

主なハイライト
Deepseek V3 0324 は ** 多言語処理 ** に優れ、特に ** 中国語 ** の能力が向上しています。**671B パラメータ ** と最先端の Mixture-of-Experts (MoE) アーキテクチャを搭載しています。
ローカルデプロイ:高性能だが、60万ドル以上の初期費用と大規模なインフラが必要。
API アクセス:コスト効率が高く、スケーラブルで、プロバイダー最適化された従量課金制。Novita AI では、入力トークン 100万トークンあたり $0.33、出力トークン 100万トークンあたり $1.3 で提供しています。
Deepseek V3 0324 は、**671B パラメータ ** を搭載した最先端の Mixture-of-Experts (MoE) モデルで、インテリジェント処理を再定義するために設計されています。**2025年3月24日 ** にリリースされ、特に ** 中国語 ** 処理において卓越した多言語機能を提供します。ローカルデプロイは完全な制御を提供しますが、Novita AI による API アクセス は、コスト効率、スケーラビリティ、エンタープライズグレードの信頼性を保証します。
Deepseek V3 0324 とは?

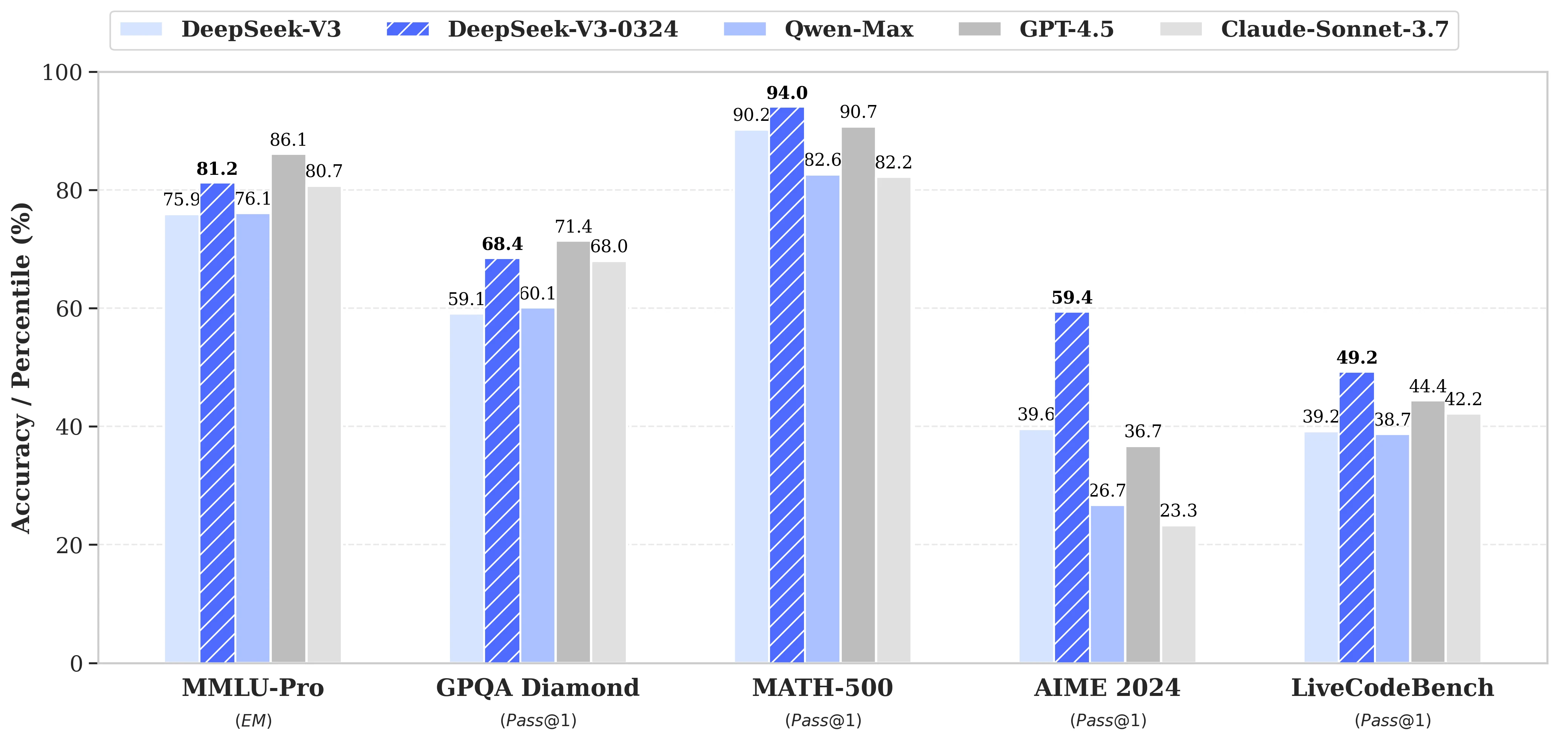
Deepseek V3 0324 ベンチマーク
VRAM とは?
VRAM(ビデオランダムアクセスメモリ) は、コンピュータの GPU(グラフィックス処理装置) が使用する特殊なメモリです。テクスチャ、3Dモデル、シェーダー、フレームバッファなどのグラフィカルデータを保存・処理します。VRAM は、ゲーム、3Dモデリング、ビデオ編集、その他のビジュアルアプリケーションにおける画像、動画、グラフィックスのレンダリングに不可欠です。
https://www.youtube.com/watch?v=e4GCxObZrZE
VRAM が LLM へのアクセスに与える影響
LLM における VRAM の問題と解決策
| 問題 | 解決策 |
|---|---|
| 📦VRAM へのモデル保存 GPT-4 のような大規模モデルは、重み、パラメータ、計算を保存するために数 GB の VRAM を必要とします。モデルサイズが VRAM を超えると、効率的に動作しないか、まったく動作しない可能性があります。 | ✔️ より小さい、または最適化されたモデルを使用する。 ✔️ モデルの一部をシステム RAM またはディスクにオフロードする。 ✔️ より大きな VRAM を持つ GPU またはクラウドサービスを使用する。 |
| 📊バッチ処理 バッチサイズは、同時に処理できる入力数を決定します。VRAM が限られているとバッチサイズが制限され、スループットが低下し、レイテンシが増加します。 | ✔️ VRAM の制限に合わせてバッチサイズを減らす。 ✔️ 複数の小さなバッチを使用する。 ✔️ より大きな VRAM を持つ GPU にアップグレードする。 |
| ⚙️モデル最適化 VRAM が限られていると、非効率が生じたり、モデルがまったく動作しなくなる可能性があります。 | ✔️ モデル量子化を使用する(例:32ビットから16ビット)。 ✔️ 計算を RAM またはディスクにオフロードする。 ✔️ プルーニングを使用して不要なパラメータを削除する。 |
| 🧠推論とトレーニング 推論に必要な VRAM は比較的少ないですが(大規模モデルで 8GB 以上)、トレーニングではモデルとデータセットに応じてそれ以上(16GB~24GB以上)必要です。 | ✔️ 推論にはより小さい、または最適化されたモデルを使用する。 ✔️ 大規模モデルにはクラウドサービスまたは分散トレーニングを使用する。 ✔️ データ読み込みと保存戦略を最適化する。 |
Deepseek V3 0324 の VRAM 要件
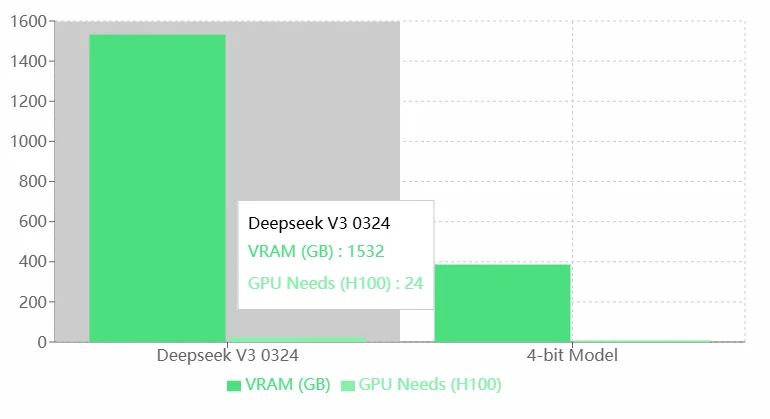
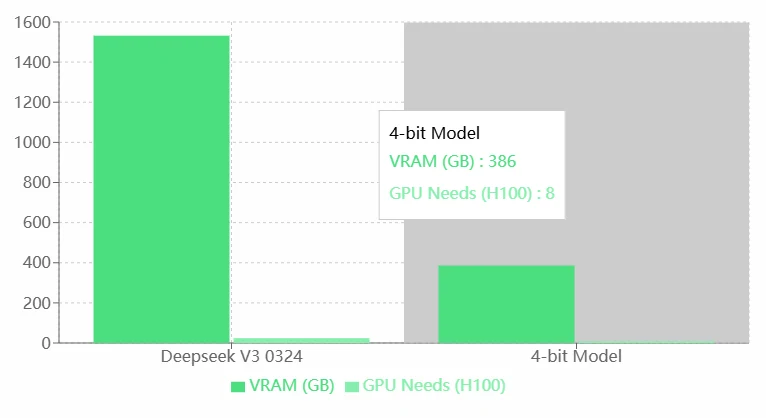
メリット:
- 高性能: Deepseek V3 0324 の高い VRAM と GPU 要件は、おそらくその優れた能力を示しており、より複雑なタスクを処理したり、より精密なモデルを実行できることを意味します。
- ハイエンドハードウェアに最適: 高性能な H100 GPU を活用できるため、エンタープライズレベルまたは研究レベルのアプリケーションに最適です。
デメリット:
- 高いリソース消費: 非常に高い VRAM と GPU 要件により、ハードウェアリソースへの依存度が大幅に高まり、運用コストの増加につながる可能性があります。
- 適用範囲の限定: リソースが限られている個人や小規模チームでは、Deepseek V3 0324 を実行することが現実的でない場合があります。
- 最適化の欠如: 4ビットモデルと比較して、Deepseek V3 0324 はリソース利用効率が低いようです。モデル最適化(例:量子化またはプルーニング)をお勧めします。
Deepseek V3 0324 のローカルデプロイ vs API アクセス
| **側面 ** | ** ローカルデプロイ ** | API アクセス |
|---|---|---|
| 初期投資 | $600,000以上(24台の H100 GPU) | $0.33 / 100万入力トークン $1.3 / 100万出力トークン |
| インフラ | 大規模(GPU、冷却、電源) | 不要 |
| 技術的専門知識 | ML/DevOps チームが必要 | 基本的な API 知識 |
| メンテナンス | 継続的なシステム保守 | 不要 |
| スケーラビリティ | ハードウェアに制限される | 即時的で柔軟 |
| 信頼性 | ローカル環境に依存 | エンタープライズグレードの SLA |
| パフォーマンス | ハードウェアに依存 | プロバイダー最適化 |
| データプライバシー | 完全に制御可能 | プロバイダーに依存 |
Novita AI:信頼性が高くコスト効率の良い API ソリューション
ステップ 1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ 3:無料トライアルを開始
選択したモデルの機能を探るために、無料トライアルを開始します。
ステップ 4:API キーを取得
API で認証するために、新しい API キーが提供されます。「設定」ページに移動し、画像のように API キーをコピーします。

ステップ 5:API のインストール
プログラミング言語固有のパッケージマネージャーを使用して API をインストールします。

インストール後、開発環境に必要なライブラリをインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-v3-0324"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Deepseek V3 0324 は、最先端のテクノロジーと柔軟なデプロイオプションを組み合わせ、多様なニーズに対応します。ローカルでの制御 ** または ** コスト効率の高い API アクセス のいずれを活用する場合でも、このモデルは高度な関数呼び出しと多言語機能をユーザーに提供します。シームレスな統合のために、Novita AI の API は最小限の技術的障壁でアクセスしやすいエントリーポイントを提供します。
よくある質問
Deepseek V3 0324 はマルチモーダル入力をサポートしていますか?
いいえ、Deepseek V3 0324 は テキスト間処理のみ を対象として設計されています。
Deepseek V3 0324 の使用を開始するにはどうすればよいですか?
Novita AI にログインし、モデルを選択し、無料トライアルを開始して、API キーを取得して統合を開始するだけです。
Deepseek V3 0324 のローカルデプロイにはどのようなインフラが必要ですか?
ローカルデプロイには 24台の H100 GPU、大規模な冷却、継続的なメンテナンスが必要で、初期費用は $600,000以上 かかります。
Novita AI は、シンプルな API を使用して AI モデルを簡単にデプロイできる方法を開発者に提供するとともに、手頃で信頼性の高い GPU クラウドを構築・拡張するためのプラットフォームです。



