

주요 하이라이트
강력하면서도 효율적: 더 큰 모델의 성능을 더 적은 리소스로 구현합니다.
벤치마크 선두: AIME 2024 및 SWE-bench Verified에서 OpenAI-o1-mini를 능가합니다.
다국어 지원: 중국어, 영어, 프랑스어 등 29개 이상의 언어를 지원합니다.
고급 기능: 긴 텍스트(8K+ 토큰), 구조화된 출력, 롤플레이 시나리오를 지원합니다.
**쉬운 접근 **: 로컬 배포를 위한 Ollama 또는 Novita AI API 를 통해 통합할 수 있습니다.
친구를 Novita AI에 추천하면 두 분 모두 LLM API 크레딧 $10를 받을 수 있습니다. 총 최대 $500까지 적립 가능합니다.
개발자 커뮤니티를 지원하기 위해 Novita AI에서 Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B를 현재 무료로 제공하고 있습니다.

DeepSeek R1 Distill Qwen 32B 는 대형 모델의 성능을 훨씬 낮은 하드웨어 요구 사항으로 제공하는 최첨단 증류 모델입니다. 미세 조정된 아키텍처는 뛰어난 성능을 제공하며, 벤치마크에서 OpenAI-o1-mini와 같은 모델을 지속적으로 능가합니다. 효율성과 접근성을 위해 설계되어 로컬 배포와 원활한 API 통합을 지원하므로 개발자, 연구자, 비즈니스 모두에게 이상적입니다.
Deepseek R1 Distill Qwen 32B 기본 소개
기본 정보
모델 크기
32.8B
오픈소스
예
아키텍처
Transformer
언어 지원
29개 이상의 언어에 대한 다국어 지원:
중국어, 영어, 프랑스어, 스페인어, 포르투갈어, 독일어, 이탈리아어, 러시아어, 일본어, 한국어, 베트남어, 태국어, 아랍어 등…
주요 하이라이트
- 명령어 수행 및 긴 텍스트(8K 토큰 이상) 생성에서 상당한 개선.
- 구조화된 데이터(예: 표) 이해 및 구조화된 출력(특히 JSON) 생성 능력 향상.
- 다양한 시스템 프롬프트에 대한 내성이 강화되어 챗봇의 롤플레이 구현 및 조건 설정이 개선됨.
멀티모달 기능
텍스트-텍스트 변환을 지원합니다.
학습
Qwen 2.5 32B를 DeepSeek R1을 교사 모델로 사용하여 미세 조정하여 대형 모델과 유사한 성능을 달성했습니다.
DeepSeek는 큰 R1 모델을 다른 오픈소스 모델에 증류하는 데 정말 특별한 일을 해냈습니다. 특히 Qwen-32B와의 융합은 벤치마크 전반에서 엄청난 성능 향상을 가져오며 VRAM이 적은 사람들에게 최적의 모델이 되었고, LLama-70B 증류 모델과 비교해 전반적으로 가장 좋은 결과를 제공합니다. 현재 로컬 LLM의 SOTA이며, 소비자 하드웨어에서도 상당히 준수한 성능을 보여줍니다.
벤치마크
| 벤치마크 | DeepSeek-R1-32B | OpenAI-o1-mini | 기타 모델 |
|---|---|---|---|
| AIME 2024 | 72.6% | 63.6% | Llama-70B: 70.0%, QwQ-32B: 50.0% |
| Codeforces | 71.5% | 60.0% | Llama-70B: 57.5%, QwQ-32B: 54.5% |
| GPQA Diamond | 62.1% | 60.0% | Llama-70B: 65.2%, QwQ-32B: 54.5% |
| MATH-500 | 75.7% | 90.0% | Llama-70B: 94.5%, QwQ-32B: 90.6% |
| MMLU | 90.8% | 88.5% | Llama-70B: 91.8%, QwQ-32B: 90.6% |
| SWE-bench Verified | 49.2% | 36.8% | Llama-70B: 57.5%, QwQ-32B: 41.6% |
Deepseek R1 Distill Qwen 32B는 AIME 2024 및 SWE-bench Verified 에서 뛰어난 성능을 보여주며, 일부 작업에서 OpenAI-o1-mini보다 약간 우수하지만 고급 추론이나 수학적 능력이 필요한 벤치마크에서는 일반적으로 Deepseek R1 Llama 70B와 같은 대형 모델에 뒤쳐집니다.
Deepseek R1 Distill Qwen 32B 로컬에서 접근하는 방법
하드웨어 요구 사항
모델 크기: 73.21 GB
- 1 × H100 (80GB): 고성능 GPU (학습용).
- 1 × A100 (80GB): 대용량 데이터셋용 고메모리 GPU.
- 2 × L40s (96GB): 향상된 메모리를 갖춘 고급 추론 GPU.
- 4 × RTX 4090 (96GB): 분산 작업용 고성능 GPU.
단계별 설치 가이드
# 가이드: Ollama로 DeepSeek-R1 설치 및 사용하기
# 1. Ollama 설치
# Ollama 웹사이트를 방문하여 OS에 맞는 버전을 다운로드하고 설치합니다:
# https://ollama.ai/
# 2. DeepSeek-R1 모델 다운로드
# 터미널을 열고 아래 명령어를 실행하여 모델을 다운로드합니다
# (예시로 7B 파라미터 버전 사용):
ollama run deepseek-r1:7b
# 다운로드가 완료될 때까지 기다립니다. 소요 시간은 네트워크 속도에 따라 다릅니다.
# 3. 설치 확인 및 모델 시작
# 모델이 성공적으로 다운로드되었는지 확인합니다:
ollama list
# 목록에 "deepseek-r1"이 표시되는지 확인합니다.
# 32B 버전의 모델을 시작합니다:
ollama run deepseek-r1:32b
# 4. 사용 예제
# 질문하기:
>>> "양자 컴퓨팅을 간단한 용어로 설명해 주세요."
# 코드 생성:
>>> "피보나치 수열을 계산하는 Python 함수를 작성해 주세요."
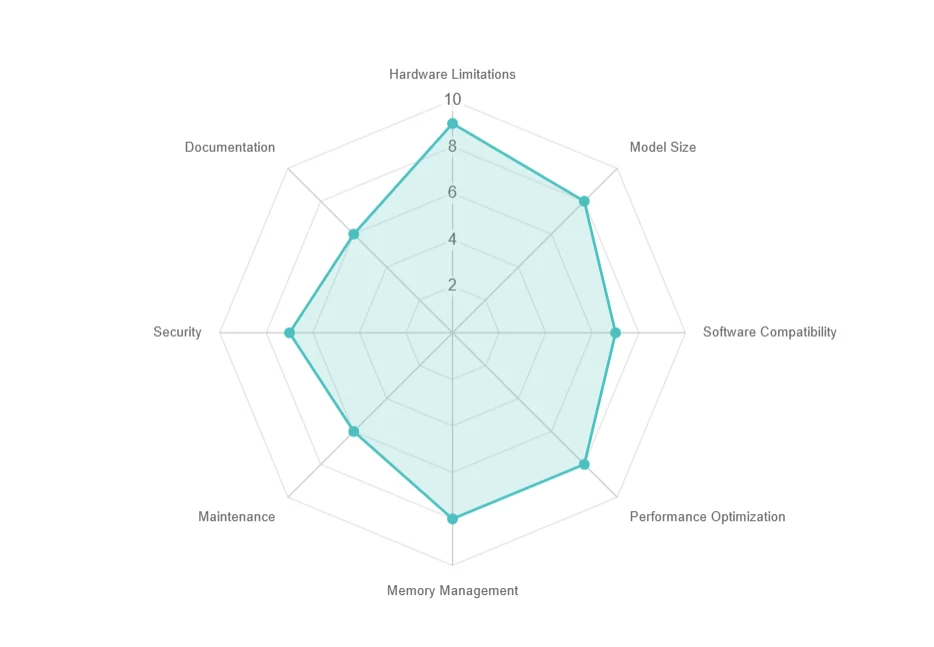
로컬 배포의 과제
- 하드웨어 제약: 높은 리소스 요구, 비싼 업그레이드 비용.
- 모델 크기: 대용량 저장 공간(예: 70GB 이상), 느린 다운로드.
- 소프트웨어 호환성: 의존성 및 OS 문제.
- 성능 최적화: 지연 시간, 배치 처리, 병렬 처리 문제.
- 메모리 관리: GPU 메모리 한계 및 아웃오브코어 실행 절충.
- 유지보수: 빈번한 업데이트 및 호환성 문제.
- 보안: 로컬 환경에서 데이터 프라이버시 보장.
- 문서화: 제한된 지원 및 문제 해결 어려움.
Novita AI를 통해 Deepseek R1 Distill Qwen 32B에 접근하는 방법
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 빌드 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공합니다.
1단계: 로그인 및 모델 라이브러리 접근
계정에 로그인하고 Model Library 버튼을 클릭하세요.

Deepseek R1 Distill Qwen 32B 데모 지금 사용해보기!
2단계: 모델 선택
사용 가능한 옵션을 둘러보고 필요에 맞는 모델을 선택하세요.
3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하려면 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공해 드립니다. Settings 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.

설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-distill-qwen-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
어떤 방법이 적합할까요?

DeepSeek R1 Distill Qwen 32B 모델은 명령어 수행, 구조화된 데이터 처리, 다국어 지원에서 뛰어난 성능을 제공하는 최첨단 로컬 언어 모델입니다. DeepSeek R1을 교사로 사용한 미세 조정은 효율성을 보장하여 연구자, 개발자, 비즈니스에 적합합니다. 하드웨어 요구 사항에도 불구하고 성능과 접근성 사이의 균형을 제공하며 AIME 2024 및 SWE-bench Verified 와 같은 벤치마크에서 탁월한 성능을 보여줍니다.
자주 묻는 질문
DeepSeek R1 Distill Qwen 32B의 주요 기능은 무엇인가요?
29개 이상의 언어를 지원하는 다국어 지원.
긴 텍스트(8K+ 토큰) 및 JSON과 같은 구조화된 데이터 처리.
텍스트-텍스트 변환 및 고급 롤플레이 시나리오 지원.
어떤 벤치마크에서 성능이 두드러지나요?
AIME 2024: 72.6% 정확도(OpenAI-o1-mini 능가).
SWE-bench Verified: 49.2% 정확도(Llama-70B보다 앞섬).
MATH-500 및 MMLU 등 다른 벤치마크에서 일관된 성능.
하드웨어 요구 사항은 무엇인가요?
모델 크기: 73.21 GB.
권장 GPU: 1 × H100 (80GB) 또는 A100 (80GB).
2 × L40s (96GB) 또는 4 × RTX 4090 (96GB).
Novita AI는 AI 비전을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 비용 효율적인 도구를 제공합니다. 인프라 걱정 없이 무료로 시작하고 AI 비전을 현실로 만드세요.



