

核心亮点
Deepseek V3 0324 在 ** 多语言处理方面表现卓越,具备增强的 ** 中文能力,拥有 671B 参数 ** 和先进的混合专家(MoE)** 架构。
本地部署:性能强劲,但需要 60 万美元+ 的前期投入和庞大的基础设施。
API 访问:成本高效、可扩展且由服务商优化,按量付费。例如 Novita AI 提供 $0.33/1M 输入 tokens 和 $1.3/1M 输出 tokens。
Deepseek V3 0324 是一款先进的 混合专家(MoE) 模型,拥有 **671B 参数 **,旨在重新定义智能处理。它于 2025 年 3 月 24 日 ** 发布,提供无与伦比的多语言能力,尤其在中文 ** 处理方面表现出色。虽然本地部署可提供完全控制,但通过 Novita AI 的 API 访问 能确保成本效益、可扩展性和企业级可靠性。
Deepseek V3 0324 是什么?

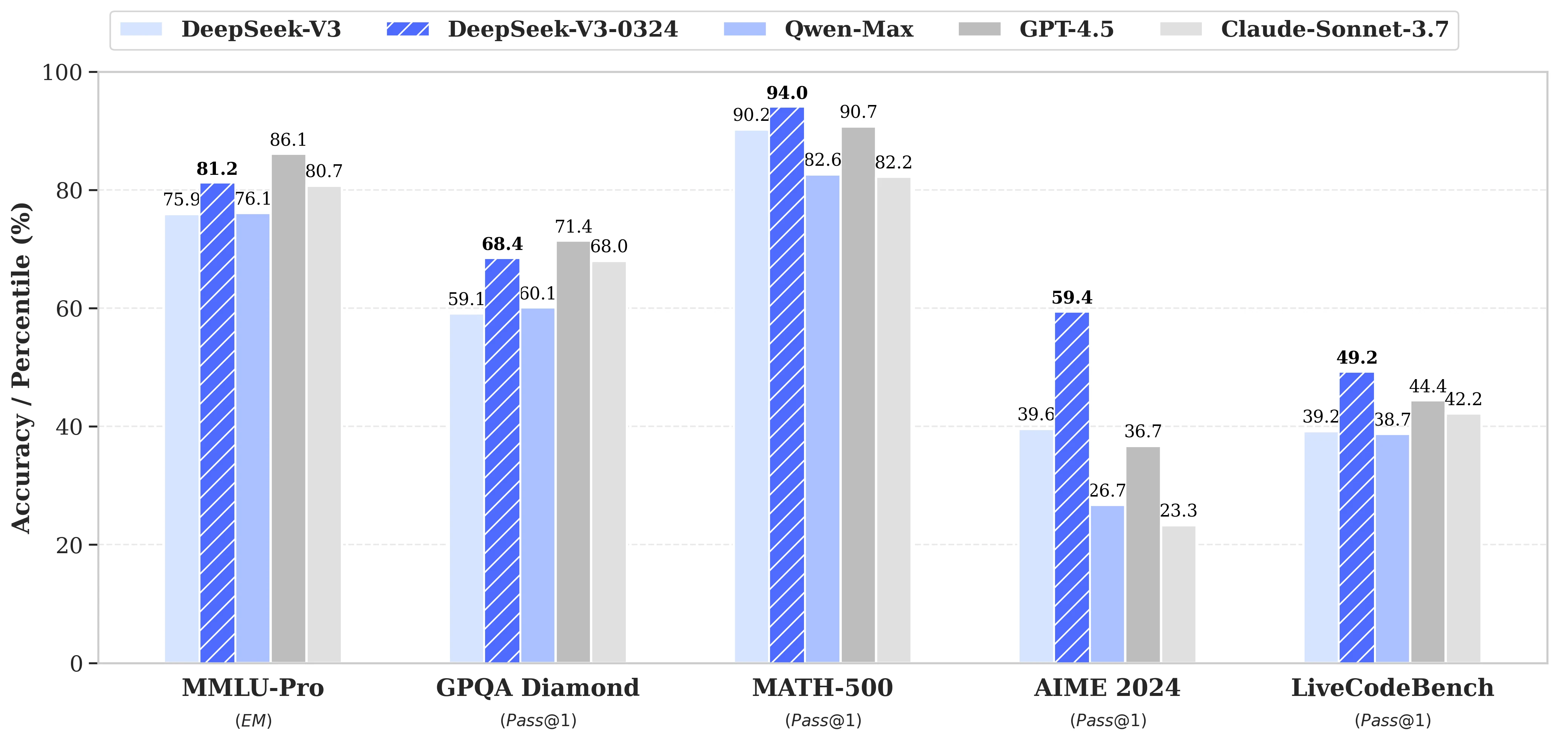
Deepseek V3 0324 基准测试
什么是 VRAM?
VRAM(视频随机存取内存) 是计算机 GPU(图形处理单元) 使用的一种专用内存。它存储和处理图形数据,如纹理、3D 模型、着色器和帧缓冲区。VRAM 对于游戏、3D 建模、视频编辑及其他视觉应用中的图像、视频和图形渲染至关重要。
https://www.youtube.com/watch?v=e4GCxObZrZE
VRAM 对访问 LLM 意味着什么?
LLM 的 VRAM 问题及解决方案
| 问题 | 解决方案 |
|---|---|
| 📦模型存储于 VRAM 像 GPT-4 这样的大型模型需要数 GB 的 VRAM 来存储权重、参数和计算结果。如果模型大小超过 VRAM,可能无法高效运行甚至完全无法运行。 | ✔️ 使用更小或优化过的模型。 ✔️ 将部分模型卸载到系统内存或磁盘。 ✔️ 使用更高 VRAM 的 GPU 或云服务。 |
| 📊批处理 批大小决定可同时处理的输入数量。有限的 VRAM 会限制批大小,降低吞吐量并增加延迟。 | ✔️ 减小批大小以适应 VRAM 限制。 ✔️ 使用多个更小的批次。 ✔️ 升级到更大 VRAM 的 GPU。 |
| ⚙️模型优化 有限的 VRAM 可能导致效率低下甚至完全无法运行模型。 | ✔️ 使用模型量化(例如从 32 位降到 16 位)。 ✔️ 将计算卸载到内存或磁盘。 ✔️ 使用剪枝移除不必要的参数。 |
| 🧠推理 vs. 训练 推理所需 VRAM 较少(大型模型约 8GB+),但训练需要更多(16GB–24GB+),具体取决于模型和数据集。 | ✔️ 推理时使用更小或优化过的模型。 ✔️ 大型模型使用云服务或分布式训练。 ✔️ 优化数据加载和存储策略。 |
Deepseek V3 0324 VRAM 需求
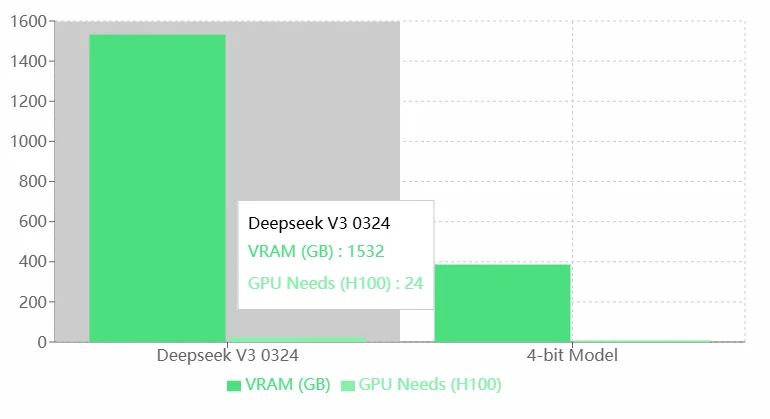
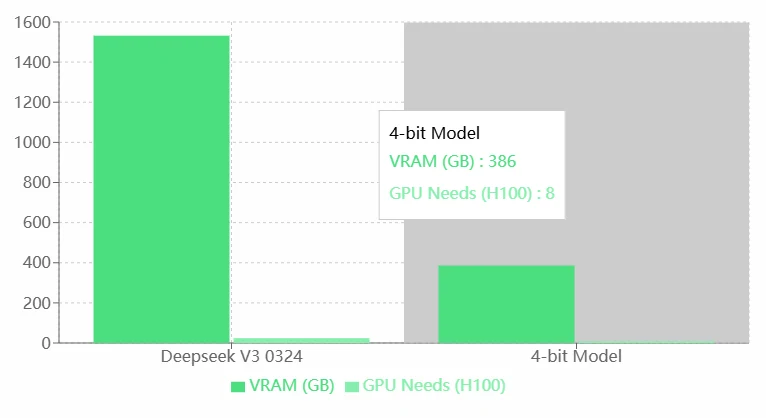
优点:
- 高性能: Deepseek V3 0324 的高 VRAM 和 GPU 需求很可能意味着其卓越的能力,使其能够处理更复杂的任务或运行更精确的模型。
- 适合高端硬件: 它可以利用高性能的 H100 GPU,非常适合企业级或研究级应用。
缺点:
- 高资源消耗: 极高的 VRAM 和 GPU 需求显著增加了对硬件资源的依赖,可能导致更高的运营成本。
- 适用性有限: 对于资源有限的个人或小团队而言,运行 Deepseek V3 0324 可能不可行。
- 缺乏优化: 与 4-bit 模型相比,Deepseek V3 0324 的资源利用效率似乎较低。建议进行模型优化(例如量化或剪枝)。
本地部署 Deepseek V3 0324 与 API 访问
| **方面 ** | ** 本地部署 ** | API 访问 |
|---|---|---|
| 初始投资 | $600,000+(24 块 H100 GPU) | $0.33 / 1M 输入 tokens $1.3 / 1M 输出 tokens |
| 基础设施 | 庞大(GPU、冷却、电力) | 无需任何基础设施 |
| 技术专长 | 需要 ML/DevOps 团队 | 基本的 API 知识 |
| 维护 | 持续的系统维护 | 无需维护 |
| 可扩展性 | 受硬件限制 | 即时且灵活 |
| 可靠性 | 取决于本地环境 | 企业级 SLA |
| 性能 | 依赖硬件 | 服务商优化 |
| 数据隐私 | 完全控制 | 依赖服务商 |
Novita AI:可靠且经济的 API 解决方案
第 1 步:登录并访问模型库
登录您的账户,然后点击 “模型库” 按钮。

第 2 步:选择模型
浏览可用选项,选择满足您需求的模型。

第 3 步:开始免费试用
开始免费试用,探索所选模型的功能。
第 4 步:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入 “设置” 页面,您可以按图示复制 API 密钥。

第 5 步:安装 API
使用适用于您编程语言的包管理器安装 API。

安装后,将必要的库导入您的开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-v3-0324"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Deepseek V3 0324 将尖端技术与灵活的部署选项相结合,满足多样化的需求。无论是利用 本地控制 ** 还是 ** 经济的 API 访问,该模型都能通过先进的函数调用和多语言能力赋能用户。如需无缝集成,Novita AI 的 API 提供了一个低技术门槛的便捷入口。
常见问题
Deepseek V3 0324 支持多模态输入吗?
不支持,Deepseek V3 0324 仅支持 文本到文本 处理。
如何开始使用 Deepseek V3 0324?
只需登录 Novita AI,选择模型,开始免费试用,然后获取 API 密钥即可开始集成。
Deepseek V3 0324 本地部署需要什么样的基础设施?
本地部署需要 24 块 H100 GPU、大量的冷却和持续维护,前期成本 $600,000+。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时也提供经济可靠的 GPU 云用于构建和扩展。



