

النقاط الرئيسية
Gemma 3 27B هو أحدث نموذج لغوي كبير مفتوح المصدر من Google بـ 27 مليار معلمة، تم إطلاقه في مارس 2025.
يتميز بمعمارية interleaved local-global attention المتطورة ونافذة سياق تصل إلى 128 ألف رمز.
متعدد اللغات ومتعدد الوسائط: يدعم أكثر من 140 لغة ومهام تحويل الصورة إلى نص.
يمكن الاستدلال عليه على وحدة معالجة رسومية واحدة H100، لكن التدريب يتطلب VRAM أكبر بكثير (أكثر من 500 جيجابايت).
يوفر الوصول عبر API طريقة فعالة من حيث التكلفة وقابلة للتطوير لاستخدام Gemma 3 27B دون القلق بشأن الأجهزة، مثل Novita AI.
Gemma 3 27B هو نموذج لغوي كبير مفتوح المصدر متطور من Google. بقدرات متعددة اللغات والوسائط القوية، صُمم للاستدلال المتقدم وتوليد المحتوى والاستخدام المؤسسي الواسع.
ما هو Gemma 3 27B؟
نظرة عامة على Gemma 3 27B
الميزات والابتكارات الرئيسية للنموذج الكبير مفتوح المصدر الجديد
📅معلومات أساسية
تاريخ الإصدار: 12 مارس 2025
حجم النموذج: 27 مليار معلمة
مفتوح المصدر: نعم (Google)
🧠البنية والسياق
البنية: Interleaved Local-Global Attention
نافذة السياق: حتى 128 ألف رمز (نموذج 1B: 32 ألف)
إدارة محسنة للذاكرة: زيادة نسبة الانتباه المحلي/العالمي وتقليل انفجار KV-cache يقللان كثيرًا من استهلاك الذاكرة.
سياق أطول وكفاءة في الذاكرة للمدخلات والاستدلال على نطاق واسع.
🌐متعدد اللغات والوسائط
متعدد اللغات: يدعم أكثر من 140 لغة
قدرة متعددة الوسائط: تحويل الصورة إلى نص باستخدام مشفر الرؤية SigLIP يتيح معالجة بيانات مرئية فعالة.
متعدد الوسائط: تحويل الصورة إلى نص ودعم متعدد اللغات لسيناريوهات واسعة.
⚡الأداء والتدريب
أداء محسّن: الإصدار 4B المخصص للتعليمات يطابق أداء Gemma 2 27B — أكثر كفاءة بحجم أصغر.
بيانات التدريب: 14 تريليون رمز
طرق التدريب: تقطير المعرفة (Knowledge Distillation)، التدريب المتقدم الحساس للكمية (QAT)، وRLHF.
التقطير و QAT يقللان من استخدام VRAM مع الحفاظ على الأداء القوي.
معايير Gemma 3 27B
حقق Gemma 3 27B درجة Elo مذهلة بلغت 1339 على منصة LMSys Chatbot Arena، مما يضعه ضمن أفضل 10 نماذج إلى جانب المنافسين المغلقين الرائدين مثل o3-mini. ومن الجدير بالذكر أن Gemma 3 27B يقدم هذا الأداء الاستثنائي أثناء العمل على وحدة معالجة رسومية واحدة فقط من NVIDIA H100 — وهو تناقض صارخ مع النماذج الأخرى في فئته.
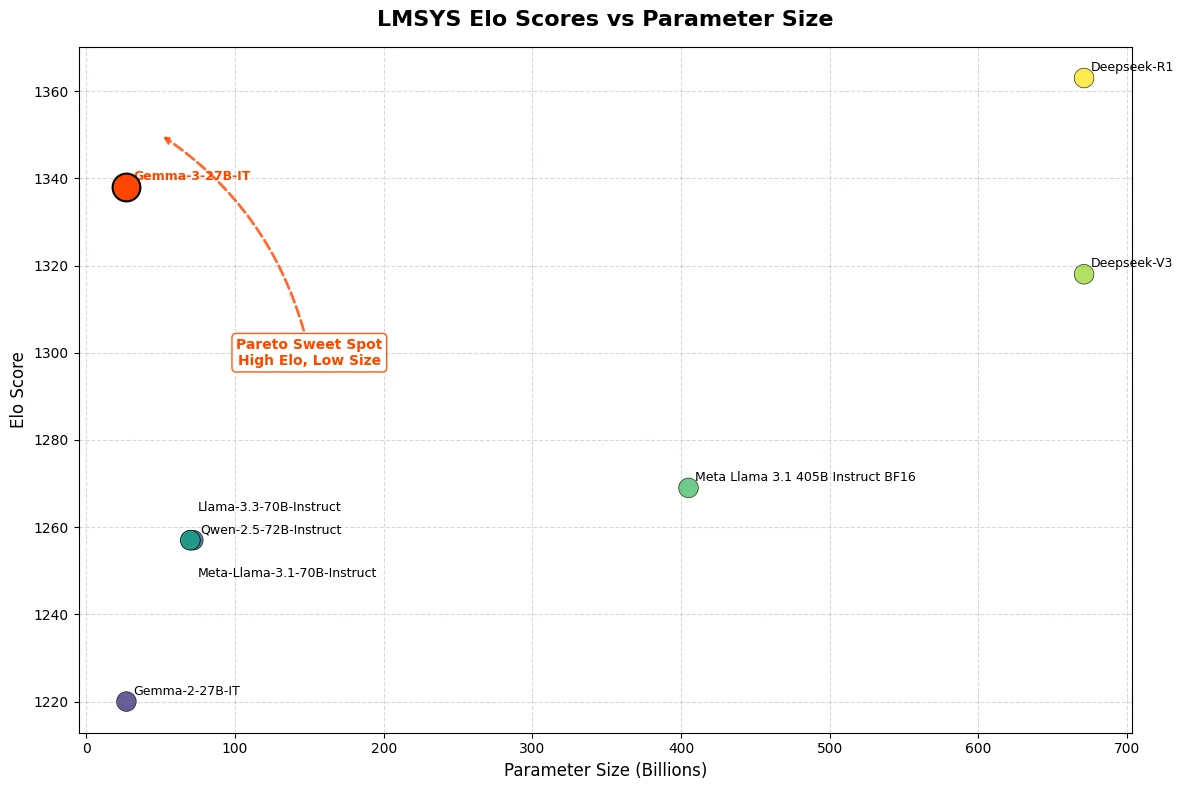
من Hugging Face
هل VRAM لوحدة H100 واحدة كافية لـ Gemma 3 27B؟
نظرة عامة على VRAM
VRAM (ذاكرة الوصول العشوائي للفيديو) هي الذاكرة المخصصة على بطاقة الرسوميات، تُستخدم لتخزين بيانات الصورة ومعلمات النموذج والأنسجة وغيرها من المعلومات المطلوبة للمهام عالية الأداء مثل التعلم العميق وعرض الرسوميات ومعالجة الفيديو.
ماذا يعني VRAM العالي حقًا؟
- دعم نماذج أكبر: يتيح تحميل وتشغيل نماذج شبكات عصبية أكبر تحتوي على معلمات أكثر أو مدخلات ذات دقة أعلى.
- معالجة دفعات أكبر: يمكن استخدام أحجام دفعات أكبر أثناء التدريب أو الاستدلال، مما يحسن الإنتاجية والكفاءة.
- تمكين مهام أكثر تعقيدًا: يتيح تشغيل مشاهد معقدة أو عرض عالي الدقة أو مهام متوازية متعددة دون مواجهة قيود الذاكرة.
- تقليل الاختناقات: يمنع التباطؤ الناجم عن نقل البيانات المتكرر بين ذاكرة النظام وذاكرة GPU، مما يؤدي إلى أداء إجمالي أفضل.
ما هي احتياجات VRAM لـ Gemma 3 27B؟
متطلبات Gemma 3 من GPU و VRAM
Gemma 3 1B
GPU موصى به: Nvidia T4
VRAM مطلوب: 16 جيجابايت+
Gemma 3 4B
GPU موصى به: Nvidia L4
VRAM مطلوب: 24 جيجابايت+
Gemma 3 12B
GPU موصى به: Nvidia L40S
VRAM مطلوب: 48 جيجابايت+
Gemma 3 27B
GPU موصى به: Nvidia A100
اعتبارات التخزين والشبكة
- التخزين: على الرغم من أن 500 جيجابايت SSD هو الحد الأدنى، إلا أنه يوصى باستخدام NVMe SSD بسعة 1 تيرابايت أو أكبر للحصول على أداء مثالي ومعالجة مجموعات البيانات الكبيرة.
- الشبكة: للنشر السحابي ونقل البيانات الكبيرة، يُنصح بسرعة شبكة لا تقل عن 100 ميجابت/ثانية لتجنب التأخير.
قيود استخدام H100 واحد لـ Gemma 3 27B
1. النشر (الاستدلال) على H100 واحد
على الرغم من أن NVIDIA H100 (80 جيجابايت أو 96 جيجابايت VRAM) هي وحدة معالجة رسومية من الدرجة الأولى، إلا أن نشر Gemma 3 27B محليًا على بطاقة واحدة يجلب تحديات كبيرة:
- يتم استنزاف VRAM بسرعة:
أوزان النموذج وحدها تبلغ حوالي 62 جيجابايت. بمجرد تضمين ذاكرة التخزين المؤقت للاستدلال والمخازن المؤقتة المؤقتة وأحجام الدفعات الأكبر أو أطوال التسلسل، ستنفد الذاكرة بسرعة — حتى على H100. من المحتمل حدوث أخطاء نفاد الذاكرة (OOM) إذا حاولت معالجة مدخلات كبيرة أو تزامن عالٍ. - قابلية التوسع محدودة:
تحد وحدة GPU واحدة بشدة من قدرتك على زيادة أحجام الدفعات أو دعم مستخدمين/طلبات متعددة. - غير قابلة للتطوير المستقبلي:
مع نمو احتياجاتك (مثل مدخلات أطول، مستخدمين أكثر)، لن تكون وحدة H100 واحدة كافية.
تدريب Gemma 3 27B: H100 واحد لا يكفي إطلاقًا
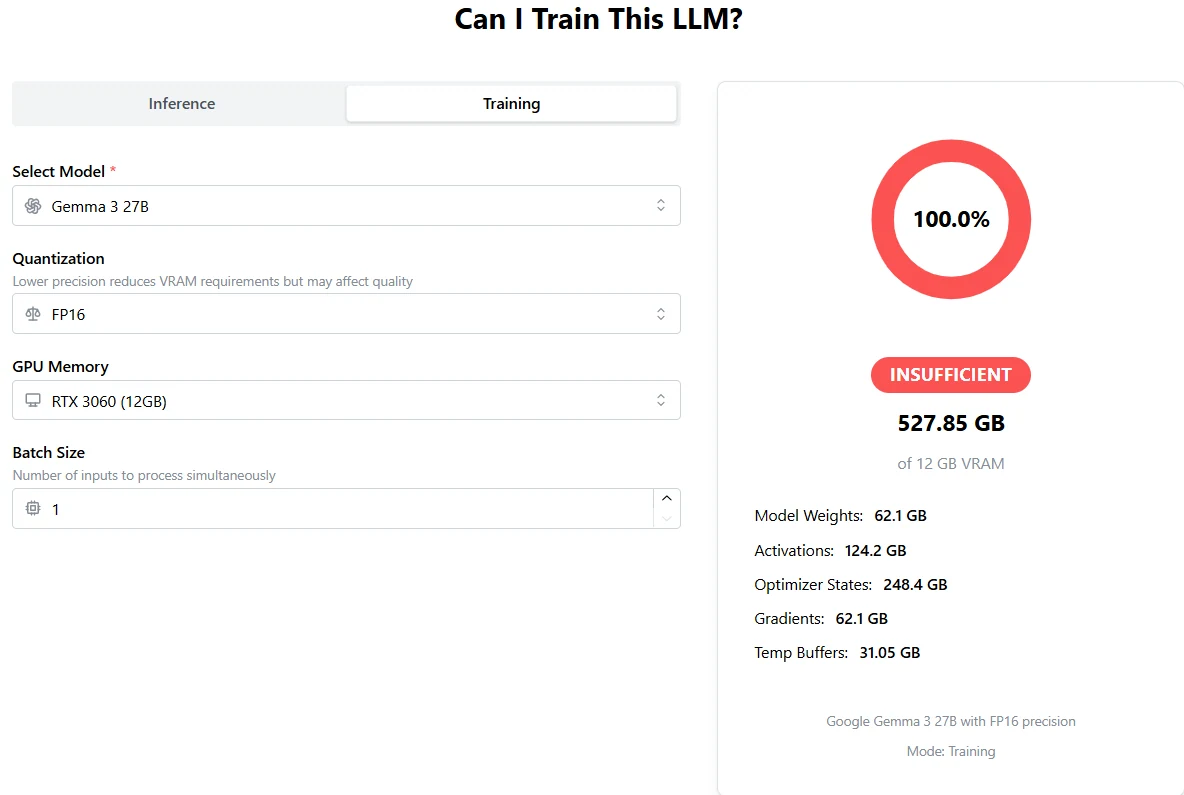
من APX
إجمالي VRAM المطلوب: 527.85 جيجابايت
توفر وحدة H100 واحدة 80 جيجابايت فقط (أو 96 جيجابايت)، وهو غير كافٍ تمامًا.
ماذا سيحدث إذا حاولت؟
- لا يمكن احتواء جميع البيانات في الذاكرة:
لا يتطلب التدريب أوزان النموذج فحسب، بل يتطلب أيضًا التنشيطات وحالات المحسن والتدرجات والمخازن المؤقتة المؤقتة. مجموع هذه يتجاوز بكثير VRAM لوحدة H100 واحدة. - أخطاء OOM فورية:
ستفشل عملية التدريب في البدء أو تتعطل فورًا بسبب عدم كفاية الذاكرة. - الحاجة إلى التوازي المتقدم:
ستضطر إلى استخدام تقنيات التدريب الموزع المعقدة (model parallelism, pipeline parallelism, ZeRO, FSDP، إلخ)، ومع ذلك، لن تعمل بطاقة واحدة — بل تحتاج إلى مجموعة من عدة وحدات GPU عالية المستوى. - اختناقات في الأداء:
حتى مع تحسينات الذاكرة، سيكون التدريب على بطاقة واحدة بطيئًا للغاية وغير عملي.
طريقة وصول أكثر فعالية من حيث التكلفة: API
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج AI باستخدام API بسيط، مع تقديم سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجّل الدخول إلى حسابك وانقر على زر Model Library.

الخطوة 2: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 3: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنوفر لك مفتاح API جديد. انتقل إلى صفحة “Settings” وانسخ مفتاح API كما هو موضح في الصورة.

الخطوة 4: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.

بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام chat completions API لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
بينما يقدم Gemma 3 27B أداءً ومرونة من الطراز الأول، إلا أن نشره أو تدريبه محليًا يأتي مع تحديات كبيرة في الأجهزة. بالنسبة لمعظم المستخدمين، يوفر استخدام API طريقة أكثر سهولة وفعالية من حيث التكلفة لدمج هذا النموذج القوي في التطبيقات.
الأسئلة المتداولة
كيف يمكنني الوصول إلى Gemma 3 27B دون أجهزة باهظة الثمن؟
استخدام API سحابي (مثل Novita AI) هو الطريقة الأكثر فعالية من حيث التكلفة وقابلية للتوسع لنشر Gemma 3 27B.
هل Gemma 3 27B متعدد الوسائط؟
نعم، يدعم إدخال الصور والنصوص.
هل يمكنني تدريب Gemma 3 27B على وحدة H100 واحدة؟
لا، يتطلب التدريب أكثر من 500 جيجابايت من VRAM. وحدة H100 واحدة (80/96 جيجابايت) غير كافية إطلاقًا.
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج AI باستخدام API بسيط، مع تقديم سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.



