

Wichtige Highlights
Deepseek V3 0324 zeichnet sich durch mehrsprachige Verarbeitung aus, mit verbesserten chinesischen Sprachfähigkeiten, 671B Parametern und einer hochmodernen Mixture-of-Experts (MoE)-Architektur.
Lokaler Einsatz: Hohe Leistung, erfordert jedoch Vorabinvestitionen von über 600.000 $ und umfangreiche Infrastruktur.
API-Zugriff: Kosteneffizient, skalierbar und anbieteroptimiert mit nutzungsabhängiger Abrechnung. Wie Novita AI bietet es 0,33 $ / 1 Mio. Input-Token und 1,3 $ / 1 Mio. Output-Token.
Deepseek V3 0324 ist ein hochmodernes Mixture-of-Experts (MoE)-Modell, das mit 671B Parametern die intelligente Verarbeitung neu definieren soll. Es wurde am 24. März 2025 veröffentlicht und bietet unübertroffene mehrsprachige Fähigkeiten, die sich insbesondere in der chinesischen Sprachverarbeitung auszeichnen. Während der lokale Einsatz volle Kontrolle bietet, garantiert der API-Zugriff über Novita AI Kosteneffizienz, Skalierbarkeit und Unternehmenszuverlässigkeit.
Was ist Deepseek V3 0324?

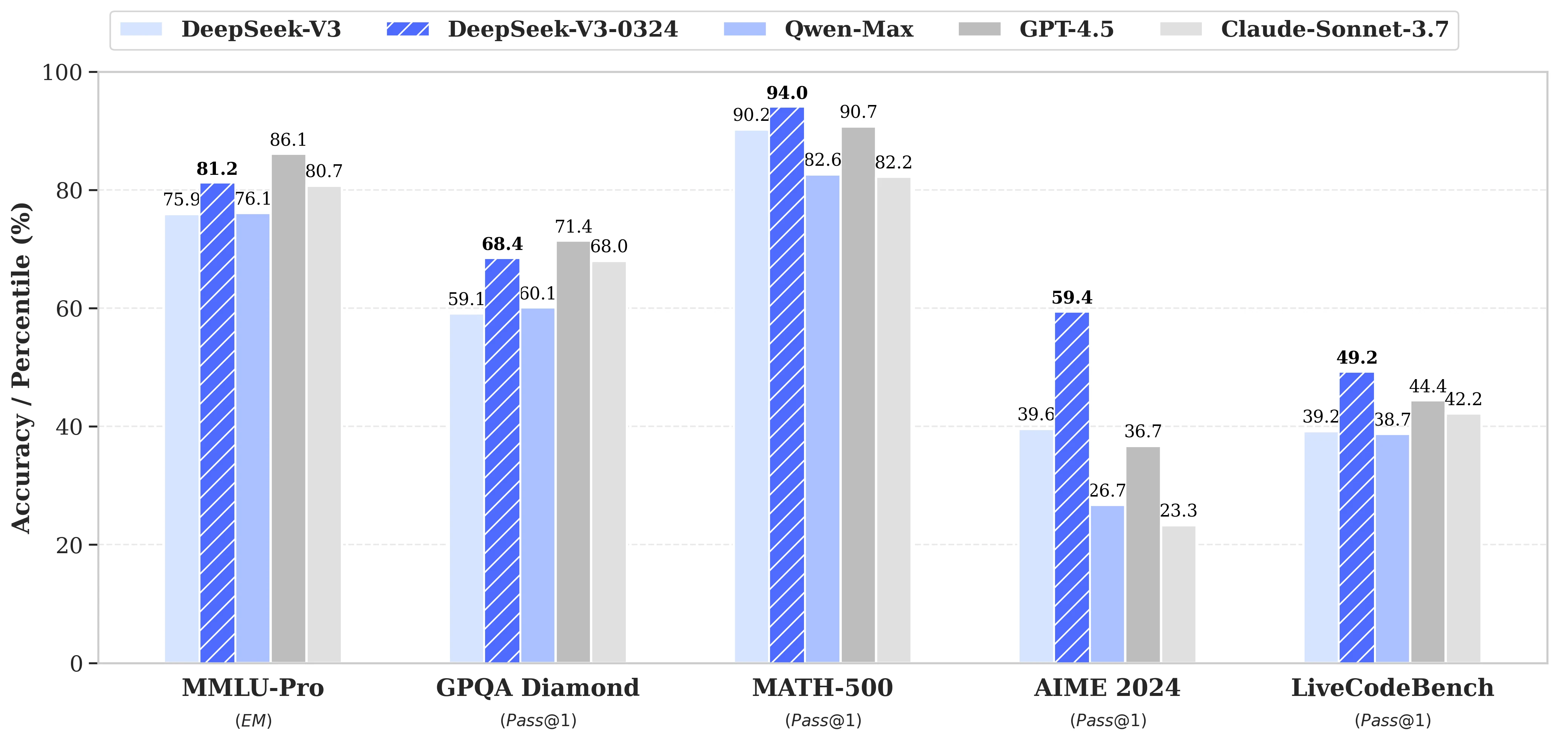
Benchmarks von Deepseek V3 0324
Was ist VRAM?
VRAM (Video Random Access Memory) ist ein spezieller Speichertyp, der von der GPU (Graphics Processing Unit) eines Computers verwendet wird. Es speichert und verarbeitet Grafikdaten wie Texturen, 3D-Modelle, Shader und Framebuffer. VRAM ist für die Darstellung von Bildern, Videos und Grafiken in Spielen, 3D-Modellierung, Videobearbeitung und anderen visuellen Anwendungen unerlässlich.
https://www.youtube.com/watch?v=e4GCxObZrZE
Was bedeutet VRAM für den Zugriff auf LLMs?
VRAM-Probleme und Lösungen für LLMs
| Problem | Lösung |
|---|---|
| 📦Modellspeicher im VRAM Große Modelle wie GPT-4 benötigen mehrere GB VRAM, um Gewichte, Parameter und Berechnungen zu speichern. Überschreitet die Modellgröße den VRAM, kann es ineffizient oder gar nicht laufen. | ✔️ Kleinere oder optimierte Modelle verwenden. ✔️ Teile des Modells in den Arbeitsspeicher oder auf die Festplatte auslagern. ✔️ GPUs mit mehr VRAM oder Cloud-Dienste nutzen. |
| 📊Batch-Verarbeitung Die Batch-Größe bestimmt, wie viele Eingaben gleichzeitig verarbeitet werden können. Begrenzter VRAM schränkt die Batch-Größe ein und reduziert den Durchsatz sowie die Latenz. | ✔️ Batch-Größe reduzieren, um VRAM-Limits einzuhalten. ✔️ Mehrere kleinere Batches verwenden. ✔️ Auf GPUs mit größerem VRAM aufrüsten. |
| ⚙️Modelloptimierung Begrenzter VRAM kann zu Ineffizienz führen oder den Betrieb des Modells ganz verhindern. | ✔️ Modellquantisierung verwenden (z. B. von 32-Bit auf 16-Bit). ✔️ Berechnungen in RAM oder auf die Festplatte auslagern. ✔️ Pruning anwenden, um unnötige Parameter zu entfernen. |
| 🧠Inferenz vs. Training Inferenz erfordert weniger VRAM (z. B. 8 GB+ für große Modelle), aber Training benötigt deutlich mehr (z. B. 16–24 GB+), abhängig von Modell und Datensatz. | ✔️ Kleinere oder optimierte Modelle für die Inferenz verwenden. ✔️ Cloud-Dienste oder verteiltes Training für große Modelle nutzen. ✔️ Datenlade- und Speicherstrategien optimieren. |
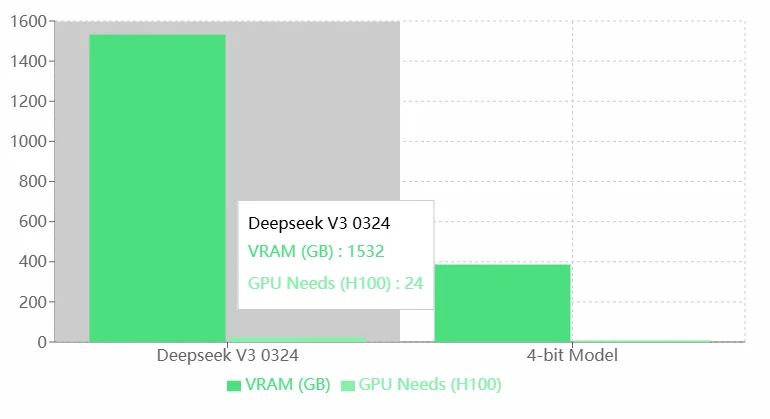
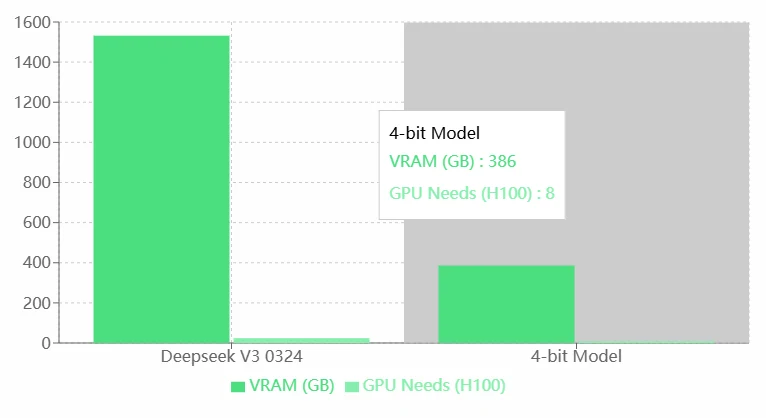
VRAM-Anforderungen von Deepseek V3 0324
Vorteile:
- Hohe Leistung: Die hohen VRAM- und GPU-Anforderungen von Deepseek V3 0324 deuten wahrscheinlich auf seine überlegenen Fähigkeiten hin, wodurch es komplexere Aufgaben bewältigen oder präzisere Modelle ausführen kann.
- Geeignet für High-End-Hardware: Es kann die leistungsstarken H100-GPUs nutzen, was es ideal für Unternehmens- oder Forschungsanwendungen macht.
Nachteile:
- Hoher Ressourcenverbrauch: Die extrem hohen VRAM- und GPU-Anforderungen erhöhen die Abhängigkeit von Hardware-Ressourcen erheblich, was zu höheren Betriebskosten führen kann.
- Eingeschränkte Anwendbarkeit: Für Einzelpersonen oder kleine Teams mit begrenzten Ressourcen ist der Betrieb von Deepseek V3 0324 möglicherweise nicht realisierbar.
- Fehlende Optimierung: Im Vergleich zum 4-Bit-Modell scheint Deepseek V3 0324 eine geringere Ressourceneffizienz zu haben. Eine Modelloptimierung (z. B. Quantisierung oder Pruning) wird empfohlen.
Lokaler Einsatz von Deepseek V3 0324 vs. API-Zugriff
| Aspekt | Lokaler Einsatz | API-Zugriff |
|---|---|---|
| Anfangsinvestition | 600.000 $+ (24 H100 GPUs) | 0,33 $ / 1 Mio. Input-Tokens 1,3 $ / 1 Mio. Output-Tokens |
| Infrastruktur | Umfangreich (GPUs, Kühlung, Strom) | Keine erforderlich |
| Technisches Know-how | ML/DevOps-Teams erforderlich | Grundlegende API-Kenntnisse |
| Wartung | Kontinuierliche Systempflege | Keine erforderlich |
| Skalierbarkeit | Durch Hardware begrenzt | Sofortig und flexibel |
| Zuverlässigkeit | Abhängig von lokaler Einrichtung | Unternehmens-SLA |
| Leistung | Hardwareabhängig | Anbieteroptimiert |
| Datenschutz | Volle Kontrolle | Abhängig vom Anbieter |
Novita AI: Eine zuverlässige und kosteneffiziente API-Lösung
Schritt 1: Einloggen und die Modellbibliothek aufrufen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Deepseek V3 0324 jetzt ausprobieren!
Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-v3-0324"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Deepseek V3 0324 vereint modernste Technologie mit flexiblen Einsatzmöglichkeiten und deckt verschiedene Anforderungen ab. Ob durch lokale Kontrolle oder kosteneffizienten API-Zugriff – dieses Modell ermöglicht es Benutzern, erweiterte Funktionsaufrufe und mehrsprachige Fähigkeiten zu nutzen. Für eine nahtlose Integration bietet die API von Novita AI einen zugänglichen Einstiegspunkt mit minimalen technischen Hürden.
Häufig gestellte Fragen
Unterstützt Deepseek V3 0324 multimodale Eingaben?
Nein, Deepseek V3 0324 ist nur für die Text-zu-Text-Verarbeitung ausgelegt.
Wie beginne ich mit der Nutzung von Deepseek V3 0324?
Melden Sie sich einfach bei Novita AI an, wählen Sie Ihr Modell, starten Sie die kostenlose Testversion und holen Sie Ihren API-Schlüssel ab, um mit der Integration zu beginnen.
Welche Infrastruktur wird für den lokalen Einsatz von Deepseek V3 0324 benötigt?
Der lokale Einsatz erfordert 24 H100 GPUs, umfangreiche Kühlung und kontinuierliche Wartung, mit Vorabkosten von 600.000 $+.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.



