

- Introduction de base à Deepseek R1 Distill Qwen 32B
- Informations de base
- Support linguistique
- Points clés
- Capacité multimodale
- Entraînement
- Comment accéder à Deepseek R1 Distill Qwen 32B en local
- Défis du déploiement local
- Comment accéder à Deepseek R1 Distill Qwen 32B via Novita AI
- Quelles méthodes vous conviennent ?
Points clés
Puissant mais efficace : égalise les performances des modèles plus grands avec des besoins réduits en ressources.
Leader des benchmarks : excelle dans AIME 2024 et SWE-bench Verified, surpassant OpenAI-o1-mini.
Support multilingue : gère plus de 29 langues, dont le chinois, l’anglais et le français.
Fonctionnalités avancées : prend en charge les textes longs (8K+ tokens), les sorties structurées et les scénarios de jeu de rôle.
Facile d’accès : disponible via Ollama pour un déploiement local ou l’API Novita AI pour l’intégration.
Parrainez vos amis vers Novita AI et vous gagnerez chacun 10 $ de crédits API LLM – jusqu’à 500 $ de récompenses totales.
Pour soutenir la communauté des développeurs, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B sont actuellement disponibles gratuitement sur Novita AI.

Le DeepSeek R1 Distill Qwen 32B est un modèle distillé de pointe offrant la puissance de modèles plus grands avec des besoins matériels considérablement réduits. Son architecture fine-tunée offre des performances supérieures, surpassant systématiquement des modèles comme OpenAI-o1-mini dans les benchmarks. Conçu pour l’efficacité et l’accessibilité, il prend en charge le déploiement local et l’intégration API transparente, ce qui le rend idéal pour les développeurs, chercheurs et entreprises.
Introduction de base à Deepseek R1 Distill Qwen 32B
Informations de base
Taille du modèle
32,8B
Open Source
Oui
Architecture
Transformer
Support linguistique
Support multilingue pour plus de 29 langues, dont :
Chinois, Anglais, Français, Espagnol, Portugais, Allemand, Italien, Russe, Japonais, Coréen, Vietnamien, Thaï, Arabe et plus…
Points clés
- Améliorations significatives dans le suivi des instructions et la génération de longs textes (plus de 8K tokens).
- Meilleure compréhension des données structurées (ex. tableaux) et génération de sorties structurées, en particulier JSON.
- Plus résistant aux invites système diverses, améliorant l’implémentation du jeu de rôle et le réglage des conditions pour les chatbots.
Capacité multimodale
Prend en charge les transformations texte-texte.
Entraînement
Fine-tuning de Qwen 2.5 32B avec DeepSeek R1 comme enseignant pour obtenir des performances similaires à des modèles plus grands.
DeepSeek a vraiment fait quelque chose de spécial en distillant le grand modèle R1 dans d’autres modèles open-source. Surtout la fusion avec Qwen-32B semble apporter des gains incroyables sur tous les benchmarks et en fait un modèle de référence pour les personnes disposant de moins de VRAM, donnant globalement les meilleurs résultats par rapport à la distillation Llama-70B. Actuellement, c’est le SOTA pour les LLM locaux, et il devrait être assez performant même sur du matériel grand public.
Benchmark
| Benchmark | DeepSeek-R1-32B | OpenAI-o1-mini | Autre modèle |
|---|---|---|---|
| AIME 2024 | 72,6% | 63,6% | Llama-70B : 70,0%, QwQ-32B : 50,0% |
| Codeforces | 71,5% | 60,0% | Llama-70B : 57,5%, QwQ-32B : 54,5% |
| GPQA Diamond | 62,1% | 60,0% | Llama-70B : 65,2%, QwQ-32B : 54,5% |
| MATH-500 | 75,7% | 90,0% | Llama-70B : 94,5%, QwQ-32B : 90,6% |
| MMLU | 90,8% | 88,5% | Llama-70B : 91,8%, QwQ-32B : 90,6% |
| SWE-bench Verified | 49,2% | 36,8% | Llama-70B : 57,5%, QwQ-32B : 41,6% |
Deepseek R1 Distill Qwen 32B excelle dans AIME 2024 et SWE-bench Verified, surpasse légèrement OpenAI-o1-mini dans certaines tâches, mais est généralement en retard par rapport aux modèles plus grands comme Deepseek R1 Llama 70B dans les benchmarks nécessitant un raisonnement avancé ou des capacités mathématiques.
Comment accéder à Deepseek R1 Distill Qwen 32B en local
Configuration matérielle requise
Taille du modèle : 73,21 Go
- 1 × H100 (80 Go) : GPU haute performance pour l’entraînement.
- 1 × A100 (80 Go) : GPU haute mémoire pour les grands ensembles de données.
- 2 × L40s (96 Go) : GPU d’inférence avancés avec mémoire améliorée.
- 4 × RTX 4090 (96 Go) : GPU haute puissance pour les tâches distribuées.
Guide d’installation étape par étape
# Guide : Installer et utiliser DeepSeek-R1 avec Ollama
# 1. Installer Ollama
# Rendez-vous sur le site d'Ollama, téléchargez et installez la version pour votre système d'exploitation :
# https://ollama.ai/
# 2. Télécharger le modèle DeepSeek-R1
# Ouvrez votre terminal et exécutez la commande ci-dessous pour télécharger le modèle
# (en utilisant la version 7B comme exemple) :
ollama run deepseek-r1:7b
# Attendez la fin du téléchargement. Le temps nécessaire dépendra de votre vitesse de connexion.
# 3. Vérifier l'installation et lancer le modèle
# Vérifiez que le modèle a bien été téléchargé :
ollama list
# Assurez-vous que "deepseek-r1" apparaît dans la liste.
# Lancez la version 32B du modèle :
ollama run deepseek-r1:32b
# 4. Exemples d'utilisation
# Poser une question :
>>> "Explique l'informatique quantique en termes simples."
# Générer du code :
>>> "Écris une fonction Python pour calculer la suite de Fibonacci."
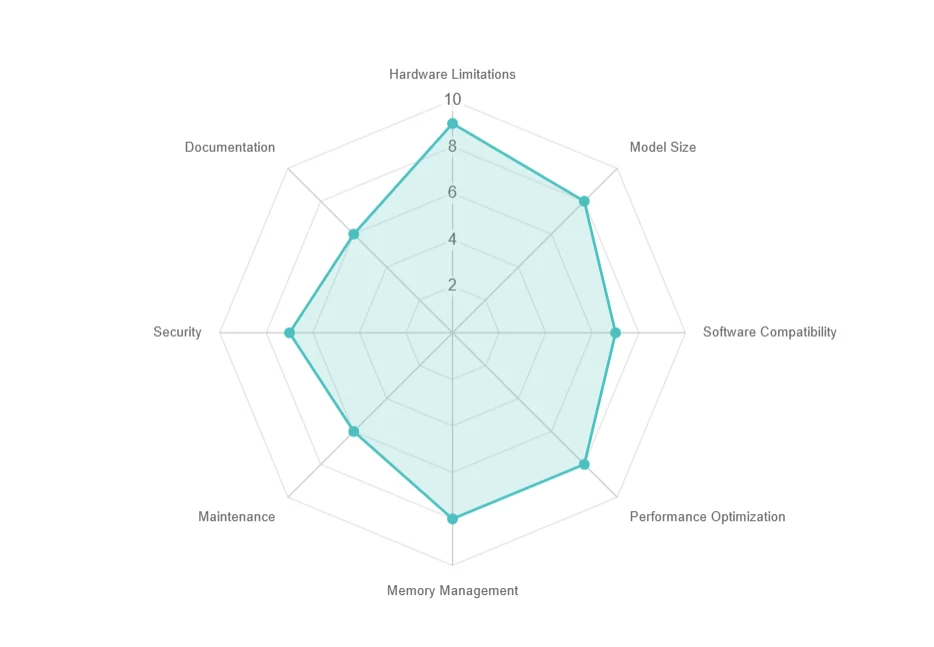
Défis du déploiement local
- Limitations matérielles : Besoins élevés en ressources, mises à niveau coûteuses.
- Taille du modèle : Stockage important (ex. 70+ Go), téléchargements lents.
- Compatibilité logicielle : Problèmes de dépendances et de système d’exploitation.
- Optimisation des performances : Défis de latence, de batch et de parallélisme.
- Gestion de la mémoire : Limites de mémoire GPU et compromis d’exécution hors mémoire.
- Maintenance : Mises à jour fréquentes et problèmes de compatibilité.
- Sécurité : Garantir la confidentialité des données dans les environnements locaux.
- Documentation : Support limité et difficultés de dépannage.
Comment accéder à Deepseek R1 Distill Qwen 32B via Novita AI
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen facile de déployer des modèles d’IA à l’aide de notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour construire et faire évoluer.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez la démo de Deepseek R1 Distill Qwen 32B maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Débutez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. Entrez dans la page “Paramètres” et copiez la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Quelles méthodes vous conviennent ?

Le modèle DeepSeek R1 Distill Qwen 32B est un modèle de langage local de pointe offrant des performances supérieures dans le suivi des instructions, la gestion des données structurées et le support multilingue. Son fine-tuning avec DeepSeek R1 comme enseignant garantit l’efficacité, ce qui le rend adapté aux chercheurs, développeurs et entreprises. Malgré ses besoins matériels, il offre un équilibre entre performance et accessibilité, excellant dans des benchmarks comme AIME 2024 et SWE-bench Verified.
Questions fréquentes
Quelles sont les principales caractéristiques de DeepSeek R1 Distill Qwen 32B ?
Support multilingue pour plus de 29 langues.
Gère les textes longs (8K+ tokens) et les données structurées comme JSON.
Prend en charge les transformations texte-texte et les scénarios avancés de jeu de rôle.
Quels benchmarks mettent en évidence ses performances ?
AIME 2024 : 72,6 % de précision (surpasse OpenAI-o1-mini).
SWE-bench Verified : 49,2 % de précision (en avance sur Llama-70B).
Performances constantes sur d’autres benchmarks comme MATH-500 et MMLU.
Quels sont les besoins matériels ?
Taille du modèle : 73,21 Go.
GPU recommandés : 1 × H100 (80 Go) ou A100 (80 Go).
2 × L40s (96 Go) ou 4 × RTX 4090 (96 Go).
Novita AI est la plateforme cloud tout-en-un qui propulse vos ambitions en IA. API intégrées, serverless, instance GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



