

关键亮点
强大且高效:性能媲美更大模型,资源需求更低。
基准测试领先:在 AIME 2024 和 SWE-bench Verified 上表现出色,超越 OpenAI-o1-mini。
多语言支持:支持 29 种以上语言,包括中文、英文、法文等。
高级特性:支持长文本(8K+ tokens)、结构化输出以及角色扮演场景。
**易于接入 **:可通过 Ollama 进行本地部署,或通过 Novita AI API 集成。
邀请好友加入 Novita AI,双方均可获得 $10 的 LLM API 积分——最高可达 $500 总奖励。
为支持开发者社区,Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B 目前在 Novita AI 上免费提供。

DeepSeek R1 Distill Qwen 32B 是一款先进的蒸馏模型,以显著更低的硬件需求提供了更大模型的强大能力。其微调架构实现了卓越的性能,在基准测试中持续超越 OpenAI-o1-mini 等模型。该模型专为高效和易用性而设计,支持本地部署和无缝 API 集成,非常适合开发者、研究人员和企业使用。
DeepSeek R1 Distill Qwen 32B 基本介绍
基本信息
模型大小
32.8B
开源
是
架构
Transformer
语言支持
支持超过 29 种语言的多语言功能,包括:
中文 英文 法文 西班牙文 葡萄牙文 德文 意大利文 俄文 日文 韩文 越南文 泰文 阿拉伯文 等等…
关键亮点
- 在指令遵循和长文本生成(超过 8K tokens)方面有显著改进。
- 增强了对结构化数据(例如表格)的理解以及结构化输出(尤其是 JSON)的生成能力。
- 对多样化的系统提示更具弹性,改进了角色扮演的实现和聊天机器人的条件设置。
多模态能力
支持文本到文本的转换。
训练
使用 DeepSeek R1 作为教师模型对 Qwen 2.5 32B 进行微调,以达到与更大模型相似的性能。
DeepSeek 确实在将大型 R1 模型蒸馏到其他开源模型方面做出了独特的贡献。特别是与 Qwen-32B 的融合,似乎在各项基准测试中都带来了巨大的收益,使其成为 VRAM 较少用户的首选模型,总体结果远优于 Llama-70B 蒸馏版。目前是本地 LLM 的 SOTA,甚至在消费级硬件上也能有不错的表现。
基准测试
| 基准测试 | DeepSeek-R1-32B | OpenAI-o1-mini | 其他模型 |
|---|---|---|---|
| AIME 2024 | 72.6% | 63.6% | Llama-70B: 70.0%, QwQ-32B: 50.0% |
| Codeforces | 71.5% | 60.0% | Llama-70B: 57.5%, QwQ-32B: 54.5% |
| GPQA Diamond | 62.1% | 60.0% | Llama-70B: 65.2%, QwQ-32B: 54.5% |
| MATH-500 | 75.7% | 90.0% | Llama-70B: 94.5%, QwQ-32B: 90.6% |
| MMLU | 90.8% | 88.5% | Llama-70B: 91.8%, QwQ-32B: 90.6% |
| SWE-bench Verified | 49.2% | 36.8% | Llama-70B: 57.5%, QwQ-32B: 41.6% |
DeepSeek R1 Distill Qwen 32B 在 AIME 2024 和 SWE-bench Verified 上表现出色,部分任务略优于 OpenAI-o1-mini,但在需要高级推理或数学能力的基准测试中,通常落后于 DeepSeek R1 Llama 70B 等更大模型。
如何在本地接入 DeepSeek R1 Distill Qwen 32B
硬件要求
模型大小: 73.21 GB
- 1 × H100 (80GB): 用于训练的高性能 GPU。
- 1 × A100 (80GB): 用于大型数据集的高内存 GPU。
- 2 × L40s (96GB): 内存增强的高级推理 GPU。
- 4 × RTX 4090 (96GB): 用于分布式任务的高功率 GPU。
分步安装指南
# Guide: Install and Use DeepSeek-R1 with Ollama
# 1. Install Ollama
# Visit the Ollama website, download and install the version for your OS:
# https://ollama.ai/
# 2. Download the DeepSeek-R1 Model
# Open your terminal and run the command below to download the model
# (using the 7B parameter version as an example):
ollama run deepseek-r1:7b
# Wait for the download to complete. The time required will depend on your network speed.
# 3. Verify Installation and Start the Model
# Verify that the model has been successfully downloaded:
ollama list
# Ensure "deepseek-r1" appears in the list.
# Start the 32B version of the model:
ollama run deepseek-r1:32b
# 4. Usage Examples
# Ask a query:
>>> "Explain quantum computing in simple terms."
# Generate code:
>>> "Write a Python function to calculate the Fibonacci sequence."
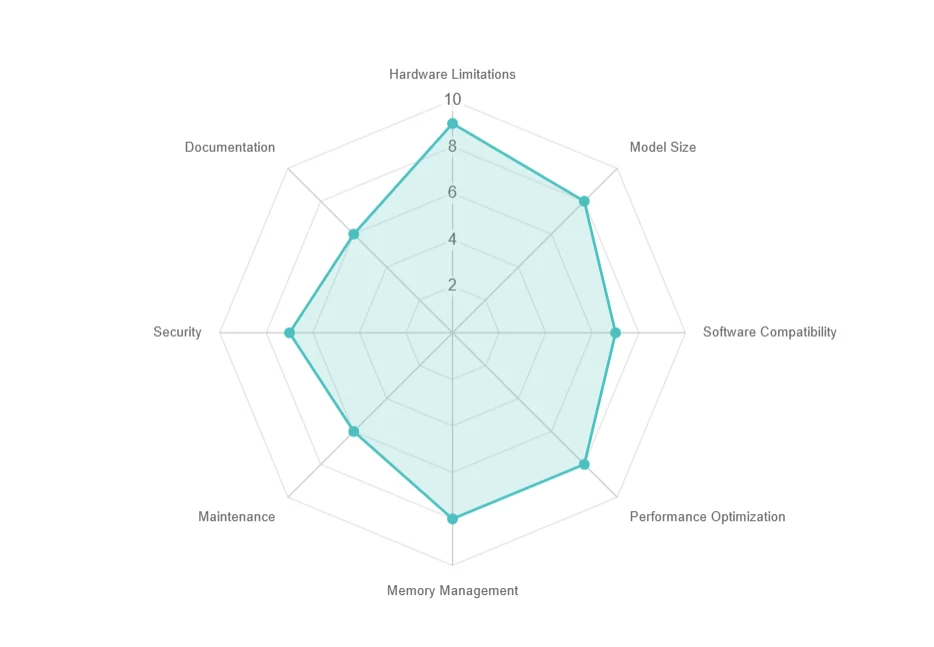
本地部署面临的挑战
- 硬件限制:资源需求高,升级成本昂贵。
- 模型大小:存储空间大(如 70+ GB),下载速度慢。
- 软件兼容性:依赖和操作系统问题。
- 性能优化:延迟、批处理和并行计算挑战。
- 内存管理:GPU 内存限制和核外执行的权衡。
- 维护:频繁更新和兼容性问题。
- 安全性:确保本地环境的数据隐私。
- 文档:支持有限,故障排查困难。
如何通过 Novita AI 接入 DeepSeek R1 Distill Qwen 32B
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
步骤 1:登录并访问模型库
登录您的账户,点击 “Model Library” 按钮。

立即试用 DeepSeek R1 Distill Qwen 32B Demo!
步骤 2:选择模型
浏览可用选项,选择符合您需求的模型。
步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤 4:获取 API 密钥
为了对 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入 “Settings” 页面,您可以按照图片所示复制 API 密钥。

步骤 5:安装 API
使用编程语言对应的包管理器安装 API。

安装后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化客户端,开始与 Novita AI LLM 交互。以下是 Python 用户使用 chat completions API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
哪种方法适合您?

DeepSeek R1 Distill Qwen 32B 模型是一款先进的本地语言模型,在指令遵循、结构化数据处理和多语言支持方面具有卓越性能。其使用 DeepSeek R1 作为教师进行微调确保了效率,适合研究人员、开发者和企业。尽管对硬件有要求,但它在性能和可访问性之间取得了平衡,在 AIME 2024 和 SWE-bench Verified 等基准测试中表现出色。
常见问题解答
DeepSeek R1 Distill Qwen 32B 的关键特性是什么?
支持 29 种以上语言的多语言功能。
处理长文本(8K+ tokens)和 JSON 等结构化数据。
支持文本到文本转换以及高级角色扮演场景。
哪些基准测试突显了它的性能?
AIME 2024:准确率 72.6%(优于 OpenAI-o1-mini)。
SWE-bench Verified:准确率 49.2%(领先于 Llama-70B)。
在 MATH-500 和 MMLU 等其他基准测试中表现持续稳定。
硬件要求是什么?
模型大小:73.21 GB。
推荐 GPU:1 × H100 (80GB) 或 A100 (80GB)。
2 × L40s (96GB) 或 4 × RTX 4090 (96GB)。
Novita AI 是一个一体化云平台,助力您的 AI 梦想。集成 API、Serverless、GPU 实例——经济高效的工具。无需管理基础设施,免费开始,让您的 AI 愿景成为现实。



