

Points clés
Deepseek V3 0324 excelle dans le traitement multilingue, avec des capacités accrues pour la langue chinoise, comprenant 671B paramètres et une architecture de pointe Mixture-of-Experts (MoE).
Déploiement local : Performances élevées mais nécessite un investissement initial de 600 000 $ et une infrastructure étendue.
Accès via API : Rentable, évolutif et optimisé par le fournisseur avec une tarification à l’utilisation. Comme Novita AI, elle propose 0,33 $/1M tokens d’entrée et 1,3 $/1M tokens de sortie.
Deepseek V3 0324 est un modèle Mixture-of-Experts (MoE) de pointe conçu pour redéfinir le traitement intelligent avec 671B paramètres. Publié le 24 mars 2025, il offre des capacités multilingues inégalées, excellant particulièrement dans le traitement de la langue chinoise. Alors que le déploiement local offre un contrôle total, l’accès via API via Novita AI garantit rentabilité, évolutivité et fiabilité de niveau entreprise.
Qu’est-ce que Deepseek V3 0324 ?

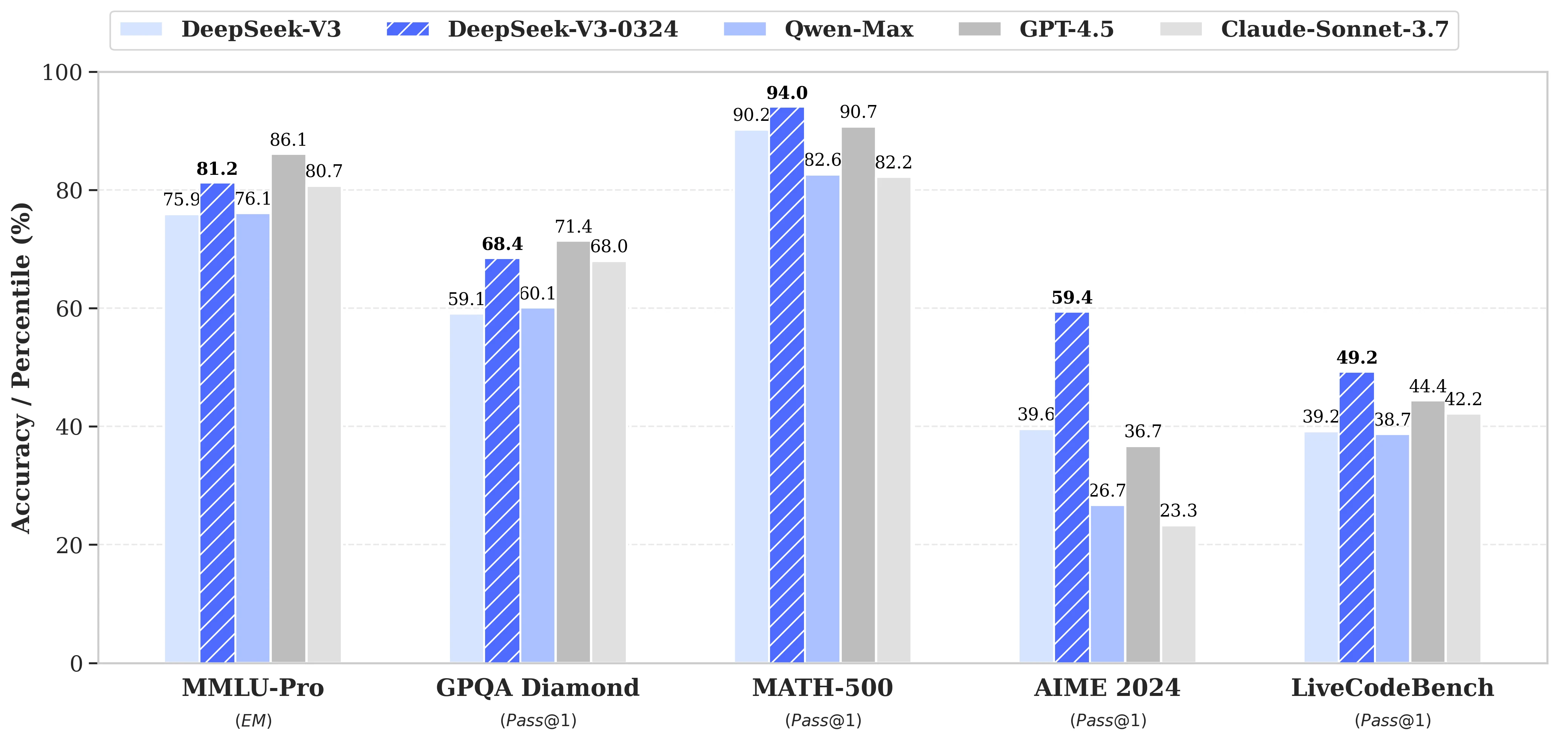
Benchmark de Deepseek V3 0324
Qu’est-ce que la VRAM ?
La VRAM (Video Random Access Memory) est un type de mémoire spécialisée utilisée par le GPU (Graphics Processing Unit) d’un ordinateur. Elle stocke et traite des données graphiques telles que les textures, les modèles 3D, les shaders et les tampons d’images. La VRAM est essentielle pour le rendu d’images, de vidéos et de graphismes dans les jeux, la modélisation 3D, le montage vidéo et d’autres applications visuelles.
https://www.youtube.com/watch?v=e4GCxObZrZE
Que signifie la VRAM pour l’accès aux LLM ?
Problèmes et solutions liés à la VRAM pour les LLM
| Problème | Solution |
|---|---|
| 📦Stockage du modèle dans la VRAM Les grands modèles comme GPT-4 nécessitent plusieurs Go de VRAM pour stocker les poids, les paramètres et les calculs. Si la taille du modèle dépasse la VRAM, il risque de ne pas fonctionner efficacement, voire pas du tout. | ✔️ Utiliser des modèles plus petits ou optimisés. ✔️ Décharger des parties du modèle vers la RAM système ou le disque. ✔️ Utiliser des GPU avec plus de VRAM ou des services cloud. |
| 📊Traitement par lots La taille du lot détermine combien d’entrées peuvent être traitées simultanément. Une VRAM limitée restreint la taille du lot, réduisant le débit et augmentant la latence. | ✔️ Réduire la taille du lot pour respecter les limites de VRAM. ✔️ Utiliser plusieurs lots plus petits. ✔️ Passer à des GPU avec plus de VRAM. |
| ⚙️Optimisation du modèle Une VRAM limitée peut provoquer une inefficacité ou empêcher totalement l’exécution du modèle. | ✔️ Utiliser la quantification du modèle (par ex., de 32 bits à 16 bits). ✔️ Décharger les calculs vers la RAM ou le disque. ✔️ Utiliser l’élagage pour supprimer les paramètres inutiles. |
| 🧠Inférence vs. Entraînement L’inférence nécessite moins de VRAM (par ex., 8 Go+ pour les grands modèles), mais l’entraînement en demande significativement plus (par ex., 16–24 Go+), selon le modèle et le jeu de données. | ✔️ Utiliser des modèles plus petits ou optimisés pour l’inférence. ✔️ Utiliser des services cloud ou un entraînement distribué pour les grands modèles. ✔️ Optimiser les stratégies de chargement et de stockage des données. |
Exigences VRAM de Deepseek V3 0324
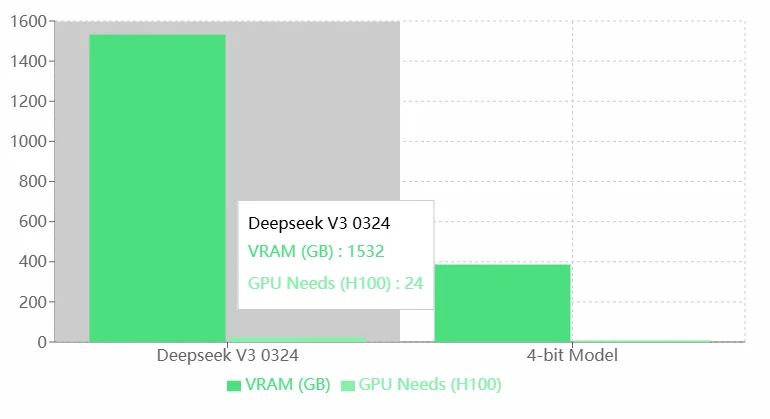
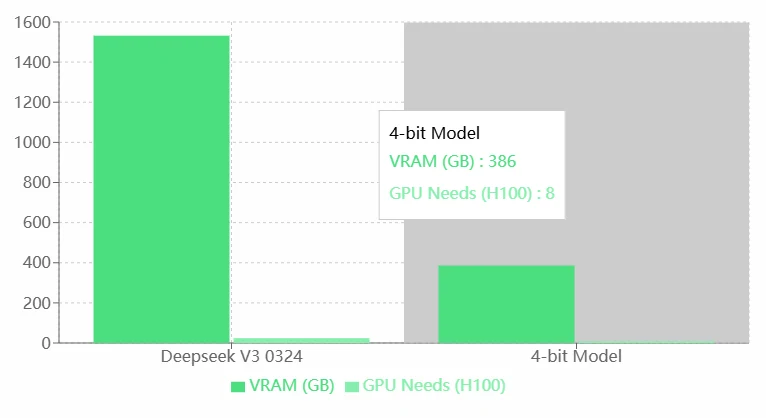
Avantages :
- Performances élevées : Les exigences élevées en VRAM et GPU de Deepseek V3 0324 indiquent probablement ses capacités supérieures, lui permettant de gérer des tâches plus complexes ou d’exécuter des modèles plus précis.
- Adapté au matériel haut de gamme : Il peut tirer parti des GPU H100 hautes performances, ce qui le rend idéal pour des applications au niveau entreprise ou recherche.
Inconvénients :
- Consommation de ressources élevée : Les besoins extrêmement élevés en VRAM et GPU augmentent considérablement la dépendance aux ressources matérielles, ce qui peut entraîner des coûts d’exploitation plus élevés.
- Applicabilité limitée : Pour les individus ou les petites équipes disposant de ressources limitées, exécuter Deepseek V3 0324 peut ne pas être réalisable.
- Manque d’optimisation : Comparé au modèle en 4 bits, Deepseek V3 0324 semble avoir une efficacité d’utilisation des ressources inférieure. L’optimisation du modèle (par ex., quantification ou élagage) est recommandée.
Déploiement local de Deepseek V3 0324 vs accès via API
| Aspect | Déploiement local | Accès via API |
|---|---|---|
| Investissement initial | 600 000 $+ (24 GPU H100) | 0,33 $ / 1M tokens d’entrée / 1.3 $ / 1M tokens de sortie |
| Infrastructure | Étendue (GPU, refroidissement, alimentation) | Aucune requise |
| Expertise technique | Équipes ML/DevOps nécessaires | Connaissances de base en API |
| Maintenance | Entretien continu du système | Aucune requise |
| Évolutivité | Limitée par le matériel | Immédiate et flexible |
| Fiabilité | Dépend de la configuration locale | SLA de niveau entreprise |
| Performances | Dépendantes du matériel | Optimisées par le fournisseur |
| Confidentialité des données | Contrôle total | Dépend du fournisseur |
Novita AI : une solution API fiable et économique
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Deepseek V3 0324 maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Lancez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Entrez dans la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-v3-0324"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Deepseek V3 0324 associe une technologie de pointe à des options de déploiement flexibles, répondant à des besoins variés. Que vous exploitiez un contrôle local ou un accès API économique, ce modèle offre aux utilisateurs des capacités avancées d’appel de fonctions et multilingues. Pour une intégration fluide, l’API de Novita AI constitue un point d’entrée accessible avec des barrières techniques minimales.
Questions fréquentes
Est-ce que Deepseek V3 0324 prend en charge les entrées multimodales ?
Non, Deepseek V3 0324 est conçu uniquement pour le traitement texte-texte.
Comment commencer à utiliser Deepseek V3 0324 ?
Connectez-vous simplement à Novita AI, sélectionnez votre modèle, lancez l’essai gratuit et récupérez votre clé API pour commencer l’intégration.
Quel type d’infrastructure est requis pour un déploiement local de Deepseek V3 0324 ?
Le déploiement local nécessite 24 GPU H100, un refroidissement étendu et une maintenance continue, avec un coût initial de 600 000 $+.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en proposant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



