

如果你在 2026 年构建一个 AI 智能体,选择哪个推理提供商比一年前更重要——原因在于大多数对比文章不会讨论的方面。上下文窗口、价格和延迟只是基础门槛。只有当你的智能体开始每会话进行数十次工具调用、生成并行子任务、并向你的基础设施发起不可预测的流量峰值时,真正的区别才会显现。
本指南将拆解决定推理提供商能否处理智能体工作负载(不仅仅是聊天补全)的五个标准。
为什么智能体工作负载与众不同
聊天补全是一次往返:一个提示输入,一个响应输出。而 AI 智能体则完全不同。
典型的智能体工作流包含:
- 多步推理循环——模型思考、行动、观察、再思考,每次用户请求串联多次 LLM 调用
- 每一步的工具调用——搜索、代码执行、API 调用、文件读取,每个都需要模型准确返回结构化响应
- 不断增长的上下文窗口——每个工具结果都被追加到上下文中,一个从 2K token 开始的会话可能在第 15 步达到 80K token
- 突发密集的流量模式——智能体通常由事件(Webhook、用户操作、定时任务)触发,而非像聊天那样平滑分布
五个关键标准
1. 工具调用稳定性
🔧快速总结——如果你的提供商不能稳定返回格式正确的工具调用,你的智能体将在工作流中途失败。这是不可妥协的。
这是什么: 提供商在多步智能体循环的每一轮中,可靠地返回格式正确的工具调用响应的能力。
对智能体的重要性: 聊天补全可以偶尔容忍格式错误的响应,但智能体不行。如果模型在 10 步工作流的第 6 步返回了结构错误的工具调用,整个任务就会失败。
关注点:
- 兼容 OpenAI 的函数调用 API——而非需要自定义解析的专有格式
- 结构化输出支持——在模型层面强制要求有效的 JSON schema,而不仅仅通过提示词
- 模型级验证——并非所有模型都能同样处理好多次工具调用
在 Novita AI 上: Novita 原生支持函数调用和结构化输出。
2. 上下文长度
📏快速总结——上下文长度是智能体的工作记忆。不足的上下文不会导致智能体崩溃,却会引起隐形的质量下降。
这是什么: 单次请求中模型能处理的最大 token 数量——包括之前的所有对话轮次、工具结果和系统提示。
对智能体的重要性: 智能体获取的每个工具结果都被添加到上下文中。一次网络搜索可能返回 3K token,一次代码执行输出可能返回 8K。对于一个研究型智能体,在第 10 步时很容易达到 50–100K token。上下文长度不足会导致细微下降——智能体“忘记”系统提示中定义的约束,与之前的推理矛盾,或重复已完成步骤。
关注点:
- 生产环境智能体至少需要 128K token
- 研究型智能体、长周期规划任务或代码密集型工作流需要 200K+ token
- 提示缓存——每轮重新发送大量上下文会迅速增加成本;缓存稳定前缀可同时降低成本和延迟
在 Novita AI 上: 上下文长度最高达 1M token (MiniMax M1),大多数旗舰模型为 128K–204K token。GLM-4.7 和 MiniMax M2.x 系列支持 204,800 token;Llama 3.3 70B 支持 131,072 token;DeepSeek V3.2 和 V3-0324 支持 163,840 token。提示缓存 原生可用。
3. 突发流量处理
⚡快速总结——在测试中正常的速率限制,在生产环境中可能表现为 429 错误,并在执行过程中破坏智能体工作流。
这是什么: 提供商承受突发请求量峰值的能力,而不会出现显著延迟退化或硬性失败。
对智能体 ** 的重要性: 智能体流量本质上是突发性的。一个用户触发的事件可能一次扇出 10 个并行子智能体调用。一个定时任务可能在午夜同时启动 50 个智能体。
关注点:
- 高 RPM 上限——尤其是你团队当前可及的等级
- 按模型的速率限制——而非所有模型共享一个池
- 可选专用端点——当你需要保证容量时
在 Novita AI 上: 在 T3 及以上,大多数模型支持 1,000 RPM;在 T5,每个模型可扩展至 3,000–6,000 RPM。所有等级 TPM 上限为 50M token/分钟。提供专用端点用于保留容量和保证 SLA。
4. 冷启动延迟
🚀快速总结——在多步智能体循环中,延迟会累积。3 秒冷启动 × 8 次工具调用 = 每次会话不必要的 24 秒开销。
这是什么: 当模型实例尚未“热起来”,需要初始化后才能处理请求时产生的延迟。
对智能体的重要性: 冷启动往往会聚集发生——如果智能体几分钟没有收到流量,下一批请求会同时撞上冷实例。对于无服务器推理提供商,冷启动通常是基准测试未捕获的隐藏性能变量。
关注点:
- 流行模型持续保活实例
- 各请求模式下可预测的 TTFT(首 token 时间)
- 智能体沙箱基础设施 启动时间低于 200ms(针对代码执行型智能体)
在 Novita AI 上: 作为一个运行 200+ 模型的高容量平台,Novita 保持流行模型实例温热。端到端延迟和 TTFT 指标(包括 P95 和 P99 百分位)通过可观测性仪表板暴露。智能体沙箱启动时间低于 200ms。
5. 并发
🔀快速总结——并发不仅关乎规模,更关乎架构。并行执行子任务的智能体比顺序执行快得多。
这是什么: 提供商能同时处理多少请求——既包括 API 层面 (RPM/TPM),也包括基础设施层面(并行智能体执行)。
对智能体的重要性: 多智能体系统需要在多个层面具备并发能力:并行 LLM 调用、并行工具执行和并行沙箱实例。
关注点:
- 每个模型的高 RPM 以支持并行智能体调用
- 沙箱并发——能否同时启动 50 个隔离的执行环境?
- 沙箱按秒计费,而非按分钟
在 Novita AI 上: 智能体沙箱支持大规模并发创建,CPU 和 RAM 按秒计费。T3+ 账户每个模型可达 1,000 RPM,可观测性层实时追踪 RPM。
决策框架
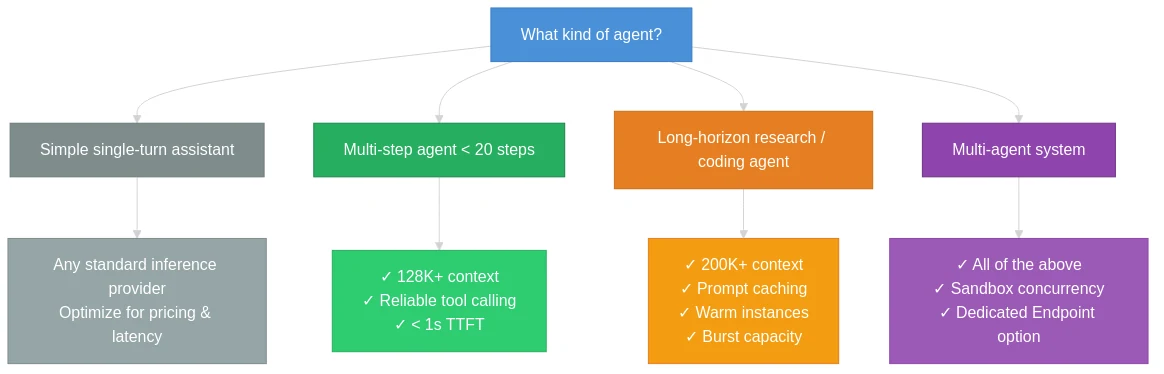
| 标准 | 最低要求 | 生产就绪 |
|---|---|---|
| 工具调用 | 兼容 OpenAI 的函数调用 | 结构化输出 + 已验证的多轮支持 |
| 上下文长度 | 32K | 128K+(研究型智能体 200K+) |
| 突发容量 | 100 RPM | 每个模型 1,000+ RPM |
| 冷启动 | 平均 TTFT < 3s | P95 TTFT < 1s,温实例保证 |
| 并发 | 顺序 | 并行 LLM 调用 + 沙箱执行 |
结论
为 AI 智能体选择推理提供商与选择聊天机器人提供商不同。五个标准——工具调用稳定性、上下文长度、突发流量、冷启动和并发——将专为聊天设计的提供商与为运行生产级智能体而构建的提供商区分开来。
Novita AI 定位为 AI 与智能体云平台:通过一个兼容 OpenAI 的 API 提供 200+ 种模型,智能体沙箱启动时间 <200ms 且按秒计费,提示缓存用于长上下文成本效率,以及可扩展的速率限制结构,从原型(30 RPM)到生产(每个模型 6,000 RPM)。
Novita AI 是一个 AI 与智能体云平台,帮助开发者和初创公司以高性能、高可靠性和成本效益构建、部署和扩展模型及智能体应用。
常见问题
智能体中用于工具调用的模型选择重要吗?
是的——非常重要。并非所有模型都能以相同可靠性处理多轮函数调用。请测试你的具体智能体工作流,并寻找那些明确按工具调用能力对模型进行分类的提供商。
如何估算我实际需要的上下文长度?
首先记录代表性会话中每一步的实际 token 数。一个合理的经验法则:每会话超过 5 次工具调用 → 64K+ token;超过 10 次工具调用 → 128K+。
专用端点是否值得成本?
对于大多数早期团队,共享无服务器端点已经足够。专用端点在以下情况下有意义:(a) 流量可预测,足以证明保留容量合理;(b) 你已在共享层触及速率限制;或 © 你的 SLA 要求无请求排队。
推荐文章



