

Key Highlights
Deepseek V3 0324 excels in multilingual processing, with enhanced Chinese language capabilities, featuring 671B parameters and cutting-edge Mixture-of-Experts (MoE) architecture.
Local Deployment: High performance but requires $600,000+ upfront and extensive infrastructure.
API Access: Cost-efficient, scalable, and provider-optimized with pay-per-use pricing. Like Novita AI, it offers $0.33/ 1M input tokens and $1.3 / 1M output tokens
Deepseek V3 0324 is a state-of-the-art Mixture-of-Experts (MoE) model designed to redefine intelligent processing with 671B parameters. Released on March 24, 2025, it offers unmatched multilingual capabilities, particularly excelling in Chinese language processing. While local deployment offers full control, API access through Novita AI ensures cost-effectiveness, scalability, and enterprise-grade reliability.
What is Deepseek V3 0324?

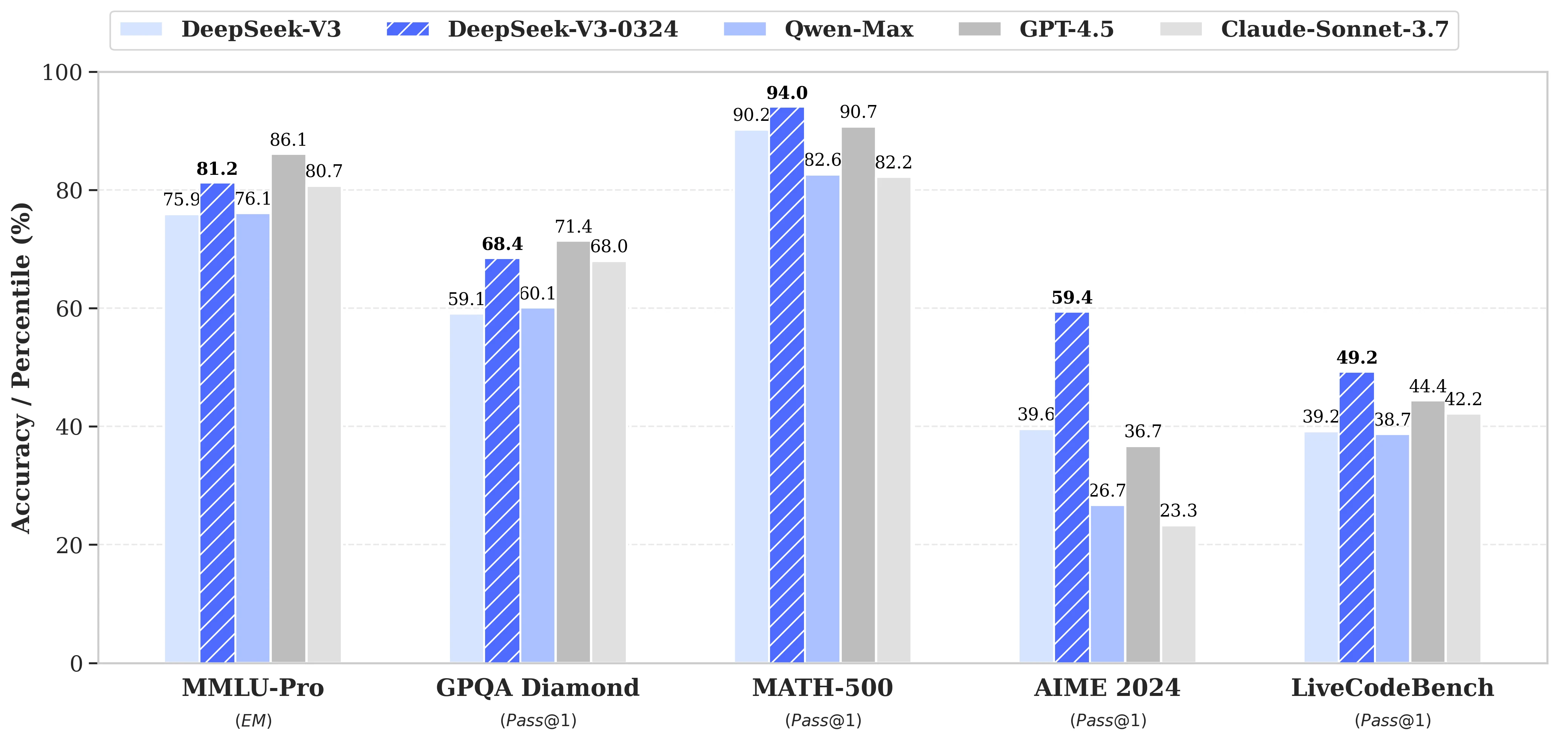
Deepseek V3 0324 Benchmark
What is VRAM?
VRAM (Video Random Access Memory) is a specialized type of memory used by a computer’s GPU (Graphics Processing Unit). It stores and processes graphical data such as textures, 3D models, shaders, and framebuffers. VRAM is essential for rendering images, videos, and graphics in games, 3D modeling, video editing, and other visual applications.
https://www.youtube.com/watch?v=e4GCxObZrZE
What Does VRAM Mean for Accessing LLMs
VRAM Issues and Solutions for LLMs
| Problem | Solution |
|---|---|
| 📦Model Storage in VRAM Large models like GPT-4 require several GBs of VRAM to store weights, parameters, and computations. If the model size exceeds VRAM, it may not run efficiently or at all. | ✔️ Use smaller or optimized models. ✔️ Offload parts of the model to system RAM or disk. ✔️ Use GPUs with higher VRAM or cloud services. |
| 📊Batch Processing Batch size determines how many inputs can be processed simultaneously. Limited VRAM restricts batch size, reducing throughput and increasing latency. | ✔️ Reduce batch size to fit VRAM limits. ✔️ Use multiple smaller batches. ✔️ Upgrade to GPUs with larger VRAM. |
| ⚙️Model Optimization Limited VRAM may cause inefficiency or prevent the model from running entirely. | ✔️ Use model quantization (e.g., 32-bit to 16-bit). ✔️ Offload computations to RAM or disk. ✔️ Use pruning to remove unnecessary parameters. |
| 🧠Inference vs. Training Inference requires less VRAM (e.g., 8GB+ for large models), but training demands significantly more (e.g., 16GB–24GB+), depending on the model and dataset. | ✔️ Use smaller or optimized models for inference. ✔️ Use cloud services or distributed training for large models. ✔️ Optimize data loading and storage strategies. |
Deepseek V3 0324 VRAM Requirements
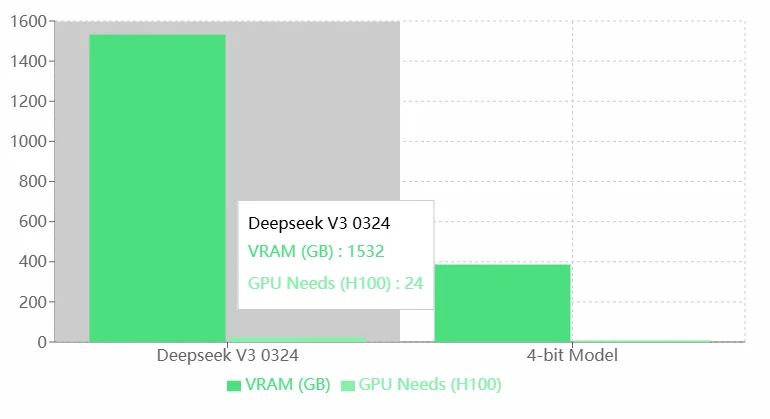
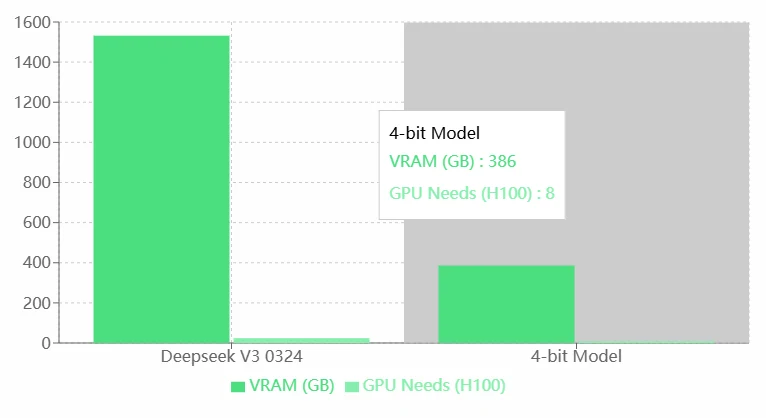
Pros:
- High Performance: The high VRAM and GPU requirements of Deepseek V3 0324 likely indicate its superior capabilities, enabling it to handle more complex tasks or run more precise models.
- Suitable for High-End Hardware: It can leverage the high-performance H100 GPUs, making it ideal for enterprise-level or research-level applications.
Cons:
- High Resource Consumption: The extremely high VRAM and GPU requirements significantly increase dependency on hardware resources, which can lead to higher operational costs.
- Limited Applicability: For individuals or small teams with limited resources, running Deepseek V3 0324 may not be feasible.
- Lack of Optimization: Compared to the 4-bit model, Deepseek V3 0324 appears to have lower resource utilization efficiency. Model optimization (e.g., quantization or pruning) is recommended.
Deploying Deepseek V3 0324 Locally VS API Access
| Aspect | Local Deployment | API Access |
|---|---|---|
| Initial Investment | $600,000+ (24 H100 GPUs) | $0.33 / 1M input tokens $1.3 / 1M output tokens |
| Infrastructure | Extensive (GPUs, cooling, power) | None required |
| Technical Expertise | ML/DevOps teams required | Basic API knowledge |
| Maintenance | Continuous system upkeep | None required |
| Scalability | Limited by hardware | Instant and flexible |
| Reliability | Depends on local setup | Enterprise-grade SLA |
| Performance | Hardware-dependent | Provider-optimized |
| Data Privacy | Full control | Provider-dependent |
Novita AI: A Reliable and Cost-Effective API Solution
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
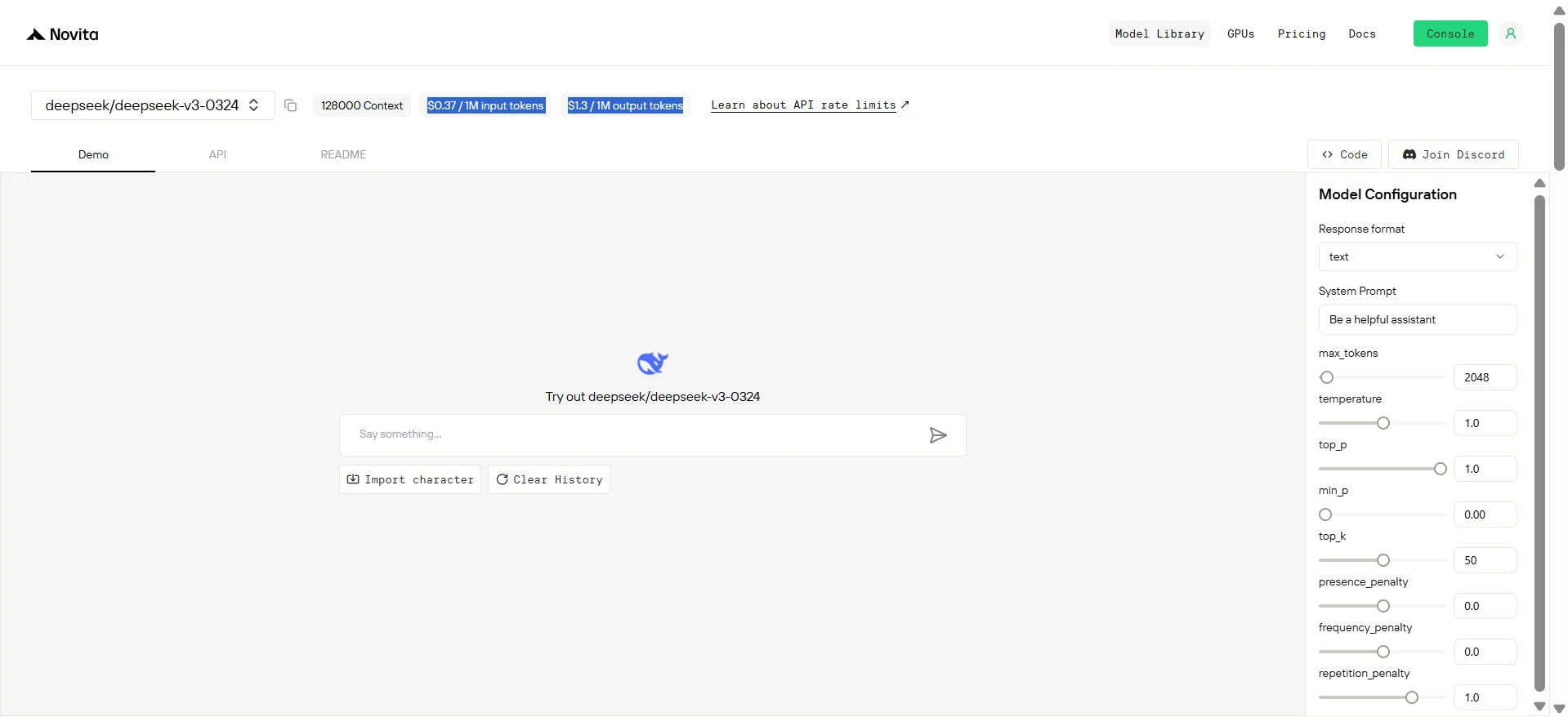
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-v3-0324"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Deepseek V3 0324 combines cutting-edge technology with flexible deployment options, catering to diverse needs. Whether leveraging local control or cost-effective API access, this model empowers users with advanced function calling and multilingual capabilities. For seamless integration, Novita AI’s API provides an accessible entry point with minimal technical barriers.
Frequently Asked Questions
Does Deepseek V3 0324 support multimodal inputs?
No, Deepseek V3 0324 is designed for text-to-text processing only.
How do I start using Deepseek V3 0324 ?
Simply log in to Novita AI, select your model, start the free trial, and retrieve your API key to begin integration.
What type of infrastructure is required for Deepseek V3 0324 local deployment?
Local deployment requires 24 H100 GPUs, extensive cooling, and continuous maintenance, costing $600,000+ upfront.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



