch size): даёт возможность использовать большие размеры пакетов при обучении или инференсе, повышая пропускную способность и эффективность.
- Возможность выполнения более сложных задач: позволяет запускать сложные сцены, рендеринг высокого разрешения или несколько параллельных задач без ограничений по памяти.
- Снижение узких мест: предотвращает замедления из-за частой передачи данных между системной памятью и памятью GPU, что улучшает общую производительность.
Каковы потребности Gemma 3 27B в VRAM?
Требования к GPU и VRAM для Gemma 3
Gemma 3 1B
Рекомендуемый GPU: Nvidia T4
Требуемый VRAM: 16GB+
Gemma 3 4B
Рекомендуемый GPU: Nvidia L4
Требуемый VRAM: 24GB+
Gemma 3 12B
Рекомендуемый GPU: Nvidia L40S
Требуемый VRAM: 48GB+
Gemma 3 27B
Рекомендуемый GPU: Nvidia A100
Соображения по хранению и сети
- Хранение: хотя минимальным является SSD на 500 ГБ, для оптимальной производительности и работы с большими наборами данных рекомендуется NVMe SSD объёмом 1 ТБ или больше.
- Сеть: для облачных развёртываний и передачи больших объёмов данных рекомендуется скорость сети не менее 100 Мбит/с, чтобы избежать задержек.
Ограничения использования одного H100 для Gemma 3 27B
1. Развёртывание (инференс) на одном H100
Хотя NVIDIA H100 (80 ГБ или 96 ГБ VRAM) является GPU высшего класса, локальное развёртывание Gemma 3 27B на одной карте сопряжено с серьёзными проблемами:
- VRAM легко заполняется до предела:
Вес модели составляет около 62 ГБ. Как только вы добавите кэши инференса, временные буферы, большие размеры пакетов или длину последовательности, память быстро закончится — даже на H100. Ошибки нехватки памяти (OOM) вероятны при обработке больших входных данных или высокой степени параллелизма. - Масштабируемость ограничена:
Один GPU серьёзно ограничивает возможность увеличения размера пакетов или поддержки нескольких пользователей/запросов. - Не перспективно:
По мере роста ваших потребностей (например, более длинные входные данные, больше пользователей) одного H100 будет недостаточно.
Обучение Gemma 3 27B: одного H100 далеко не достаточно
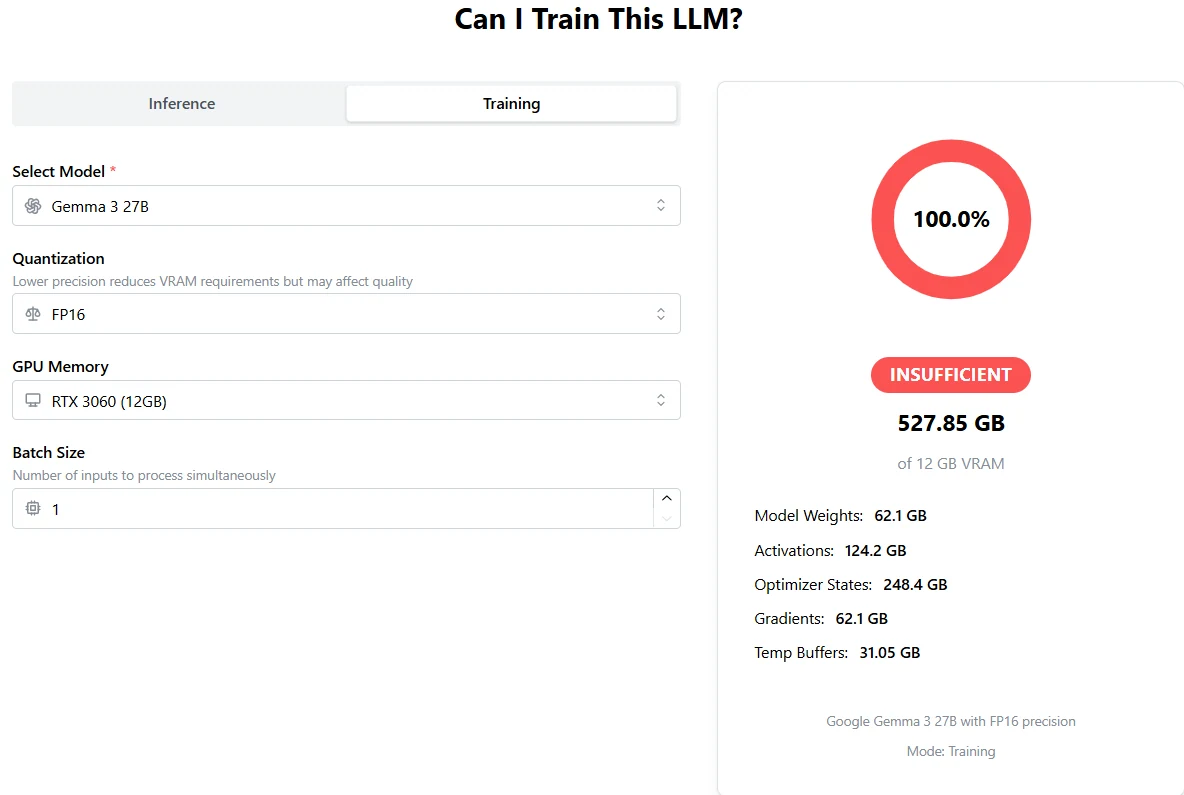
Из APX
Требуемый общий VRAM: 527,85 ГБ
Один H100 имеет только 80 ГБ (или 96 ГБ), что совершенно недостаточно.
Что произойдёт, если попробовать?
- Невозможно разместить все данные в памяти:
Для обучения требуются не только веса модели, но и активации, состояния оптимизатора, градиенты и временные буферы. Вместе они намного превышают VRAM одного H100. - Немедленные ошибки OOM:
Процесс обучения не запустится или сразу упадёт из-за недостатка памяти. - Необходимость продвинутой параллелизации:
Вам придётся использовать сложные методы распределённого обучения (модельный параллелизм, конвейерный параллелизм, ZeRO, FSDP и т.д.), и всё равно одной карты недостаточно — потребуется кластер из нескольких высокопроизводительных GPU. - Узкие места производительности:
Даже с оптимизацией памяти обучение на одной карте будет крайне медленным и непрактичным.
Более экономичный способ доступа: API
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предлагает доступное и надёжное GPU-облако для построения и масштабирования.
Шаг 1: Войдите и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library.

Попробовать демо Gemma 3 27B сейчас!
Шаг 2: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.
Шаг 3: Получите ваш API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдите на страницу «Settings», чтобы скопировать API-ключ, как показано на изображении.

Шаг 4: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования chat completions API для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Несмотря на то, что Gemma 3 27B обеспечивает производительность на уровне передовых моделей и гибкость, локальное развёртывание или обучение сопряжено со значительными аппаратными трудностями. Для большинства пользователей использование API — более доступный и экономичный способ интеграции этой мощной модели в приложения.
Часто задаваемые вопросы
Как получить доступ к Gemma 3 27B без дорогостоящего оборудования?
Использование облачного API (например, Novita AI) — самый экономичный и масштабируемый способ развёртывания Gemma 3 27B.
Является ли Gemma 3 27B мультимодальной?
Да, она поддерживает как изображения, так и текстовые входные данные.
Можно ли обучить Gemma 3 27B на одном GPU H100?
Нет, для обучения требуется более 500 ГБ VRAM. Одного H100 (80 ГБ/96 ГБ) совершенно недостаточно.
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предлагает доступное и надёжное GPU-облако для построения и масштабирования.



