

النقاط الرئيسية
قوي وفعال: يتطابق أداءه مع النماذج الأكبر مع متطلبات موارد أقل.
رائد في المعايير: يتفوق في AIME 2024 وSWE-bench Verified متجاوزًا OpenAI-o1-mini.
دعم متعدد اللغات: يتعامل مع أكثر من 29 لغة، بما في ذلك الصينية والإنجليزية والفرنسية.
ميزات متقدمة: يدعم النصوص الطويلة (أكثر من 8K رمزًا)، والمخرجات المنظمة، وسيناريوهات لعب الأدوار.
سهولة الوصول: متاح عبر Ollama للنشر المحلي أو عبر Novita AI API للتكامل.
قم بإحالة أصدقائك إلى Novita AI وستحصلان معًا على 10 دولارات من أرصدة واجهة برمجة تطبيقات LLM — حتى 500 دولار إجمالي المكافآت.
لدعم مجتمع المطورين، تتوفر نماذج Qwen2.5-7B وQwen 3 0.6B وQwen 3 1.7B وQwen 3 4B مجانًا حاليًا على Novita AI.

DeepSeek R1 Distill Qwen 32B هو نموذج مقطَّع متطور يقدم قوة النماذج الأكبر مع متطلبات أجهزة أقل بكثير. تحقق بنيته المحسَّنة أداءً فائقًا، متجاوزًا باستمرار نماذج مثل OpenAI-o1-mini في المعايير. مصمم للكفاءة وسهولة الوصول، ويدعم النشر المحلي والتكامل السلس عبر واجهة برمجة التطبيقات، مما يجعله مثاليًا للمطورين والباحثين والشركات على حد سواء.
Deepseek R1 Distill Qwen 32B مقدمة أساسية
معلومات أساسية
حجم النموذج
32.8B
مفتوح المصدر
نعم
البنية
Transformer
دعم اللغات
دعم متعدد اللغات لأكثر من 29 لغة، بما في ذلك:
الصينية الإنجليزية الفرنسية الإسبانية البرتغالية الألمانية الإيطالية الروسية اليابانية الكورية الفيتنامية التايلاندية العربية والمزيد…
النقاط الرئيسية
- تحسينات كبيرة في اتباع التعليمات وتوليد النصوص الطويلة (أكثر من 8K رمزًا).
- فهم محسَّن للبيانات المنظمة (مثل الجداول) وتوليد مخرجات منظمة، خاصة JSON.
- أكثر مرونة تجاه مطالبات النظام المتنوعة، مما يحسن تنفيذ لعب الأدوار وتحديد الشروط لروبوتات المحادثة.
القدرة متعددة الوسائط
يدعم تحويلات النص إلى نص.
التدريب
تم ضبط Qwen 2.5 32B بدقة باستخدام DeepSeek R1 كمعلم لتحقيق أداء مماثل للنماذج الأكبر.
لقد قامت DeepSeek حقًا بشيء مميز بتقطير نموذج R1 الكبير إلى نماذج مفتوحة المصدر أخرى. خاصة أن الدمج مع Qwen-32B يبدو أنه يحقق مكاسب هائلة عبر المعايير ويجعله النموذج المفضل للأشخاص الذين لديهم ذاكرة VRAM أقل، مما يعطي أفضل النتائج الإجمالية مقارنة بتقطير Llama-70B. يعتبر حاليًا أفضل نموذج محلي (SOTA) لنماذج LLM المحلية، ومن المفترض أن يكون أداءه جيدًا حتى على الأجهزة الاستهلاكية.
المعايير
| المعيار | DeepSeek-R1-32B | OpenAI-o1-mini | نموذج آخر |
|---|---|---|---|
| AIME 2024 | 72.6% | 63.6% | Llama-70B: 70.0%, QwQ-32B: 50.0% |
| Codeforces | 71.5% | 60.0% | Llama-70B: 57.5%, QwQ-32B: 54.5% |
| GPQA Diamond | 62.1% | 60.0% | Llama-70B: 65.2%, QwQ-32B: 54.5% |
| MATH-500 | 75.7% | 90.0% | Llama-70B: 94.5%, QwQ-32B: 90.6% |
| MMLU | 90.8% | 88.5% | Llama-70B: 91.8%, QwQ-32B: 90.6% |
| SWE-bench Verified | 49.2% | 36.8% | Llama-70B: 57.5%, QwQ-32B: 41.6% |
يتفوق Deepseek R1 Distill Qwen 32B في AIME 2024 و SWE-bench Verified، ويتفوق قليلاً على OpenAI-o1-mini في بعض المهام، لكنه عمومًا يتخلف عن النماذج الأكبر مثل Deepseek R1 Llama 70B في المعايير التي تتطلب تفكيرًا متقدمًا أو قدرات رياضية.
كيفية الوصول إلى Deepseek R1 Distill Qwen 32B محليًا
متطلبات الأجهزة
حجم النموذج: 73.21 جيجابايت
- 1 × H100 (80 جيجابايت): وحدة معالجة رسومية عالية الأداء للتدريب.
- 1 × A100 (80 جيجابايت): وحدة معالجة رسومية عالية الذاكرة لمجموعات البيانات الكبيرة.
- 2 × L40s (96 جيجابايت): وحدات معالجة رسومية متقدمة للاستدلال بذاكرة محسّنة.
- 4 × RTX 4090 (96 جيجابايت): وحدات معالجة رسومية عالية الطاقة للمهام الموزعة.
دليل التثبيت خطوة بخطوة
# Guide: Install and Use DeepSeek-R1 with Ollama
# 1. Install Ollama
# Visit the Ollama website, download and install the version for your OS:
# https://ollama.ai/
# 2. Download the DeepSeek-R1 Model
# Open your terminal and run the command below to download the model
# (using the 7B parameter version as an example):
ollama run deepseek-r1:7b
# Wait for the download to complete. The time required will depend on your network speed.
# 3. Verify Installation and Start the Model
# Verify that the model has been successfully downloaded:
ollama list
# Ensure "deepseek-r1" appears in the list.
# Start the 32B version of the model:
ollama run deepseek-r1:32b
# 4. Usage Examples
# Ask a query:
>>> "Explain quantum computing in simple terms."
# Generate code:
>>> "Write a Python function to calculate the Fibonacci sequence."
تحديات النشر المحلي
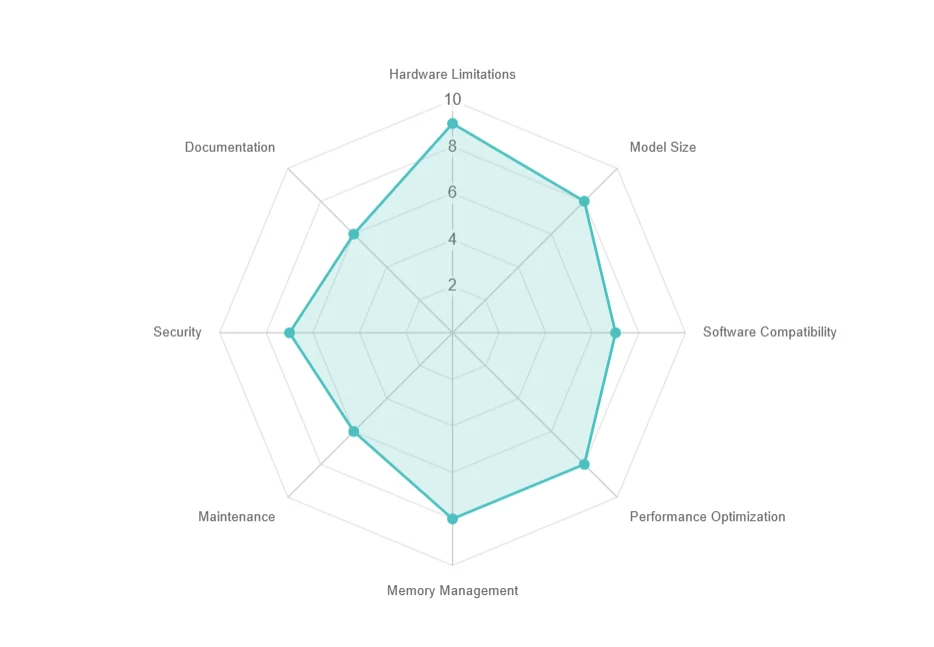
- قيود الأجهزة: احتياجات عالية للموارد، ترقيات مكلفة.
- حجم النموذج: تخزين كبير (مثل 70+ جيجابايت)، تنزيل بطيء.
- توافق البرامج: مشكلات التبعيات وأنظمة التشغيل.
- تحسين الأداء: تحديات زمن الاستجابة، التجميع، والتوازي.
- إدارة الذاكرة: حدود ذاكرة وحدة معالجة الرسوميات ومقايضات التنفيذ خارج الذاكرة.
- الصيانة: تحديثات متكررة ومشكلات التوافق.
- الأمان: ضمان خصوصية البيانات في البيئات المحلية.
- التوثيق: دعم محدود وصعوبات في استكشاف الأخطاء.
كيفية الوصول إلى Deepseek R1 Distill Qwen 32B عبر Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرب Deepseek R1 Distill Qwen 32B الآن!
الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنقدم لك مفتاح API جديدًا. أدخل صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

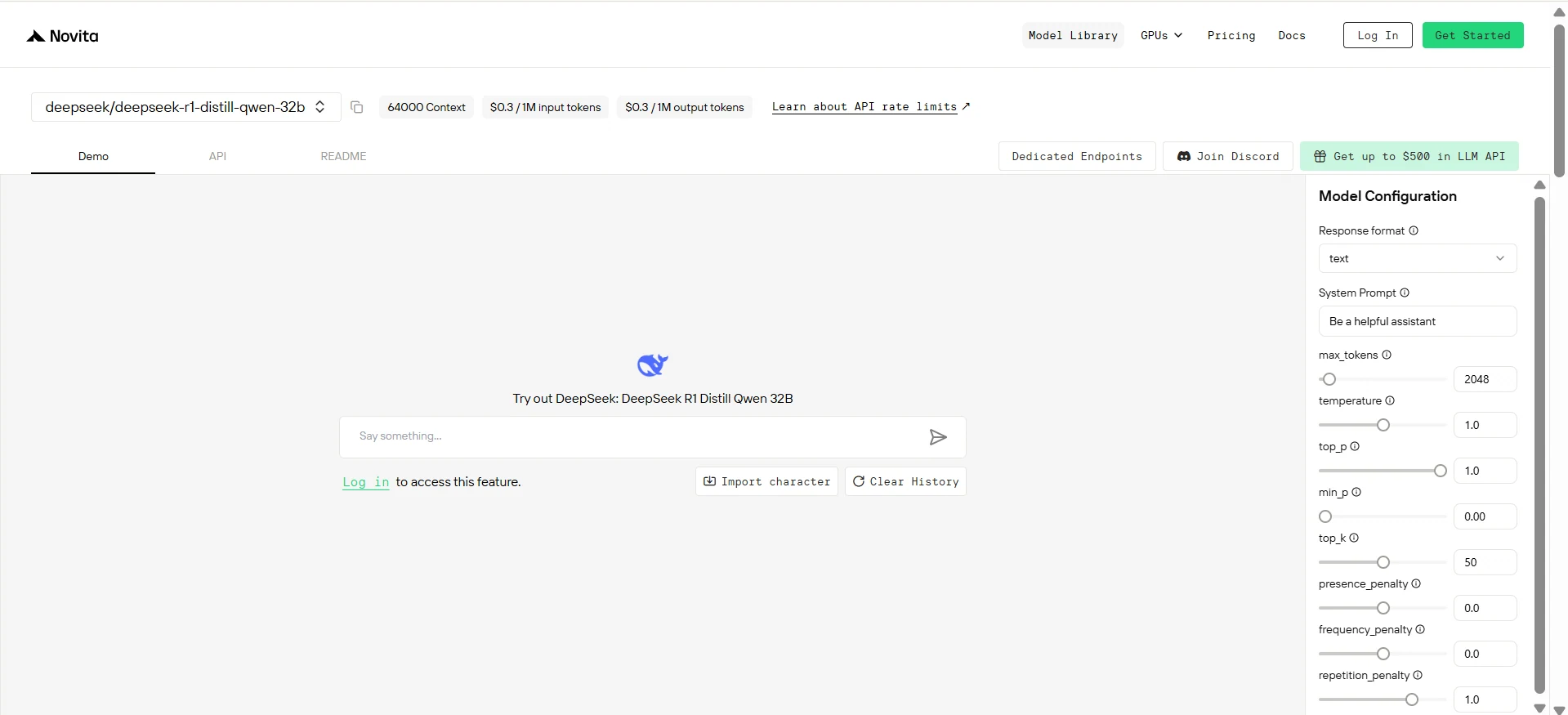
الخطوة 5: تثبيت واجهة برمجة التطبيقات
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.

بعد التثبيت، قم باستيراد المكتبات الضرورية في بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام Chat Completions API لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
أي الطرق مناسبة لك؟

نموذج DeepSeek R1 Distill Qwen 32B هو نموذج لغوي محلي متطور يقدم أداءً فائقًا في اتباع التعليمات، ومعالجة البيانات المنظمة، والدعم متعدد اللغات. يضمن ضبطه الدقيق باستخدام DeepSeek R1 كمعلم الكفاءة، مما يجعله مناسبًا للباحثين والمطورين والشركات. على الرغم من متطلباته من الأجهزة، فإنه يوفر توازنًا بين الأداء وسهولة الوصول، متفوقًا في المعايير مثل AIME 2024 و SWE-bench Verified.
الأسئلة الشائعة
ما هي الميزات الرئيسية لـ DeepSeek R1 Distill Qwen 32B؟
دعم متعدد اللغات لأكثر من 29 لغة.
يتعامل مع النصوص الطويلة (أكثر من 8K رمزًا) والبيانات المنظمة مثل JSON.
يدعم تحويلات النص إلى نص وسيناريوهات لعب الأدوار المتقدمة.
ما هي المعايير التي تبرز أداءه؟
AIME 2024: دقة 72.6٪ (يتفوق على OpenAI-o1-mini).
SWE-bench Verified: دقة 49.2٪ (متقدم على Llama-70B).
أداء ثابت عبر معايير أخرى مثل MATH-500 و MMLU.
ما هي متطلبات الأجهزة؟
حجم النموذج: 73.21 جيجابايت.
وحدات معالجة رسومية موصى بها: 1 × H100 (80 جيجابايت) أو A100 (80 جيجابايت).
2 × L40s (96 جيجابايت) أو 4 × RTX 4090 (96 جيجابايت).
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيل GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



