

- Deepseek R1 Distill Qwen 32B Grundlegende Einführung
- Basisinformationen
- Sprachunterstützung
- Wichtige Highlights
- Multimodale Fähigkeiten
- Training
- So greifen Sie lokal auf Deepseek R1 Distill Qwen 32B zu
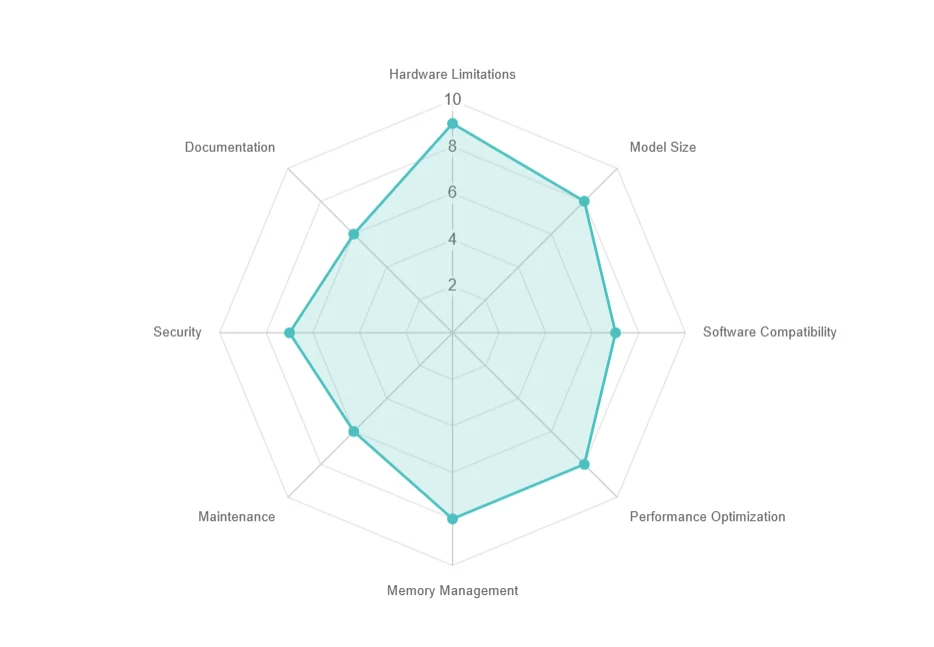
- Herausforderungen bei der lokalen Bereitstellung
- So greifen Sie über Novita AI auf Deepseek R1 Distill Qwen 32B zu
- Welche Methoden sind für Sie geeignet?
Wichtige Highlights
Leistungsstark und dennoch effizient: Übertrifft die Leistung größerer Modelle mit geringerem Ressourcenbedarf.
Benchmark-Führer: Hervorragend in AIME 2024 und SWE-bench Verified, übertrifft OpenAI-o1-mini.
Mehrsprachige Unterstützung: Verarbeitet 29+ Sprachen, darunter Chinesisch, Englisch und Französisch.
Erweiterte Funktionen: Unterstützt lange Texte (8K+ Tokens), strukturierte Ausgaben und Rollenspielszenarien.
Einfacher Zugang: Verfügbar über Ollama für lokale Bereitstellung oder Novita AI API zur Integration.
Empfehlen Sie Ihren Freunden Novita AI weiter, und Sie beide erhalten $10 an LLM-API-Guthaben – bis zu $500 Gesamtbelohnungen.
Um die Entwicklercommunity zu unterstützen, sind Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B derzeit kostenlos auf Novita AI verfügbar.

Der DeepSeek R1 Distill Qwen 32B ist ein hochmodernes destilliertes Modell, das die Leistung größerer Modelle mit deutlich geringeren Hardwareanforderungen bietet. Seine feinabgestimmte Architektur liefert überlegene Leistung und übertrifft in Benchmarks konsequent Modelle wie OpenAI-o1-mini. Entwickelt für Effizienz und Zugänglichkeit, unterstützt es lokale Bereitstellung und nahtlose API-Integration, was es ideal für Entwickler, Forscher und Unternehmen gleichermaßen macht.
Deepseek R1 Distill Qwen 32B Grundlegende Einführung
Basisinformationen
Modellgröße
32,8B
Open Source
Ja
Architektur
Transformer
Sprachunterstützung
Mehrsprachige Unterstützung für über 29 Sprachen, darunter:
Chinesisch Englisch Französisch Spanisch Portugiesisch Deutsch Italienisch Russisch Japanisch Koreanisch Vietnamesisch Thailändisch Arabisch und mehr…
Wichtige Highlights
- Deutliche Verbesserungen bei der Befehlsbefolgung und der Generierung langer Texte (über 8K Tokens).
- Verbessertes Verständnis strukturierter Daten (z. B. Tabellen) und Generierung strukturierter Ausgaben, insbesondere JSON.
- Höhere Robustheit gegenüber verschiedenen Systemaufforderungen, Verbesserung der Rollenspielumsetzung und der Bedingungssetzung für Chatbots.
Multimodale Fähigkeiten
Unterstützt Text-zu-Text-Transformationen.
Training
Feinabstimmung von Qwen 2.5 32B mit DeepSeek R1 als Lehrer, um eine ähnliche Leistung wie größere Modelle zu erzielen.
DeepSeek hat wirklich etwas Besonderes mit der Destillation des großen R1-Modells in andere Open-Source-Modelle erreicht. Insbesondere die Fusion mit Qwen-32B scheint massive Steigerungen in den Benchmarks zu liefern und macht es zum bevorzugten Modell für Leute mit weniger VRAM, da es insgesamt die besten Ergebnisse im Vergleich zur Llama-70B-Destillation liefert. Derzeit der SOTA für lokale LLMs, und es sollte selbst auf Consumer-Hardware recht leistungsfähig sein.
Benchmark
| Benchmark | DeepSeek-R1-32B | OpenAI-o1-mini | Anderes Modell |
|---|---|---|---|
| AIME 2024 | 72,6% | 63,6% | Llama-70B: 70,0%, QwQ-32B: 50,0% |
| Codeforces | 71,5% | 60,0% | Llama-70B: 57,5%, QwQ-32B: 54,5% |
| GPQA Diamond | 62,1% | 60,0% | Llama-70B: 65,2%, QwQ-32B: 54,5% |
| MATH-500 | 75,7% | 90,0% | Llama-70B: 94,5%, QwQ-32B: 90,6% |
| MMLU | 90,8% | 88,5% | Llama-70B: 91,8%, QwQ-32B: 90,6% |
| SWE-bench Verified | 49,2% | 36,8% | Llama-70B: 57,5%, QwQ-32B: 41,6% |
Deepseek R1 Distill Qwen 32B zeichnet sich in AIME 2024 und SWE-bench Verified aus, übertrifft OpenAI-o1-mini bei einigen Aufgaben leicht, bleibt aber in Benchmarks, die fortgeschrittene Argumentations- oder Mathematikfähigkeiten erfordern, im Allgemeinen hinter größeren Modellen wie Deepseek R1 Llama 70B zurück.
So greifen Sie lokal auf Deepseek R1 Distill Qwen 32B zu
Hardware-Anforderungen
Modellgröße: 73,21 GB
- 1 × H100 (80GB): Hochleistungs-GPU für Training.
- 1 × A100 (80GB): Hochspeicher-GPU für große Datensätze.
- 2 × L40s (96GB): Fortschrittliche Inferenz-GPUs mit erweitertem Speicher.
- 4 × RTX 4090 (96GB): Leistungsstarke GPUs für verteilte Aufgaben.
Schritt-für-Schritt-Installationsanleitung
# Guide: Install and Use DeepSeek-R1 with Ollama
# 1. Install Ollama
# Visit the Ollama website, download and install the version for your OS:
# https://ollama.ai/
# 2. Download the DeepSeek-R1 Model
# Open your terminal and run the command below to download the model
# (using the 7B parameter version as an example):
ollama run deepseek-r1:7b
# Wait for the download to complete. The time required will depend on your network speed.
# 3. Verify Installation and Start the Model
# Verify that the model has been successfully downloaded:
ollama list
# Ensure "deepseek-r1" appears in the list.
# Start the 32B version of the model:
ollama run deepseek-r1:32b
# 4. Usage Examples
# Ask a query:
>>> "Explain quantum computing in simple terms."
# Generate code:
>>> "Write a Python function to calculate the Fibonacci sequence."
Herausforderungen bei der lokalen Bereitstellung
- Hardware-Einschränkungen: Hoher Ressourcenbedarf, teure Upgrades.
- Modellgröße: Großer Speicherbedarf (z. B. 70+ GB), langsame Downloads.
- Software-Kompatibilität: Abhängigkeits- und Betriebssystemprobleme.
- Leistungsoptimierung: Latenz-, Batching- und Parallelitätsprobleme.
- Speicherverwaltung: GPU-Speichergrenzen und Kompromisse bei der Ausführung außerhalb des Speichers.
- Wartung: Häufige Updates und Kompatibilitätsprobleme.
- Sicherheit: Gewährleistung des Datenschutzes in lokalen Umgebungen.
- Dokumentation: Begrenzte Unterstützung und Probleme bei der Fehlerbehebung.
So greifen Sie über Novita AI auf Deepseek R1 Distill Qwen 32B zu
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbauen und Skalieren bereitstellt.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Testen Sie Deepseek R1 Distill Qwen 32B Demo jetzt!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Welche Methoden sind für Sie geeignet?

Das DeepSeek R1 Distill Qwen 32B-Modell ist ein hochmodernes lokales Sprachmodell, das überlegene Leistung bei der Befehlsbefolgung, der Verarbeitung strukturierter Daten und der mehrsprachigen Unterstützung bietet. Die Feinabstimmung mit DeepSeek R1 als Lehrer gewährleistet Effizienz, was es für Forscher, Entwickler und Unternehmen geeignet macht. Trotz der Hardwareanforderungen bietet es ein Gleichgewicht zwischen Leistung und Zugänglichkeit und zeichnet sich in Benchmarks wie AIME 2024 und SWE-bench Verified aus.
Häufig gestellte Fragen
Was sind die wichtigsten Funktionen von DeepSeek R1 Distill Qwen 32B?
Mehrsprachige Unterstützung für 29+ Sprachen.
Verarbeitet lange Texte (8K+ Tokens) und strukturierte Daten wie JSON.
Unterstützt Text-zu-Text-Transformationen und fortgeschrittene Rollenspielszenarien.
Welche Benchmarks heben seine Leistung hervor?
AIME 2024: 72,6% Genauigkeit (übertrifft OpenAI-o1-mini).
SWE-bench Verified: 49,2% Genauigkeit (vor Llama-70B).
Konsequente Leistung in anderen Benchmarks wie MATH-500 und MMLU.
Was sind die Hardware-Anforderungen?
Modellgröße: 73,21 GB.
Empfohlene GPUs: 1 × H100 (80GB) oder A100 (80GB).
2 × L40s (96GB) oder 4 × RTX 4090 (96GB).
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlos, GPU-Instanz — die kostengünstigen Tools, die Sie benötigen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



