

Key Highlights
Gemma 3 27B is Google’s latest open-source large language model with 27 billion parameters, released in March 2025.
Features an advanced interleaved local-global attention architecture and a context window up to 128K tokens.
Multilingual and multimodal: supports 140+ languages and image-to-text tasks.
Inference possible on a single H100 GPU, but training requires far more VRAM (over 500GB).
API access provides a cost-effective, scalable way to use Gemma 3 27B without hardware concerns, like Novita AI.
Gemma 3 27B is a cutting-edge open-source large language model developed by Google. With powerful multilingual and multimodal capabilities, it is designed for advanced reasoning, content generation, and broad enterprise use.
What is Gemma 3 27B?
Gemma 3 27B Overview
Key features and innovations of the latest open-source large model
📅Basic Info
Release Date: March 12, 2025
Model Size: 27B parameters
Open Source: Yes (Google)
🧠Architecture & Context
Architecture: Interleaved Local-Global Attention
Context Window: Up to 128K tokens (1B model: 32K)
Optimized Memory Management: Increased local/global attention ratio and minimized KV-cache explosion greatly reduce memory overhead.
Longer context and memory efficiency for large-scale input and inference.
🌐Multimodal & Language
Multilingual: Supports 140+ languages
Multimodal Capability: Image-to-text with SigLIP vision encoder enables efficient visual data processing.
Multimodal: Image-to-text and multilingual support for broad scenarios.
⚡Performance & Training
Improved Performance: 4B instruction-tuned version matches Gemma 2 27B’s performance—more efficient at smaller scale.
Training Data: 14 trillion tokens
Training Methods: Knowledge Distillation, Advanced Quantization-Aware Training (QAT), and RLHF.
Distillation and QAT reduce VRAM usage while maintaining strong performance.
Gemma 3 27B Benchmark
Gemma 3 27B has achieved an impressive Elo score of 1339 on the LMSys Chatbot Arena, ranking it among the top 10 models alongside leading closed-source competitors like o3-mini. Notably, Gemma 3 27B delivers this exceptional performance while running on just a single NVIDIA H100 GPU—a stark contrast to other models in its class.
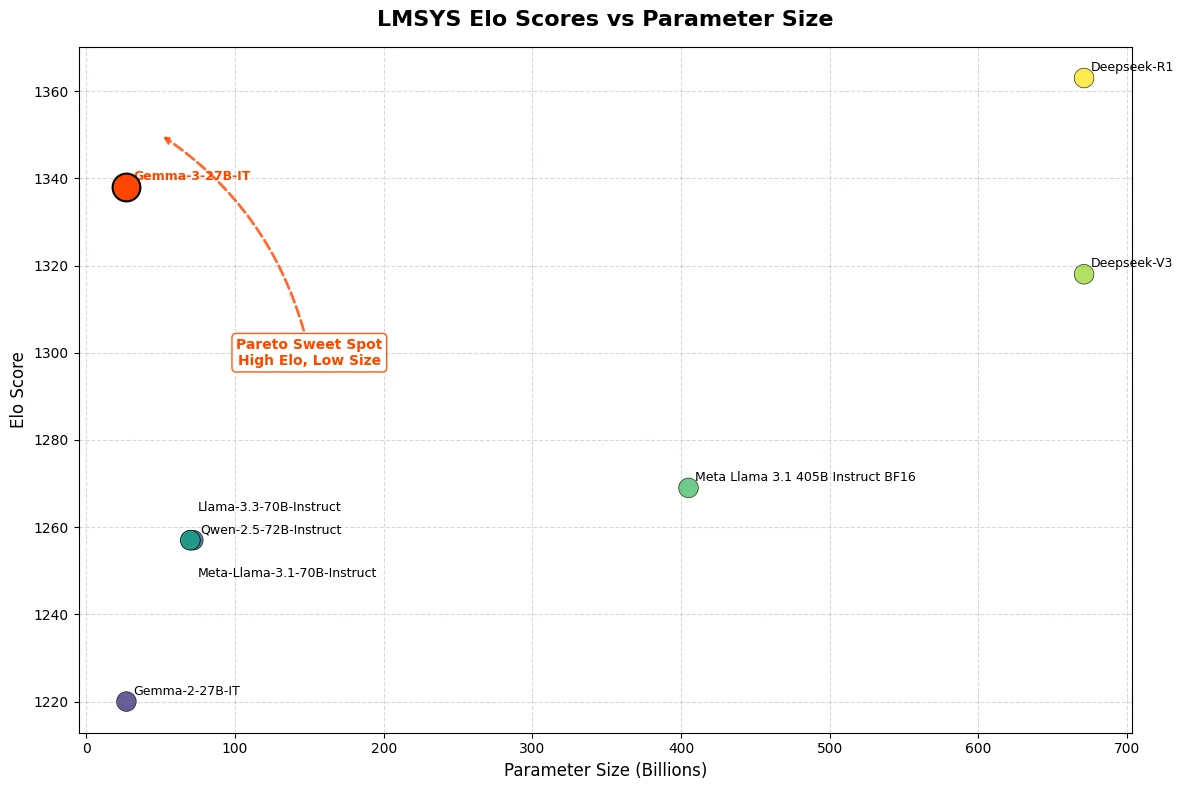
From Hugging Face
Is the VRAM of a Single H100 Sufficient for Gemma 3 27B?
VRAM Overview
VRAM (Video Random Access Memory) is the dedicated memory on a graphics card used to store image data, model parameters, textures, and other information required for high-performance tasks such as deep learning, graphics rendering, and video processing.
What Does High VRAM Really Mean?
- Supports Larger Models: Allows you to load and run larger neural network models with more parameters or higher resolution inputs.
- Handles Bigger Batch Sizes: Enables the use of larger batch sizes during training or inference, improving throughput and efficiency.
- Enables More Complex Tasks: Makes it possible to run complex scenes, high-definition rendering, or multiple parallel tasks without running into memory constraints.
- Reduces Bottlenecks: Prevents slowdowns caused by frequent data transfers between system memory and GPU memory, resulting in better overall performance.
What Are the VRAM Needs of Gemma 3 27B?
Gemma 3 GPU & VRAM Requirements
Gemma 3 1B
Recommended GPU: Nvidia T4
VRAM Required: 16GB+
Gemma 3 4B
Recommended GPU: Nvidia L4
VRAM Required: 24GB+
Gemma 3 12B
Recommended GPU: Nvidia L40S
VRAM Required: 48GB+
Gemma 3 27B
Recommended GPU: Nvidia A100
Storage and Network Considerations
- Storage: While 500GB SSD is a minimum, a 1TB or larger NVMe SSD is recommended for optimal performance and handling large datasets.
- Network: For cloud deployments and large data transfers, at least 100 Mbps network speed is advised to avoid delays.
Limitations of Using One H100 for Gemma 3 27B
1. Deployment (Inference) on a Single H100
While the NVIDIA H100 (80GB or 96GB VRAM) is a top-tier GPU, deploying Gemma 3 27B locally on a single card brings significant challenges:
- VRAM is easily maxed out:
The model weights alone are around 62GB. Once you include inference caches, temporary buffers, and larger batch sizes or sequence lengths, you will quickly run out of memory—even on an H100. Out-of-memory (OOM) errors are likely if you try to process large inputs or high concurrency. - Scalability is limited:
A single GPU severely limits your ability to scale up batch sizes or support multiple users/requests. - Not future-proof:
As your needs grow (e.g., longer inputs, more users), a single H100 will not suffice.
Training Gemma 3 27B: One H100 Is Far from Enough
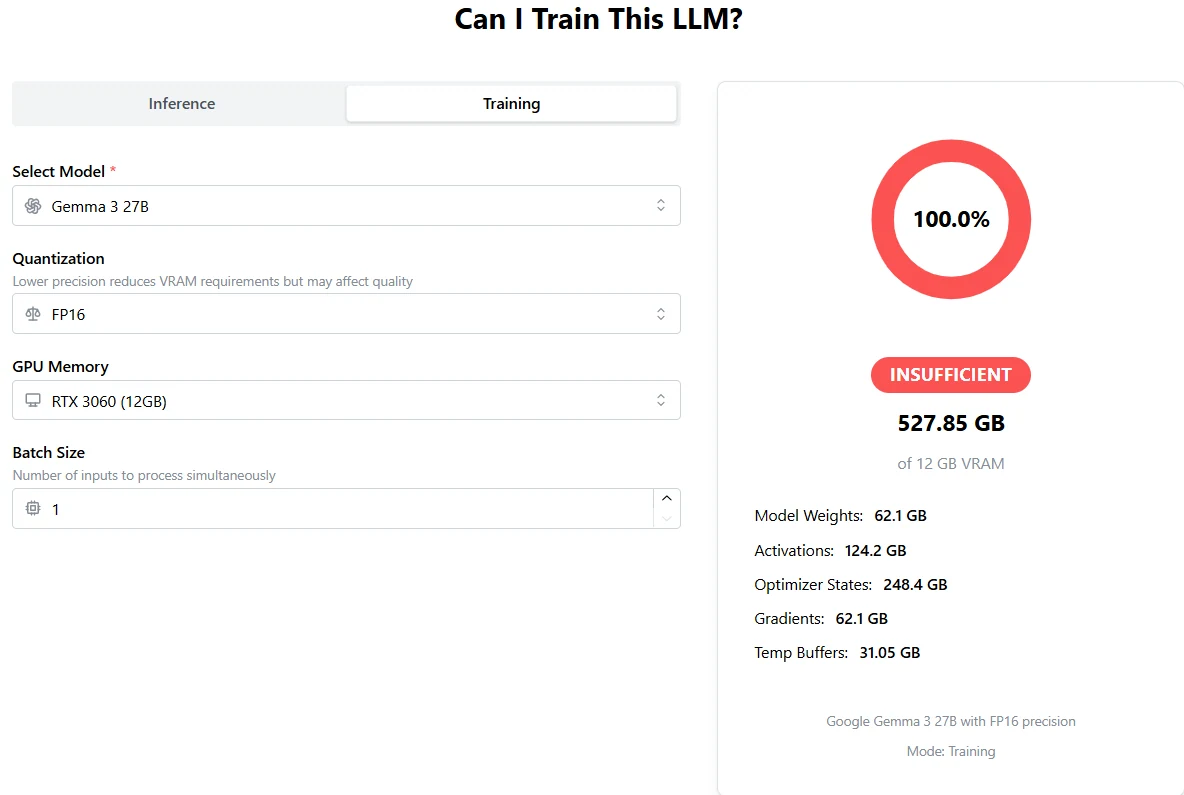
From APX
Total VRAM required: 527.85 GB
A single H100 offers only 80GB (or 96GB), which is not nearly enough.
What will happen if you try?
- Cannot fit all data in memory:
Training requires not just the model weights, but also activations, optimizer states, gradients, and temporary buffers. These combined far exceed the VRAM of a single H100. - Immediate OOM errors:
The training process will fail to start or crash right away due to insufficient memory. - Need for advanced parallelization:
You’d be forced to use complex distributed training techniques (model parallelism, pipeline parallelism, ZeRO, FSDP, etc.), and still, a single card won’t work—you need a cluster with several high-end GPUs. - Performance bottlenecks:
Even with memory optimizations, training on a single card would be extremely slow and impractical.
A More Cost-Effective Access Method: API
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 3: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 4: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)While Gemma 3 27B delivers state-of-the-art performance and flexibility, deploying or training it locally comes with significant hardware challenges. For most users, leveraging an API offers a more accessible and cost-effective way to integrate this powerful model into applications.
Frequently Asked Questions
How can I access Gemma 3 27B without expensive hardware?
Using a cloud API (like Novita AI) is the most cost-effective and scalable way to deploy Gemma 3 27B.
Is Gemma 3 27B multimodal?
Yes, it supports both image and text inputs.
Can I train Gemma 3 27B on a single H100 GPU?
No, training requires over 500GB of VRAM. One H100 (80GB/96GB) is far from sufficient.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



