

- Deepseek R1 Distill Qwen 32B: базовое введение
- Основная информация
- Поддержка языков
- Ключевые особенности
- Мультимодальные возможности
- Обучение
- Как получить доступ к Deepseek R1 Distill Qwen 32B локально
- Проблемы при локальном развертывании
- Как получить доступ к Deepseek R1 Distill Qwen 32B через Novita AI
- Какой метод подходит вам?
Ключевые моменты
Мощная и эффективная: Соответствует производительности более крупных моделей при меньших затратах ресурсов.
Лидер бенчмарков: Превосходит OpenAI-o1-mini в тестах AIME 2024 и SWE-bench Verified.
Мультиязычная поддержка: Работает с 29+ языками, включая китайский, английский и французский.
Продвинутые функции: Поддерживает длинные тексты (8K+ токенов), структурированные выходные данные и сценарии ролевых игр.
Простой доступ: Доступна через Ollama для локального развертывания или через Novita AI API для интеграции.
Приглашайте друзей в Novita AI, и вы оба получите по $10 на LLM API — до $500 суммарного вознаграждения.
В поддержку сообщества разработчиков Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B сейчас доступны бесплатно на Novita AI.

DeepSeek R1 Distill Qwen 32B — это передовая дистиллированная модель, которая предлагает мощность более крупных моделей при значительно меньших требованиях к оборудованию. Её тонко настроенная архитектура обеспечивает превосходную производительность, стабильно превосходя такие модели, как OpenAI-o1-mini, в бенчмарках. Разработанная для эффективности и доступности, она поддерживает локальное развертывание и бесшовную интеграцию через API, что делает её идеальной для разработчиков, исследователей и бизнеса.
Deepseek R1 Distill Qwen 32B: базовое введение
Основная информация
Размер модели
32.8B
Открытый исходный код
Да
Архитектура
Transformer
Поддержка языков
Мультиязычная поддержка для более чем 29 языков, включая:
китайский, английский, французский, испанский, португальский, немецкий, итальянский, русский, японский, корейский, вьетнамский, тайский, арабский и другие…
Ключевые особенности
- Значительные улучшения в следовании инструкциям и генерации длинных текстов (более 8K токенов).
- Улучшенное понимание структурированных данных (например, таблиц) и генерация структурированных выходных данных, особенно JSON.
- Повышенная устойчивость к разнообразным системным промптам, улучшающая реализацию ролевых игр и настройку условий для чат-ботов.
Мультимодальные возможности
Поддерживает преобразования текст-текст.
Обучение
Тонкая настройка Qwen 2.5 32B с DeepSeek R1 в качестве учителя для достижения производительности, аналогичной более крупным моделям.
DeepSeek действительно сделал кое-что особенное, дистиллировав большую модель R1 в другие open-source модели. Особенно слияние с Qwen-32B, похоже, даёт невероятный прирост в бенчмарках и делает её лучшей моделью для людей с меньшим объёмом VRAM, обеспечивая в целом лучшие результаты по сравнению с дистилляцией Llama-70B. На данный момент это SOTA для локальных LLM, и она должна быть достаточно производительной даже на потребительском оборудовании.
Бенчмарки
| Бенчмарк | DeepSeek-R1-32B | OpenAI-o1-mini | Другая модель |
|---|---|---|---|
| AIME 2024 | 72.6% | 63.6% | Llama-70B: 70.0%, QwQ-32B: 50.0% |
| Codeforces | 71.5% | 60.0% | Llama-70B: 57.5%, QwQ-32B: 54.5% |
| GPQA Diamond | 62.1% | 60.0% | Llama-70B: 65.2%, QwQ-32B: 54.5% |
| MATH-500 | 75.7% | 90.0% | Llama-70B: 94.5%, QwQ-32B: 90.6% |
| MMLU | 90.8% | 88.5% | Llama-70B: 91.8%, QwQ-32B: 90.6% |
| SWE-bench Verified | 49.2% | 36.8% | Llama-70B: 57.5%, QwQ-32B: 41.6% |
Deepseek R1 Distill Qwen 32B превосходит другие модели в AIME 2024 и SWE-bench Verified, немного опережая OpenAI-o1-mini в некоторых задачах, но в целом уступает более крупным моделям, таким как Deepseek R1 Llama 70B, в бенчмарках, требующих продвинутых рассуждений или математических способностей.
Как получить доступ к Deepseek R1 Distill Qwen 32B локально
Требования к оборудованию
Размер модели: 73.21 GB
- 1 × H100 (80GB): Высокопроизводительный GPU для обучения.
- 1 × A100 (80GB): Высокопроизводительный GPU с большим объёмом памяти для больших наборов данных.
- 2 × L40s (96GB): Продвинутые GPU для инференса с увеличенной памятью.
- 4 × RTX 4090 (96GB): Мощные GPU для распределённых задач.
Пошаговая инструкция по установке
# Guide: Install and Use DeepSeek-R1 with Ollama
# 1. Install Ollama
# Visit the Ollama website, download and install the version for your OS:
# https://ollama.ai/
# 2. Download the DeepSeek-R1 Model
# Open your terminal and run the command below to download the model
# (using the 7B parameter version as an example):
ollama run deepseek-r1:7b
# Wait for the download to complete. The time required will depend on your network speed.
# 3. Verify Installation and Start the Model
# Verify that the model has been successfully downloaded:
ollama list
# Ensure "deepseek-r1" appears in the list.
# Start the 32B version of the model:
ollama run deepseek-r1:32b
# 4. Usage Examples
# Ask a query:
>>> "Explain quantum computing in simple terms."
# Generate code:
>>> "Write a Python function to calculate the Fibonacci sequence."
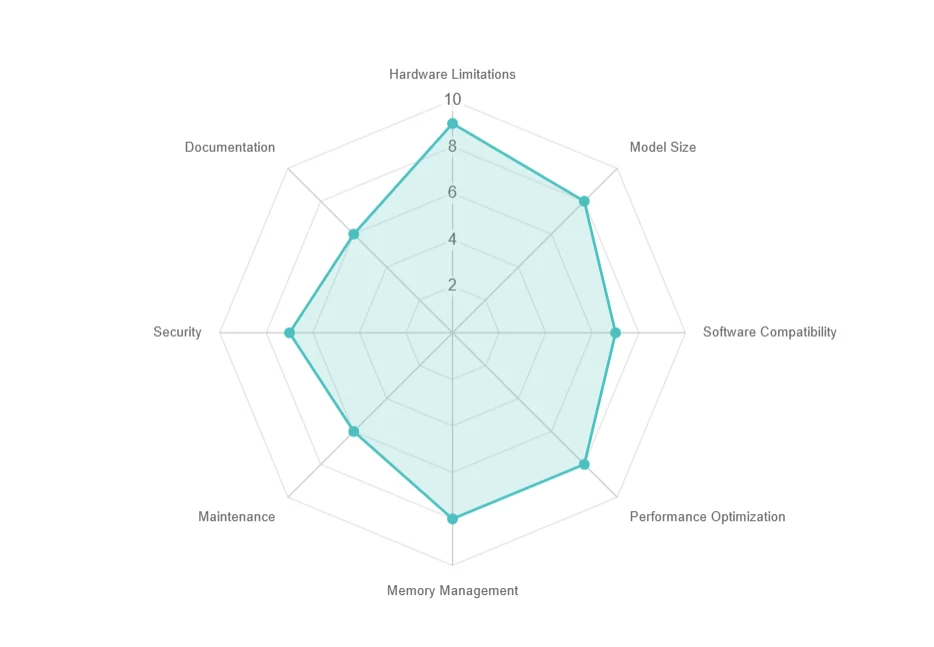
Проблемы при локальном развертывании
- Ограничения оборудования: Высокие требования к ресурсам, дорогостоящее обновление.
- Размер модели: Большой объём хранилища (например, 70+ ГБ), медленная загрузка.
- Совместимость ПО: Проблемы с зависимостями и операционной системой.
- Оптимизация производительности: Задержки, пакетная обработка и проблемы с параллелизмом.
- Управление памятью: Ограничения памяти GPU и компромиссы при выполнении вне ядра.
- Обслуживание: Частые обновления и проблемы совместимости.
- Безопасность: Обеспечение конфиденциальности данных в локальных средах.
- Документация: Ограниченная поддержка и трудности с устранением неполадок.
Как получить доступ к Deepseek R1 Distill Qwen 32B через Novita AI
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также доступный и надёжный GPU-облачный сервис для создания и масштабирования.
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library.

Попробовать Deepseek R1 Distill Qwen 32B Demo сейчас!
Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших задач.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдите на страницу “Settings” и скопируйте API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Ниже приведён пример использования API чатов для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Какой метод подходит вам?

Модель DeepSeek R1 Distill Qwen 32B — это современная локальная языковая модель, обеспечивающая превосходную производительность в следовании инструкциям, обработке структурированных данных и мультиязычной поддержке. Её тонкая настройка с DeepSeek R1 в качестве учителя гарантирует эффективность, что делает её подходящей для исследователей, разработчиков и бизнеса. Несмотря на требования к оборудованию, она обеспечивает баланс между производительностью и доступностью, превосходя другие модели в таких бенчмарках, как AIME 2024 и SWE-bench Verified.
Часто задаваемые вопросы
Каковы ключевые особенности DeepSeek R1 Distill Qwen 32B?
Мультиязычная поддержка для более чем 29 языков.
Работа с длинными текстами (8K+ токенов) и структурированными данными, такими как JSON.
Поддержка преобразований текст-текст и продвинутых сценариев ролевых игр.
В каких бенчмарках она показывает высокую производительность?
AIME 2024: точность 72.6% (превосходит OpenAI-o1-mini).
SWE-bench Verified: точность 49.2% (опережает Llama-70B).
Стабильная производительность в других бенчмарках, таких как MATH-500 и MMLU.
Каковы требования к оборудованию?
Размер модели: 73.21 GB.
Рекомендуемые GPU: 1 × H100 (80GB) или A100 (80GB).
2 × L40s (96GB) или 4 × RTX 4090 (96GB).
Novita AI — это универсальная облачная платформа, которая реализует ваши AI-амбиции. Интегрированные API, Serverless, GPU-инстансы — экономичные инструменты, которые вам нужны. Избавьтесь от инфраструктурных забот, начните бесплатно и воплотите ваше AI-видение в реальность.



