

Puntos clave
Deepseek V3 0324 sobresale en procesamiento multilingüe, con capacidades mejoradas en idioma chino, cuenta con 671B parámetros y una arquitectura de vanguardia Mixture-of-Experts (MoE).
Implementación local: Alto rendimiento pero requiere $600,000+ de inversión inicial y una infraestructura extensa.
Acceso por API: Rentable, escalable y optimizado por el proveedor con pago por uso. Como Novita AI, ofrece $0.33/1M tokens de entrada y $1.3/1M tokens de salida.
Deepseek V3 0324 es un modelo de última generación Mixture-of-Experts (MoE) diseñado para redefinir el procesamiento inteligente con 671B parámetros. Lanzado el 24 de marzo de 2025, ofrece capacidades multilingües inigualables, destacando especialmente en el procesamiento del idioma chino. Mientras que la implementación local brinda control total, el acceso por API a través de Novita AI garantiza rentabilidad, escalabilidad y fiabilidad de nivel empresarial.
¿Qué es Deepseek V3 0324?

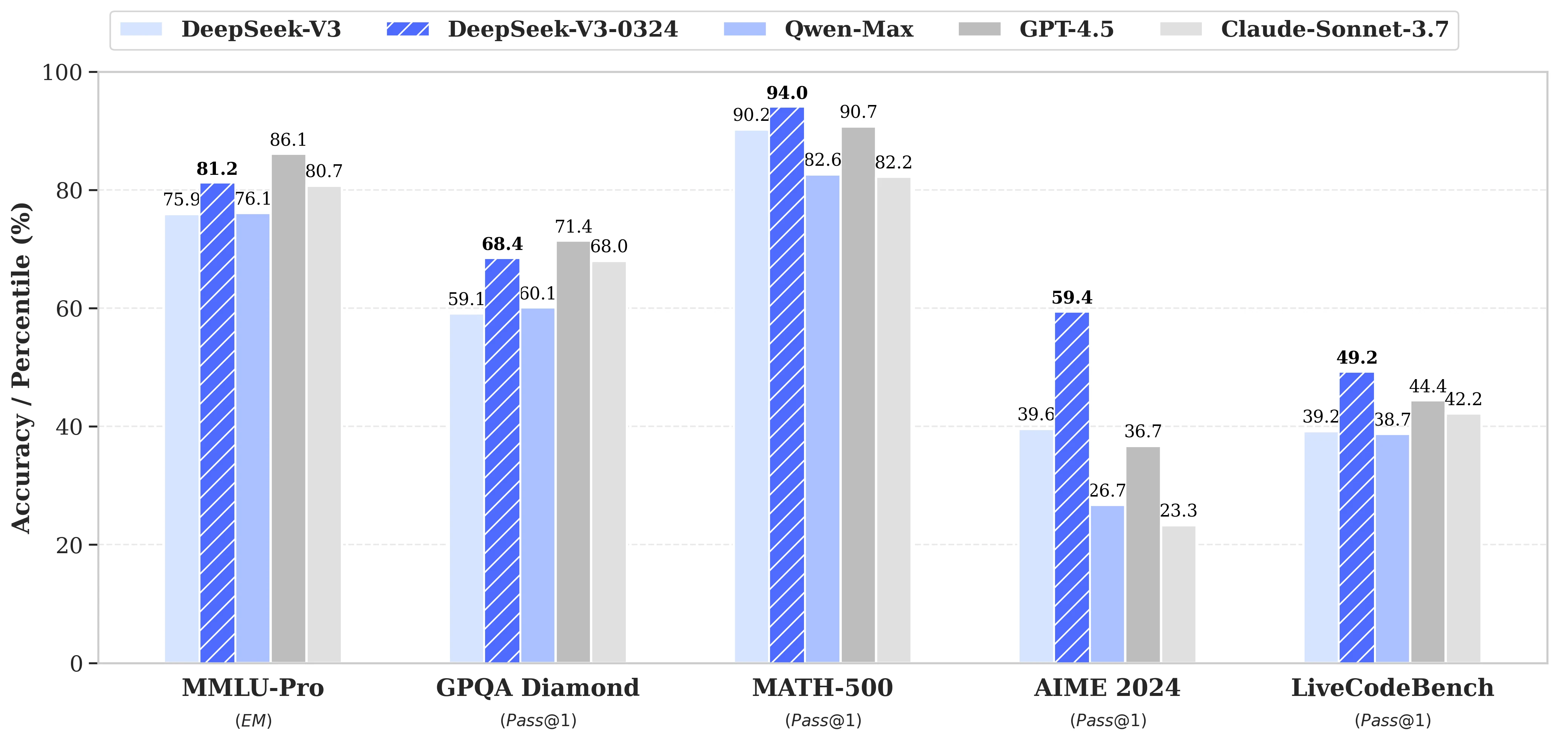
Benchmark de Deepseek V3 0324
¿Qué es VRAM?
VRAM (Video Random Access Memory) es un tipo de memoria especializada utilizada por la GPU (Unidad de Procesamiento Gráfico) de una computadora. Almacena y procesa datos gráficos como texturas, modelos 3D, shaders y framebuffers. La VRAM es esencial para renderizar imágenes, videos y gráficos en juegos, modelado 3D, edición de video y otras aplicaciones visuales.
https://www.youtube.com/watch?v=e4GCxObZrZE
¿Qué significa VRAM para el acceso a LLMs?
Problemas de VRAM y soluciones para LLMs
| Problema | Solución |
|---|---|
| 📦Almacenamiento del modelo en VRAM Modelos grandes como GPT-4 requieren varios GB de VRAM para almacenar pesos, parámetros y cálculos. Si el tamaño del modelo excede la VRAM, puede no funcionar de manera eficiente o simplemente no funcionar. | ✔️ Usar modelos más pequeños u optimizados. ✔️ Descargar partes del modelo a la RAM del sistema o al disco. ✔️ Usar GPUs con mayor VRAM o servicios en la nube. |
| 📊Procesamiento por lotes El tamaño del lote determina cuántas entradas pueden procesarse simultáneamente. La VRAM limitada restringe el tamaño del lote, reduciendo el rendimiento y aumentando la latencia. | ✔️ Reducir el tamaño del lote para ajustarse a los límites de VRAM. ✔️ Usar múltiples lotes más pequeños. ✔️ Actualizar a GPUs con mayor VRAM. |
| ⚙️Optimización del modelo La VRAM limitada puede causar ineficiencia o impedir que el modelo funcione por completo. | ✔️ Usar cuantización del modelo (por ejemplo, de 32 bits a 16 bits). ✔️ Descargar cálculos a RAM o disco. ✔️ Usar poda para eliminar parámetros innecesarios. |
| 🧠Inferencia vs. Entrenamiento La inferencia requiere menos VRAM (por ejemplo, 8GB+ para modelos grandes), pero el entrenamiento demanda significativamente más (por ejemplo, 16GB–24GB+), dependiendo del modelo y el conjunto de datos. | ✔️ Usar modelos más pequeños u optimizados para inferencia. ✔️ Usar servicios en la nube o entrenamiento distribuido para modelos grandes. ✔️ Optimizar las estrategias de carga y almacenamiento de datos. |
Requisitos de VRAM de Deepseek V3 0324
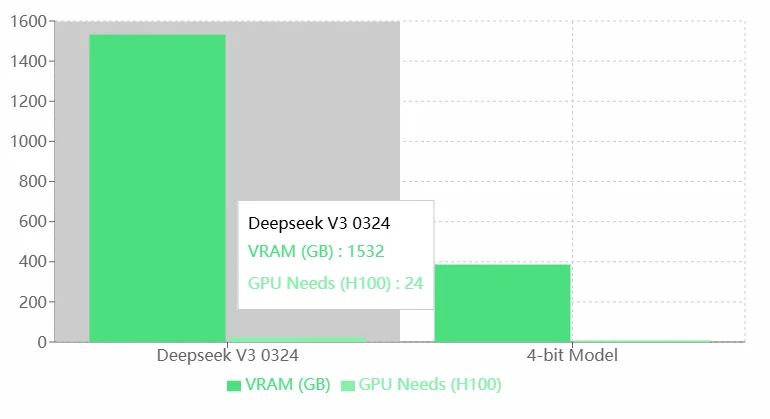
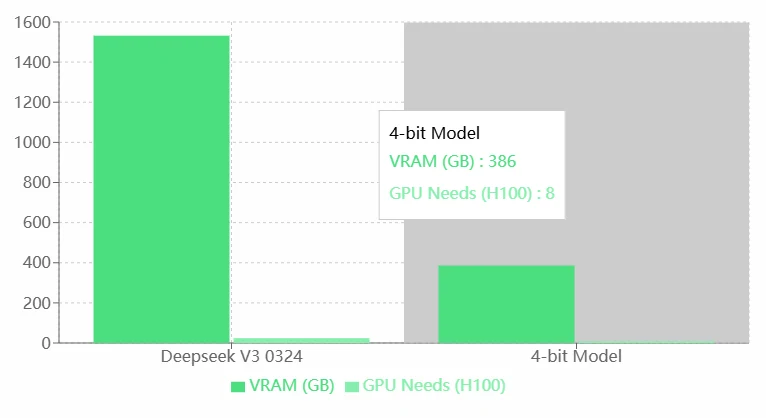
Ventajas:
- Alto rendimiento: Los altos requisitos de VRAM y GPU de Deepseek V3 0324 probablemente indican sus capacidades superiores, permitiéndole manejar tareas más complejas o ejecutar modelos más precisos.
- Adecuado para hardware de alta gama: Puede aprovechar las GPUs H100 de alto rendimiento, lo que lo hace ideal para aplicaciones a nivel empresarial o de investigación.
Desventajas:
- Alto consumo de recursos: Los requisitos extremadamente altos de VRAM y GPU aumentan significativamente la dependencia de los recursos de hardware, lo que puede generar costos operativos más elevados.
- Aplicabilidad limitada: Para individuos o equipos pequeños con recursos limitados, ejecutar Deepseek V3 0324 puede no ser factible.
- Falta de optimización: En comparación con el modelo de 4 bits, Deepseek V3 0324 parece tener una menor eficiencia en la utilización de recursos. Se recomienda la optimización del modelo (por ejemplo, cuantización o poda).
Implementación local de Deepseek V3 0324 vs. Acceso por API
| Aspecto | Implementación local | Acceso por API |
|---|---|---|
| Inversión inicial | $600,000+ (24 GPUs H100) | $0.33 / 1M tokens de entrada $1.3 / 1M tokens de salida |
| Infraestructura | Extensa (GPUs, refrigeración, energía) | No se requiere |
| Experiencia técnica | Se requieren equipos de ML/DevOps | Conocimientos básicos de API |
| Mantenimiento | Mantenimiento continuo del sistema | No se requiere |
| Escalabilidad | Limitada por el hardware | Instantánea y flexible |
| Fiabilidad | Depende de la configuración local | SLA de nivel empresarial |
| Rendimiento | Dependiente del hardware | Optimizado por el proveedor |
| Privacidad de datos | Control total | Dependiente del proveedor |
Novita AI: Una solución de API confiable y rentable
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

¡Prueba Deepseek V3 0324 ahora!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entra a la página de “Configuración” y copia la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalizaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-v3-0324"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Deepseek V3 0324 combina tecnología de vanguardia con opciones de implementación flexibles, adaptándose a diversas necesidades. Ya sea aprovechando el control local o el acceso rentable por API, este modelo permite a los usuarios contar con capacidades avanzadas de llamada a funciones y procesamiento multilingüe. Para una integración sin problemas, la API de Novita AI ofrece un punto de entrada accesible con barreras técnicas mínimas.
Preguntas frecuentes
¿Deepseek V3 0324 admite entradas multimodales?
No, Deepseek V3 0324 está diseñado únicamente para procesamiento de texto a texto.
¿Cómo empiezo a usar Deepseek V3 0324?
Simplemente inicia sesión en Novita AI, selecciona tu modelo, comienza la prueba gratuita y obtén tu clave de API para empezar la integración.
¿Qué tipo de infraestructura se requiere para la implementación local de Deepseek V3 0324?
La implementación local requiere 24 GPUs H100, refrigeración extensa y mantenimiento continuo, con un costo inicial de $600,000+.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



