

Destaques Principais
Deepseek V3 0324 se destaca no processamento multilíngue, com capacidades aprimoradas em idioma chinês, apresentando 671B parâmetros e a vanguarda da arquitetura Mixture-of-Experts (MoE).
Implantação Local: Alto desempenho, mas exige investimento inicial de mais de $600.000 e infraestrutura extensa.
Acesso via API: Econômico, escalável e otimizado pelo provedor com precificação por uso. Como a Novita AI, oferece $0,33 / 1M tokens de entrada e $1,3 / 1M tokens de saída.
O Deepseek V3 0324 é um modelo Mixture-of-Experts (MoE) de última geração, projetado para redefinir o processamento inteligente com 671B parâmetros. Lançado em 24 de março de 2025, oferece capacidades multilíngues incomparáveis, especialmente no processamento do idioma chinês. Embora a implantação local ofereça controle total, o acesso via API através da Novita AI garante economia, escalabilidade e confiabilidade de nível empresarial.
O que é Deepseek V3 0324?

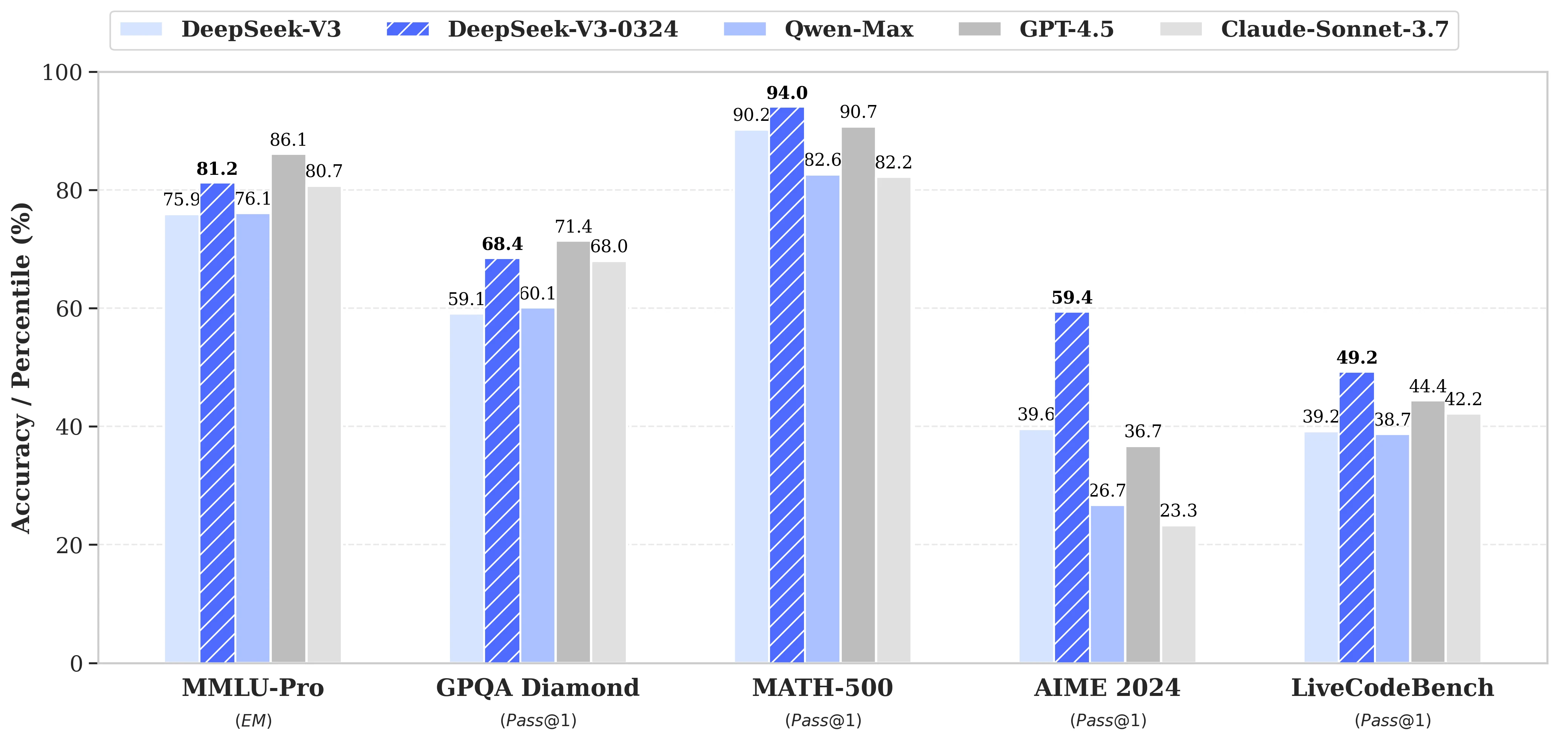
Benchmark do Deepseek V3 0324
O que é VRAM?
VRAM (Video Random Access Memory) é um tipo especializado de memória usado pela GPU (Unidade de Processamento Gráfico) do computador. Ela armazena e processa dados gráficos como texturas, modelos 3D, shaders e framebuffers. A VRAM é essencial para renderizar imagens, vídeos e gráficos em jogos, modelagem 3D, edição de vídeo e outras aplicações visuais.
https://www.youtube.com/watch?v=e4GCxObZrZE
O que a VRAM Significa para Acessar LLMs
Problemas e Soluções de VRAM para LLMs
| Problema | Solução |
|---|---|
| 📦Armazenamento do Modelo na VRAM Modelos grandes como GPT-4 exigem vários GBs de VRAM para armazenar pesos, parâmetros e computações. Se o tamanho do modelo exceder a VRAM, ele pode não funcionar de forma eficiente ou sequer funcionar. | ✔️ Use modelos menores ou otimizados. ✔️ Descarregue partes do modelo para a RAM do sistema ou disco. ✔️ Use GPUs com maior VRAM ou serviços em nuvem. |
| 📊Processamento em Lote O tamanho do lote determina quantas entradas podem ser processadas simultaneamente. A VRAM limitada restringe o tamanho do lote, reduzindo a taxa de transferência e aumentando a latência. | ✔️ Reduza o tamanho do lote para caber nos limites de VRAM. ✔️ Use vários lotes menores. ✔️ Atualize para GPUs com maior VRAM. |
| ⚙️Otimização do Modelo A VRAM limitada pode causar ineficiência ou impedir que o modelo seja executado completamente. | ✔️ Use quantização do modelo (ex.: 32 bits para 16 bits). ✔️ Descarregue computações para RAM ou disco. ✔️ Use poda para remover parâmetros desnecessários. |
| 🧠Inferência vs. Treinamento A inferência requer menos VRAM (ex.: 8GB+ para modelos grandes), mas o treinamento exige significativamente mais (ex.: 16GB–24GB+), dependendo do modelo e do conjunto de dados. | ✔️ Use modelos menores ou otimizados para inferência. ✔️ Use serviços em nuvem ou treinamento distribuído para modelos grandes. ✔️ Otimize estratégias de carregamento e armazenamento de dados. |
Requisitos de VRAM do Deepseek V3 0324
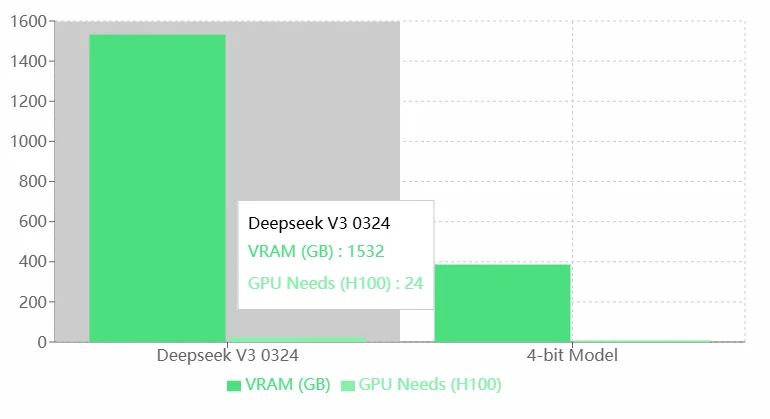
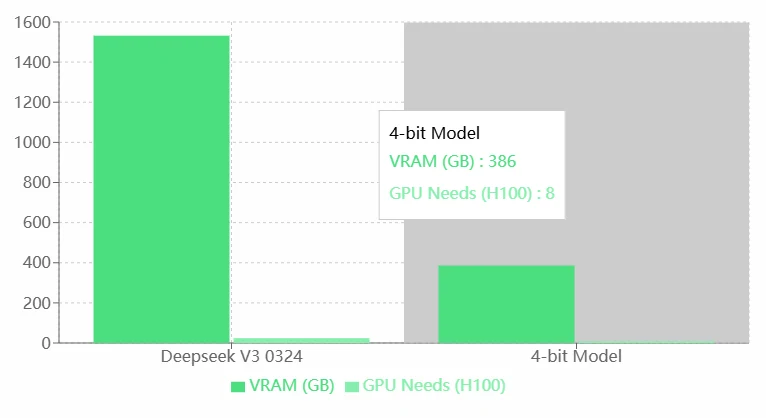
Prós:
- Alto Desempenho: Os altos requisitos de VRAM e GPU do Deepseek V3 0324 provavelmente indicam suas capacidades superiores, permitindo lidar com tarefas mais complexas ou executar modelos mais precisos.
- Adequado para Hardware de Alto Nível: Pode aproveitar as GPUs H100 de alto desempenho, sendo ideal para aplicações empresariais ou de pesquisa.
Contras:
- Alto Consumo de Recursos: Os requisitos extremamente altos de VRAM e GPU aumentam significativamente a dependência de recursos de hardware, o que pode levar a custos operacionais mais altos.
- Aplicabilidade Limitada: Para indivíduos ou pequenas equipes com recursos limitados, executar o Deepseek V3 0324 pode não ser viável.
- Falta de Otimização: Comparado ao modelo de 4 bits, o Deepseek V3 0324 parece ter menor eficiência de utilização de recursos. Recomenda-se a otimização do modelo (ex.: quantização ou poda).
Implantação Local do Deepseek V3 0324 vs. Acesso via API
| Aspecto | Implantação Local | Acesso via API |
|---|---|---|
| Investimento Inicial | $600.000+ (24 GPUs H100) | $0,33 / 1M tokens de entrada $1,3 / 1M tokens de saída |
| Infraestrutura | Extensa (GPUs, resfriamento, energia) | Nenhuma necessária |
| Expertise Técnica | Equipes de ML/DevOps necessárias | Conhecimento básico de API |
| Manutenção | Manutenção contínua do sistema | Nenhuma necessária |
| Escalabilidade | Limitada pelo hardware | Instantânea e flexível |
| Confiabilidade | Depende da configuração local | SLA de nível empresarial |
| Desempenho | Dependente do hardware | Otimizado pelo provedor |
| Privacidade de Dados | Controle total | Depende do provedor |
Novita AI: Uma Solução de API Confiável e Econômica
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library (Biblioteca de Modelos).

Experimente o Deepseek V3 0324 Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar na API, forneceremos a você uma nova chave de API. Entrando na página “Settings“ (Configurações), você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-v3-0324"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
O Deepseek V3 0324 combina tecnologia de ponta com opções flexíveis de implantação, atendendo a diversas necessidades. Seja aproveitando o controle local ou o acesso econômico via API, este modelo capacita os usuários com chamada de função avançada e capacidades multilíngues. Para integração perfeita, a API da Novita AI fornece um ponto de entrada acessível com barreiras técnicas mínimas.
Perguntas Frequentes
O Deepseek V3 0324 suporta entradas multimodais?
Não, o Deepseek V3 0324 foi projetado para processamento texto-para-texto apenas.
Como começar a usar o Deepseek V3 0324?
Basta fazer login na Novita AI, selecionar seu modelo, iniciar o teste gratuito e obter sua chave de API para começar a integração.
Que tipo de infraestrutura é necessária para a implantação local do Deepseek V3 0324?
A implantação local requer 24 GPUs H100, resfriamento extenso e manutenção contínua, custando $600.000+ de investimento inicial.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem GPU acessível e confiável para construir e escalar.



