

主なハイライト
高性能かつ効率的: リソース要求を抑えながら、より大規模なモデルと同等のパフォーマンスを実現。
ベンチマークトップ: AIME 2024 や SWE-bench Verified で優れた成績を収め、OpenAI-o1-mini を上回る。
多言語対応: 中国語、英語、フランス語を含む29言語以上に対応。
高度な機能: 長文(8Kトークン以上)対応、構造化出力、ロールプレイシナリオをサポート。
**簡単にアクセス **: ローカルデプロイには Ollama、統合には Novita AI API が利用可能。
友達を Novita AI に紹介すると、あなたと友達の両方が LLM API クレジットとして $10 を獲得できます。最大 $500 まで貯められます。
開発者コミュニティを支援するため、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B は現在 Novita AI で無料でご利用いただけます。

DeepSeek R1 Distill Qwen 32B は、大規模モデルのパワーを大幅に低いハードウェア要件で提供する最先端の蒸留モデルです。微調整されたアーキテクチャにより優れたパフォーマンスを発揮し、ベンチマークでは OpenAI-o1-mini などのモデルを一貫して上回ります。効率性とアクセスのしやすさを重視して設計されており、ローカルデプロイとシームレスな API 統合の両方をサポートするため、開発者、研究者、企業に最適です。
Deepseek R1 Distill Qwen 32B の基本情報
基本情報
モデルサイズ
32.8B
オープンソース
はい
アーキテクチャ
Transformer
言語サポート
29以上の多言語対応。以下を含みます:
中国語 英語 フランス語 スペイン語 ポルトガル語 ドイツ語 イタリア語 ロシア語 日本語 韓国語 ベトナム語 タイ語 アラビア語 など…
主なハイライト
- 指示追従と長文生成(8Kトークン以上)が大幅に改善。
- 構造化データ(例:表)の理解と、構造化出力(特にJSON)の生成が強化。
- 多様なシステムプロンプトに対する耐性が向上し、チャットボット向けのロールプレイ実装と条件設定が改善。
マルチモーダル機能
テキスト間変換をサポート。
トレーニング
DeepSeek R1 を教師モデルとして Qwen 2.5 32B を微調整し、大規模モデルと同等のパフォーマンスを実現。
DeepSeek は、大規模な R1 モデルを他のオープンソースモデルに蒸留する点で、本当に特別なことを成し遂げました。特に Qwen-32B との融合は、ベンチマーク全体で驚異的な向上をもたらし、VRAM の少ないユーザーにとっての頼りになるモデルとなっています。LLama-70B 蒸留と比較しても、全体的に最も優れた結果をもたらします。現時点でローカル LLM の SOTA であり、一般消費者向けハードウェアでも十分にパフォーマンスを発揮するはずです。
ベンチマーク
| Benchmark | DeepSeek-R1-32B | OpenAI-o1-mini | その他のモデル |
|---|---|---|---|
| AIME 2024 | 72.6% | 63.6% | Llama-70B: 70.0%, QwQ-32B: 50.0% |
| Codeforces | 71.5% | 60.0% | Llama-70B: 57.5%, QwQ-32B: 54.5% |
| GPQA Diamond | 62.1% | 60.0% | Llama-70B: 65.2%, QwQ-32B: 54.5% |
| MATH-500 | 75.7% | 90.0% | Llama-70B: 94.5%, QwQ-32B: 90.6% |
| MMLU | 90.8% | 88.5% | Llama-70B: 91.8%, QwQ-32B: 90.6% |
| SWE-bench Verified | 49.2% | 36.8% | Llama-70B: 57.5%, QwQ-32B: 41.6% |
Deepseek R1 Distill Qwen 32B は AIME 2024 と SWE-bench Verified で優れた成績を収め、一部のタスクでは OpenAI-o1-mini をわずかに上回りますが、高度な推論や数学的能力を必要とするベンチマークでは、全体的に Deepseek R1 Llama 70B のような大規模モデルには及びません。
Deepseek R1 Distill Qwen 32B にローカルでアクセスする方法
ハードウェア要件
モデルサイズ: 73.21 GB
- 1 × H100 (80GB): トレーニング向け高性能GPU。
- 1 × A100 (80GB): 大規模データセット向け大容量GPU。
- 2 × L40s (96GB): 強化メモリ搭載の推論向け先進GPU。
- 4 × RTX 4090 (96GB): 分散タスク向け高出力GPU。
ステップバイステップインストールガイド
# Guide: Install and Use DeepSeek-R1 with Ollama
# 1. Install Ollama
# Visit the Ollama website, download and install the version for your OS:
# https://ollama.ai/
# 2. Download the DeepSeek-R1 Model
# Open your terminal and run the command below to download the model
# (using the 7B parameter version as an example):
ollama run deepseek-r1:7b
# Wait for the download to complete. The time required will depend on your network speed.
# 3. Verify Installation and Start the Model
# Verify that the model has been successfully downloaded:
ollama list
# Ensure "deepseek-r1" appears in the list.
# Start the 32B version of the model:
ollama run deepseek-r1:32b
# 4. Usage Examples
# Ask a query:
>>> "Explain quantum computing in simple terms."
# Generate code:
>>> "Write a Python function to calculate the Fibonacci sequence."
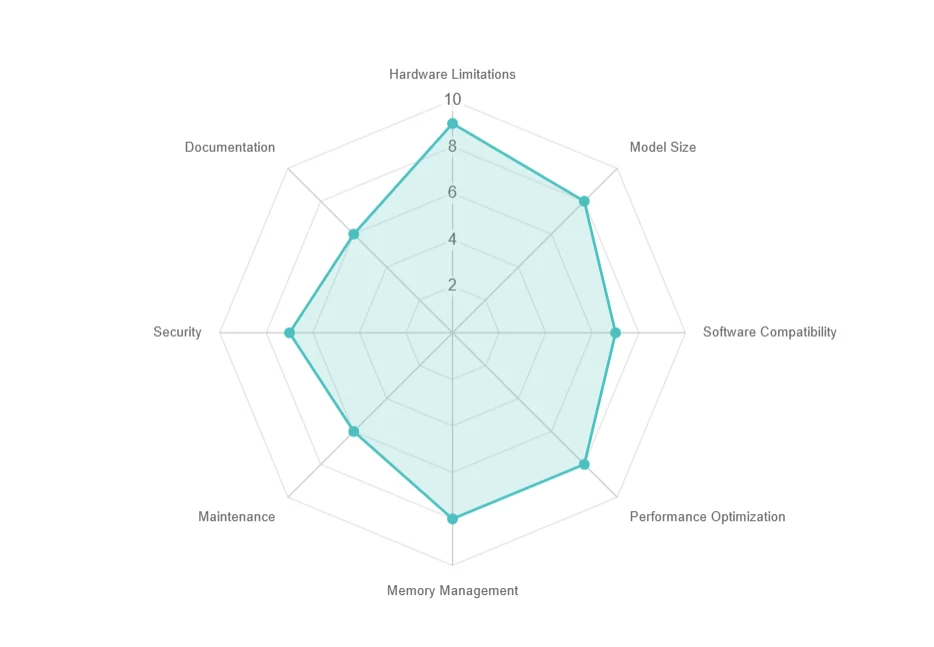
ローカルデプロイの課題
- ハードウェア制限: 高いリソース必要性、高額なアップグレード費用。
- モデルサイズ: 大規模ストレージ(例:70GB以上)、ダウンロードが遅い。
- ソフトウェア互換性: 依存関係やOSの問題。
- パフォーマンス最適化: レイテンシ、バッチ処理、並列処理の課題。
- メモリ管理: GPUメモリ制限とアウトオブコア実行のトレードオフ。
- メンテナンス: 頻繁なアップデートと互換性問題。
- セキュリティ: ローカル環境でのデータプライバシー確保。
- ドキュメント: サポートとトラブルシューティングの限られた情報。
Novita AI 経由で Deepseek R1 Distill Qwen 32B にアクセスする方法
Novita AI は AI クラウドプラットフォームであり、開発者がシンプルな API を使って AI モデルを簡単にデプロイできるとともに、手頃で信頼性の高い GPU クラウドを構築・拡張のために提供します。
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

Deepseek R1 Distill Qwen 32B のデモを今すぐ試す!
ステップ 2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ 3: 無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始します。
ステップ 4: API キーを取得
API での認証のために、新しい API キーを提供します。「設定」ページに移動すると、画像のように API キーをコピーできます。

ステップ 5: API をインストール
プログラミング言語に応じたパッケージマネージャーを使用して API をインストールします。

インストール後、開発環境に必要なライブラリをインポートします。API キーを使って API を初期化し、Novita AI LLM とのやり取りを開始します。以下は、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
どの方法があなたに適していますか?

DeepSeek R1 Distill Qwen 32B モデルは、最先端のローカル言語モデルであり、指示追従、構造化データ処理、多言語サポートにおいて優れたパフォーマンスを提供します。DeepSeek R1 を教師とした微調整により効率性が確保され、研究者、開発者、企業に適しています。ハードウェア要件は高いものの、パフォーマンスとアクセスのしやすさのバランスを提供し、AIME 2024 や SWE-bench Verified などのベンチマークで優れた成績を収めています。
よくある質問
DeepSeek R1 Distill Qwen 32B の主な機能は何ですか?
29以上の言語に対応する多言語サポート。 長文(8Kトークン以上)やJSONなどの構造化データを処理可能。 テキスト間変換や高度なロールプレイシナリオをサポート。
どのベンチマークでそのパフォーマンスが際立っていますか?
AIME 2024: 72.6% の精度(OpenAI-o1-mini を上回る)。 SWE-bench Verified: 49.2% の精度(Llama-70B より優れている)。 MATH-500 や MMLU などの他のベンチマークでも一貫したパフォーマンス。
ハードウェア要件は何ですか?
モデルサイズ: 73.21 GB。 推奨GPU: 1 × H100 (80GB) または A100 (80GB)。 2 × L40s (96GB) または 4 × RTX 4090 (96GB)。
Novita AI は、AI の野心を実現するオールインワンクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャの心配は不要で、無料で始めて、AI ビジョンを現実にしましょう。



