

Wichtige Erkenntnisse
Gemma 3 27B ist Googles neuestes Open-Source-Sprachmodell mit 27 Milliarden Parametern, veröffentlicht im März 2025.
Es verfügt über eine fortschrittliche verschränkte lokale-globale Aufmerksamkeitsarchitektur und einen Kontextfenster von bis zu 128K Token.
Mehrsprachig und multimodal: Unterstützt über 140 Sprachen und Bild-zu-Text-Aufgaben.
Inferenz auf einer einzelnen H100-GPU möglich, aber Training erfordert weit mehr VRAM (über 500 GB).
Der API-Zugriff bietet eine kosteneffiziente, skalierbare Möglichkeit, Gemma 3 27B ohne Hardwarebedenken zu nutzen, wie bei Novita AI.
Gemma 3 27B ist ein hochmodernes Open-Source-Sprachmodell von Google. Mit leistungsstarken mehrsprachigen und multimodalen Funktionen ist es für fortgeschrittenes Reasoning, Inhaltserstellung und breite Unternehmensanwendungen konzipiert.
Was ist Gemma 3 27B?
Gemma 3 27B – Übersicht
Wichtige Funktionen und Neuerungen des neuesten Open-Source-Großmodells
📅 Basisinformationen
Veröffentlichungsdatum: 12. März 2025
Modellgröße: 27B Parameter
Open Source: Ja (Google)
🧠Architektur & Kontext
Architektur: Verschränkte lokale-globale Aufmerksamkeit (Interleaved Local-Global Attention)
Kontextfenster: Bis zu 128K Token (1B-Modell: 32K)
Optimiertes Speichermanagement: Erhöhtes lokales/globales Aufmerksamkeitsverhältnis und minimierte KV-Cache-Explosion reduzieren den Speicher-Overhead erheblich.
Längerer Kontext und Speichereffizienz für umfangreiche Eingaben und Inferenz.
🌐Multimodal & Sprachen
Mehrsprachigkeit: Unterstützt über 140 Sprachen
Multimodale Fähigkeit: Bild-zu-Text mit SigLIP-Vision-Encoder ermöglicht effiziente Verarbeitung visueller Daten.
Multimodal: Bild-zu-Text und mehrsprachige Unterstützung für vielfältige Szenarien.
⚡Leistung & Training
Verbesserte Leistung: Die 4B-anweisungsoptimierte Version erreicht die Leistung von Gemma 2 27B – effizienter bei kleinerer Skalierung.
Trainingsdaten: 14 Billionen Token
Trainingsmethoden: Knowledge Distillation, erweitertes quantisierungsbewusstes Training (QAT) und RLHF.
Distillation und QAT reduzieren den VRAM-Bedarf bei gleichbleibend starker Leistung.
Benchmarks von Gemma 3 27B
Gemma 3 27B hat im LMSys Chatbot Arena einen beeindruckenden Elo-Wert von 1339 erreicht und gehört damit zu den Top-10-Modellen neben führenden Closed-Source-Konkurrenten wie o3-mini. Bemerkenswert ist, dass Gemma 3 27B diese außergewöhnliche Leistung auf nur einer einzelnen NVIDIA H100-GPU erbringt – ein deutlicher Kontrast zu anderen Modellen seiner Klasse.
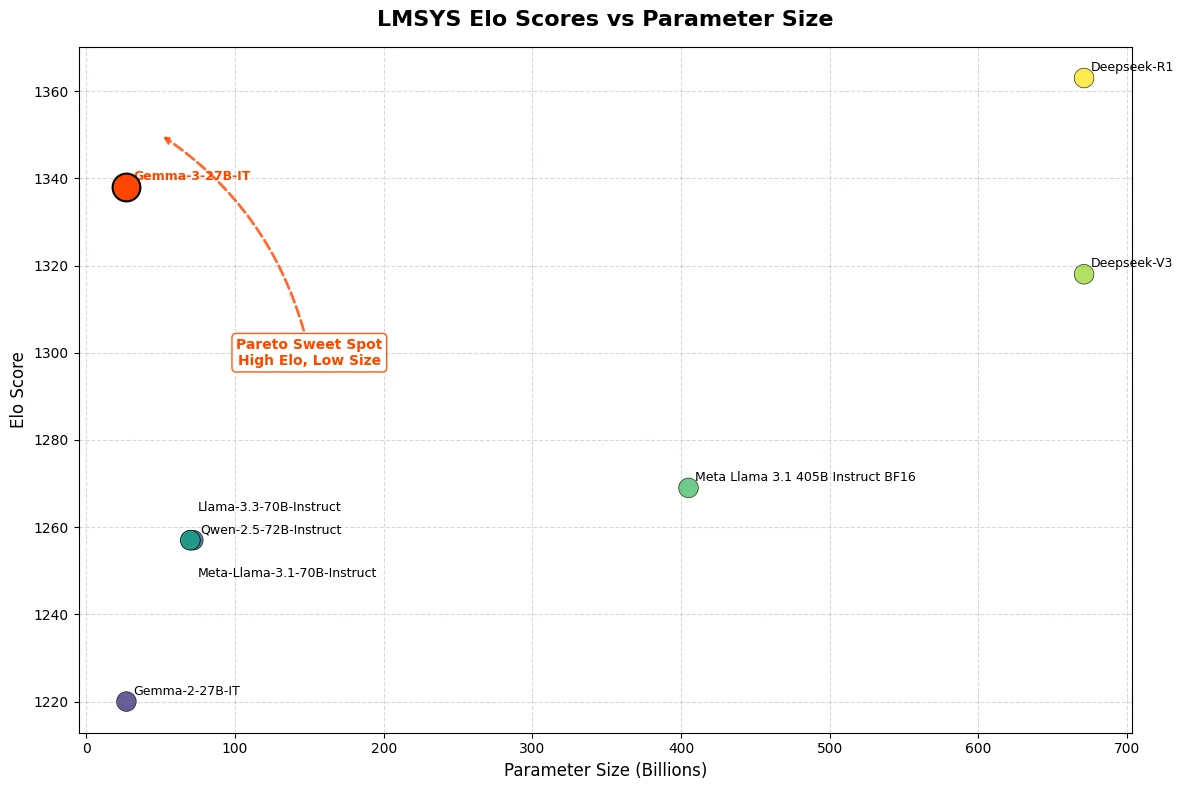
Von Hugging Face
Reicht der VRAM einer einzelnen H100 für Gemma 3 27B aus?
VRAM-Übersicht
VRAM (Video Random Access Memory) ist der dedizierte Speicher auf einer Grafikkarte, der Bilddaten, Modellparameter, Texturen und andere Informationen speichert, die für rechenintensive Aufgaben wie Deep Learning, Grafikrendering und Videoverarbeitung benötigt werden.
Was bedeutet hoher VRAM wirklich?
- Unterstützt größere Modelle: Ermöglicht das Laden und Ausführen größerer neuronaler Netzwerkmodelle mit mehr Parametern oder höher auflösenden Eingaben.
- Verarbeitet größere Batch-Größen: Ermöglicht die Verwendung größerer Batch-Größen während des Trainings oder der Inferenz, was den Durchsatz und die Effizienz verbessert.
- Ermöglicht komplexere Aufgaben: Macht es möglich, komplexe Szenen, hochauflösendes Rendering oder mehrere parallele Aufgaben auszuführen, ohne auf Speicherbeschränkungen zu stoßen.
- Reduziert Engpässe: Verhindert Verlangsamungen durch häufige Datenübertragungen zwischen Systemspeicher und GPU-Speicher, was zu einer besseren Gesamtleistung führt.
Wie hoch ist der VRAM-Bedarf von Gemma 3 27B?
Gemma 3 GPU- und VRAM-Anforderungen
Gemma 3 1B
Empfohlene GPU: Nvidia T4
Erforderlicher VRAM: 16GB+
Gemma 3 4B
Empfohlene GPU: Nvidia L4
Erforderlicher VRAM: 24GB+
Gemma 3 12B
Empfohlene GPU: Nvidia L40S
Erforderlicher VRAM: 48GB+
Gemma 3 27B
Empfohlene GPU: Nvidia A100
Speicher- und Netzwerküberlegungen
- Speicher: Während eine 500-GB-SSD das Minimum darstellt, wird eine 1-TB- oder größere NVMe-SSD für optimale Leistung und Handhabung großer Datensätze empfohlen.
- Netzwerk: Für Cloud-Bereitstellungen und große Datenübertragungen wird eine Netzwerkgeschwindigkeit von mindestens 100 Mbps empfohlen, um Verzögerungen zu vermeiden.
Einschränkungen bei der Verwendung einer einzelnen H100 für Gemma 3 27B
1. Bereitstellung (Inferenz) auf einer einzelnen H100
Obwohl die NVIDIA H100 (80 GB oder 96 GB VRAM) eine High-End-GPU ist, bringt die lokale Bereitstellung von Gemma 3 27B auf einer einzelnen Karte erhebliche Herausforderungen mit sich:
- VRAM ist schnell ausgelastet:
Die Modellgewichte allein liegen bei etwa 62 GB. Sobald Inferenz-Caches, temporäre Puffer und größere Batch-Größen oder Sequenzlängen hinzukommen, ist der Speicher selbst auf einer H100 schnell erschöpft. Out-of-Memory-Fehler (OOM) sind wahrscheinlich, wenn Sie versuchen, große Eingaben oder eine hohe Parallelität zu verarbeiten. - Skalierbarkeit ist begrenzt:
Eine einzelne GPU schränkt die Fähigkeit, Batch-Größen zu skalieren oder mehrere Benutzer/Anfragen zu bedienen, stark ein. - Nicht zukunftssicher:
Wenn Ihre Anforderungen wachsen (z. B. längere Eingaben, mehr Benutzer), wird eine einzelne H100 nicht ausreichen.
Training von Gemma 3 27B: Eine H100 ist bei weitem nicht genug
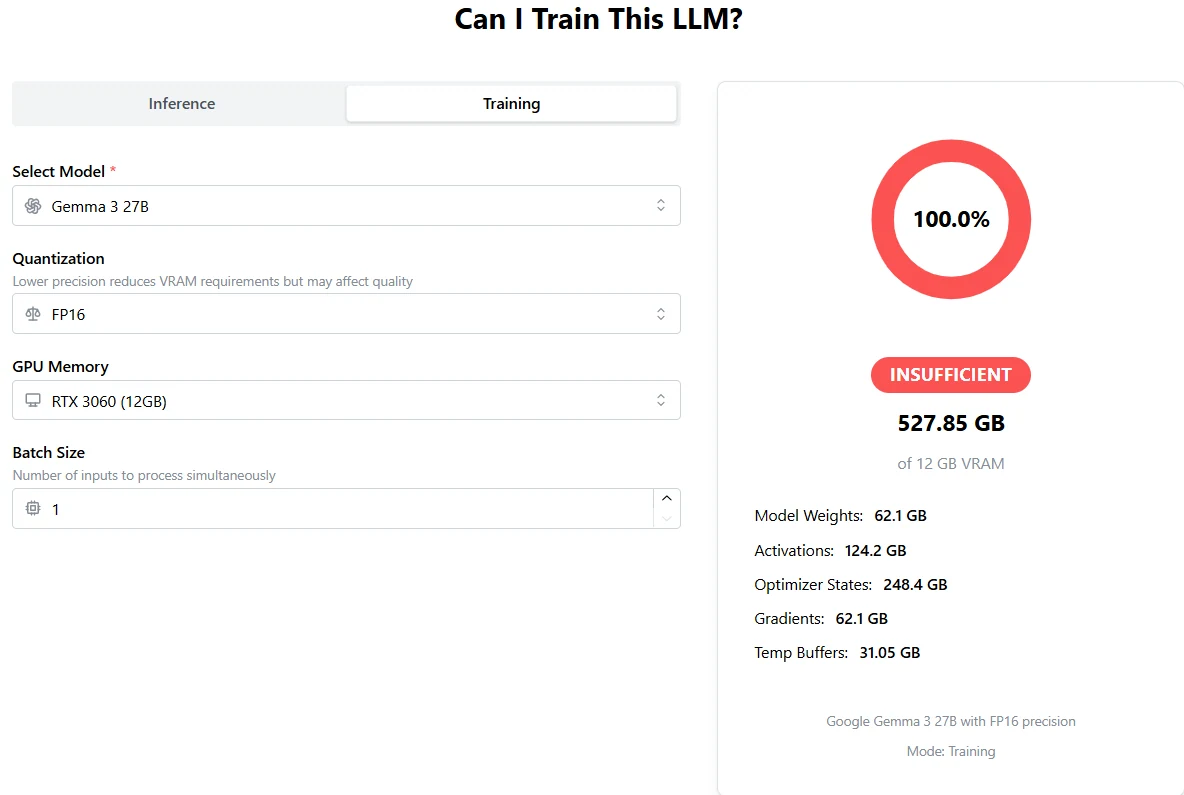
Von APX
Erforderlicher Gesamt-VRAM: 527,85 GB
Eine einzelne H100 bietet nur 80 GB (oder 96 GB) – das ist bei weitem nicht ausreichend.
Was passiert, wenn Sie es versuchen?
- Alle Daten passen nicht in den Speicher:
Training erfordert nicht nur die Modellgewichte, sondern auch Aktivierungen, Optimierungszustände, Gradienten und temporäre Puffer. Zusammen überschreiten diese den VRAM einer einzelnen H100 bei weitem. - Sofortige OOM-Fehler:
Der Trainingsprozess wird nicht starten oder sofort abstürzen, da der Speicher nicht ausreicht. - Bedarf an fortgeschrittener Parallelisierung:
Sie wären gezwungen, komplexe verteilte Trainingstechniken (Modellparallelismus, Pipeline-Parallelismus, ZeRO, FSDP usw.) einzusetzen, und selbst dann würde eine einzelne Karte nicht ausreichen – Sie benötigen einen Cluster mit mehreren High-End-GPUs. - Leistungsengpässe:
Selbst mit Speicheroptimierungen wäre das Training auf einer einzelnen Karte extrem langsam und unpraktisch.
Eine kostengünstigere Zugangsmethode: API
Novita AI ist eine AI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Jetzt Gemma 3 27B Demo testen!
Schritt 2: Kostenlose Testversion starten
Starten Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 3: API-Schlüssel abrufen
Um sich bei der API zu authentifizieren, erhalten Sie einen neuen API-Schlüssel. Rufen Sie die Seite Einstellungen auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 4: API installieren
Installieren Sie die API mit dem Paketmanager Ihrer Programmiersprache.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "google/gemma-3-27b-it"
stream = True # oder False
max_tokens = 2048
system_content = """Seien Sie ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Während Gemma 3 27B hochmoderne Leistung und Flexibilität bietet, bringt die lokale Bereitstellung oder das Training erhebliche Hardware-Herausforderungen mit sich. Für die meisten Benutzer bietet die Nutzung einer API einen zugänglicheren und kosteneffizienteren Weg, dieses leistungsstarke Modell in Anwendungen zu integrieren.
Häufig gestellte Fragen
Wie kann ich ohne teure Hardware auf Gemma 3 27B zugreifen?
Die Verwendung einer Cloud-API (wie Novita AI) ist der kostengünstigste und skalierbarste Weg, Gemma 3 27B bereitzustellen.
Ist Gemma 3 27B multimodal?
Ja, es unterstützt sowohl Bild- als auch Texteingaben.
Kann ich Gemma 3 27B auf einer einzelnen H100-GPU trainieren?
Nein, das Training erfordert über 500 GB VRAM. Eine H100 (80 GB/96 GB) ist bei weitem nicht ausreichend.
Novita AI ist eine AI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



