

- Introducción básica a Deepseek R1 Distill Qwen 32B
- Información básica
- Soporte de idiomas
- Aspectos destacados
- Capacidad multimodal
- Entrenamiento
- Cómo acceder a Deepseek R1 Distill Qwen 32B localmente
- Desafíos en la implementación local
- Cómo acceder a Deepseek R1 Distill Qwen 32B a través de Novita AI
- ¿Qué métodos son adecuados para ti?
Aspectos destacados
Potente pero eficiente: iguala el rendimiento de modelos más grandes con menores necesidades de recursos.
Líder en benchmarks: sobresale en AIME 2024 y SWE-bench Verified, superando a OpenAI-o1-mini.
Soporte multilingüe: maneja más de 29 idiomas, incluidos chino, inglés y francés.
Funciones avanzadas: admite textos largos (más de 8K tokens), salidas estructuradas y escenarios de juego de roles.
Fácil acceso: disponible a través de Ollama para implementación local o Novita AI API para integración.
Recomienda a tus amigos Novita AI y ambos ganaréis $10 en créditos de API de LLM, hasta $500 en recompensas totales.
Para apoyar a la comunidad de desarrolladores, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B y Qwen 3 4B están disponibles actualmente de forma gratuita en Novita AI.

El DeepSeek R1 Distill Qwen 32B es un modelo destilado de vanguardia que ofrece el poder de modelos más grandes con requisitos de hardware significativamente menores. Su arquitectura ajustada ofrece un rendimiento superior, superando consistentemente a modelos como OpenAI-o1-mini en benchmarks. Diseñado para eficiencia y accesibilidad, admite implementación local e integración perfecta con API, lo que lo hace ideal para desarrolladores, investigadores y empresas.
Introducción básica a Deepseek R1 Distill Qwen 32B
Información básica
Tamaño del modelo
32.8B
Código abierto
Sí
Arquitectura
Transformer
Soporte de idiomas
Soporte multilingüe para más de 29 idiomas, incluyendo:
Chino, Inglés, Francés, Español, Portugués, Alemán, Italiano, Ruso, Japonés, Coreano, Vietnamita, Tailandés, Árabe y más…
Aspectos destacados
- Mejoras significativas en el seguimiento de instrucciones y generación de textos largos (más de 8K tokens).
- Comprensión mejorada de datos estructurados (ej. tablas) y generación de salidas estructuradas, especialmente JSON.
- Mayor resistencia a indicaciones de sistema diversas, mejorando la implementación de juegos de roles y la configuración de condiciones para chatbots.
Capacidad multimodal
Admite transformaciones de texto a texto.
Entrenamiento
Ajuste fino de Qwen 2.5 32B con DeepSeek R1 como maestro para lograr un rendimiento similar al de modelos más grandes.
DeepSeek realmente ha hecho algo especial al destilar el gran modelo R1 en otros modelos de código abierto. Especialmente la fusión con Qwen-32B parece generar ganancias increíbles en todos los benchmarks y lo convierte en el modelo de referencia para personas con menos VRAM, dando prácticamente los mejores resultados generales en comparación con el destilado de Llama-70B. Actualmente es el SOTA para LLMs locales, y debería ser bastante eficiente incluso en hardware de consumo.
Benchmark
| Benchmark | DeepSeek-R1-32B | OpenAI-o1-mini | Otro modelo |
|---|---|---|---|
| AIME 2024 | 72.6% | 63.6% | Llama-70B: 70.0%, QwQ-32B: 50.0% |
| Codeforces | 71.5% | 60.0% | Llama-70B: 57.5%, QwQ-32B: 54.5% |
| GPQA Diamond | 62.1% | 60.0% | Llama-70B: 65.2%, QwQ-32B: 54.5% |
| MATH-500 | 75.7% | 90.0% | Llama-70B: 94.5%, QwQ-32B: 90.6% |
| MMLU | 90.8% | 88.5% | Llama-70B: 91.8%, QwQ-32B: 90.6% |
| SWE-bench Verified | 49.2% | 36.8% | Llama-70B: 57.5%, QwQ-32B: 41.6% |
Deepseek R1 Distill Qwen 32B sobresale en AIME 2024 y SWE-bench Verified, supera ligeramente a OpenAI-o1-mini en algunas tareas, pero en general va por detrás de modelos más grandes como Deepseek R1 Llama 70B en benchmarks que requieren razonamiento avanzado o capacidades matemáticas.
Cómo acceder a Deepseek R1 Distill Qwen 32B localmente
Requisitos de hardware
Tamaño del modelo: 73.21 GB
- 1 × H100 (80GB): GPU de alto rendimiento para entrenamiento.
- 1 × A100 (80GB): GPU de alta memoria para grandes conjuntos de datos.
- 2 × L40s (96GB): GPUs de inferencia avanzadas con memoria mejorada.
- 4 × RTX 4090 (96GB): GPUs de alta potencia para tareas distribuidas.
Guía de instalación paso a paso
# Guía: Instalar y usar DeepSeek-R1 con Ollama
# 1. Instalar Ollama
# Visita el sitio web de Ollama, descarga e instala la versión para tu SO:
# https://ollama.ai/
# 2. Descargar el modelo DeepSeek-R1
# Abre tu terminal y ejecuta el comando a continuación para descargar el modelo
# (usando la versión de 7B parámetros como ejemplo):
ollama run deepseek-r1:7b
# Espera a que se complete la descarga. El tiempo requerido dependerá de tu velocidad de red.
# 3. Verificar la instalación e iniciar el modelo
# Verifica que el modelo se haya descargado correctamente:
ollama list
# Asegúrate de que "deepseek-r1" aparezca en la lista.
# Inicia la versión de 32B del modelo:
ollama run deepseek-r1:32b
# 4. Ejemplos de uso
# Haz una consulta:
>>> "Explica la computación cuántica en términos simples."
# Genera código:
>>> "Escribe una función en Python para calcular la secuencia de Fibonacci."
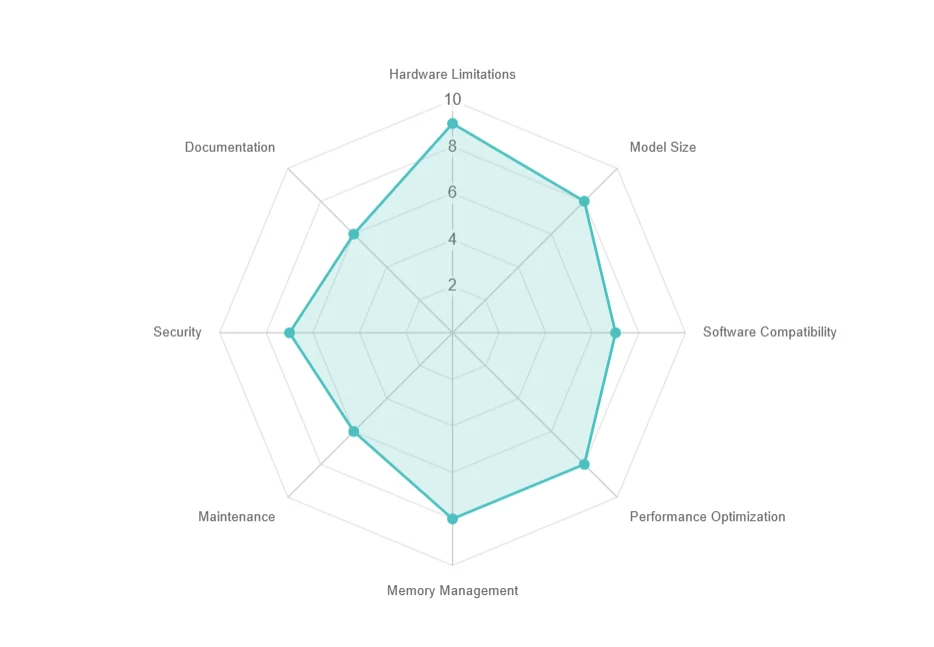
Desafíos en la implementación local
- Limitaciones de hardware: Altos requisitos de recursos, actualizaciones costosas.
- Tamaño del modelo: Gran almacenamiento (ej. más de 70 GB), descargas lentas.
- Compatibilidad de software: Problemas de dependencias y SO.
- Optimización del rendimiento: Desafíos de latencia, procesamiento por lotes y paralelismo.
- Gestión de memoria: Límites de memoria GPU y compensaciones de ejecución fuera del núcleo.
- Mantenimiento: Actualizaciones frecuentes y problemas de compatibilidad.
- Seguridad: Garantizar la privacidad de los datos en entornos locales.
- Documentación: Soporte limitado y dificultades para solucionar problemas.
Cómo acceder a Deepseek R1 Distill Qwen 32B a través de Novita AI
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

¡Prueba ahora el demo de Deepseek R1 Distill Qwen 32B!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Entrando a la página de “Configuración”, puedes copiar la clave API como se indica en la imagen.

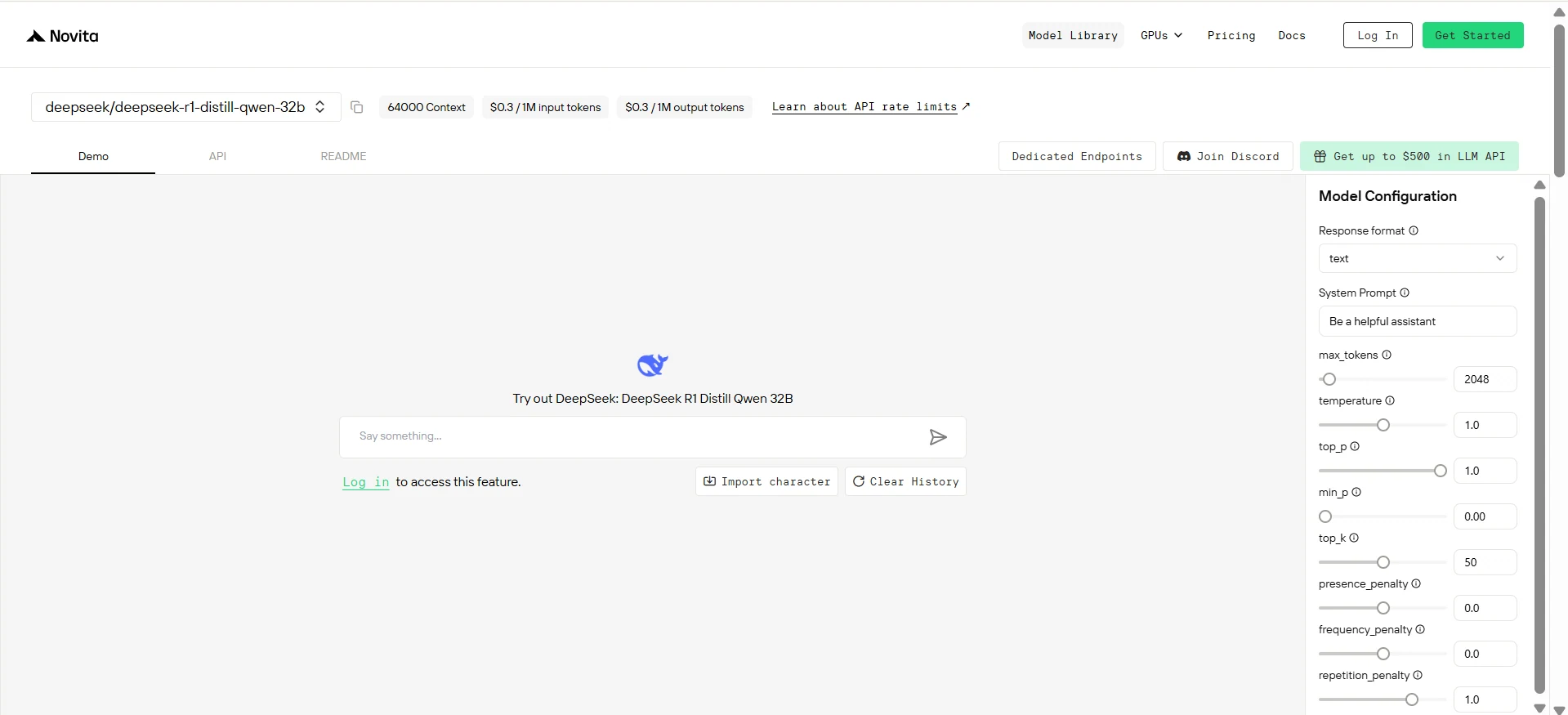
Paso 5: Instala la API
Instala la API utilizando el gestor de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
¿Qué métodos son adecuados para ti?

El modelo DeepSeek R1 Distill Qwen 32B es un modelo de lenguaje local de última generación que ofrece un rendimiento superior en el seguimiento de instrucciones, manejo de datos estructurados y soporte multilingüe. Su ajuste fino con DeepSeek R1 como maestro garantiza eficiencia, lo que lo hace adecuado para investigadores, desarrolladores y empresas. A pesar de sus requisitos de hardware, proporciona un equilibrio entre rendimiento y accesibilidad, destacando en benchmarks como AIME 2024 y SWE-bench Verified.
Preguntas frecuentes
¿Cuáles son las características principales de DeepSeek R1 Distill Qwen 32B?
Soporte multilingüe para más de 29 idiomas.
Maneja textos largos (más de 8K tokens) y datos estructurados como JSON.
Admite transformaciones de texto a texto y escenarios avanzados de juego de roles.
¿Qué benchmarks destacan su rendimiento?
AIME 2024: 72.6% de precisión (supera a OpenAI-o1-mini).
SWE-bench Verified: 49.2% de precisión (por delante de Llama-70B).
Rendimiento consistente en otros benchmarks como MATH-500 y MMLU.
¿Cuáles son los requisitos de hardware?
Tamaño del modelo: 73.21 GB.
GPUs recomendadas: 1 × H100 (80GB) o A100 (80GB).
2 × L40s (96GB) o 4 × RTX 4090 (96GB).
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. APIs integradas, serverless, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



