

MiniMax M2.5 est l’un des agents de codage IA les plus rapides et les plus économiques disponibles — et avec Novita AI, vous y accédez pour seulement 0,30 $/1,20 $ par million de tokens. Avec 80,2 % sur SWE-Bench Verified et 51,3 % sur Multi-SWE-Bench, M2.5 offre des performances de codage de pointe tout en accomplissant les tâches 37 % plus rapidement que M2.1 — égalant la vitesse de Claude Opus 4.6 pour une fraction du coût.
Ce guide vous montre exactement comment accéder à MiniMax M2.5 via l’API compatible OpenAI de Novita AI, le déployer pour des charges de production et maximiser ses atouts uniques dans le codage agentique, l’utilisation d’outils et l’automatisation bureautique.
Essayez dès maintenant MiniMax M2.5 puissant et abordable !
Qu’est-ce que MiniMax M2.5 ?
MiniMax M2.5 est un modèle mixture-of-experts (MoE) de 228,7 milliards de paramètres, spécialement entraîné pour les tâches de productivité réelles. Construit avec 256 experts et 8 experts activés par token, il offre des performances de pointe en codage, utilisation agentique d’outils, recherche web et automatisation bureautique, tout en maintenant une efficacité d’inférence extrême.
Architecture de MiniMax M2.5
| Spécification | MiniMax M2.5 |
|---|---|
| Paramètres totaux | 229B |
| Architecture | Mixture-of-Experts (MoE) |
| Nombre d’experts | 256 au total, 8 actifs par token |
| Longueur de contexte | 196 608 tokens (~196K) |
| Taille cachée | 3072 |
| Couches | 62 |
| Taille du vocabulaire | 200 064 |
Benchmarks de MiniMax M2.5
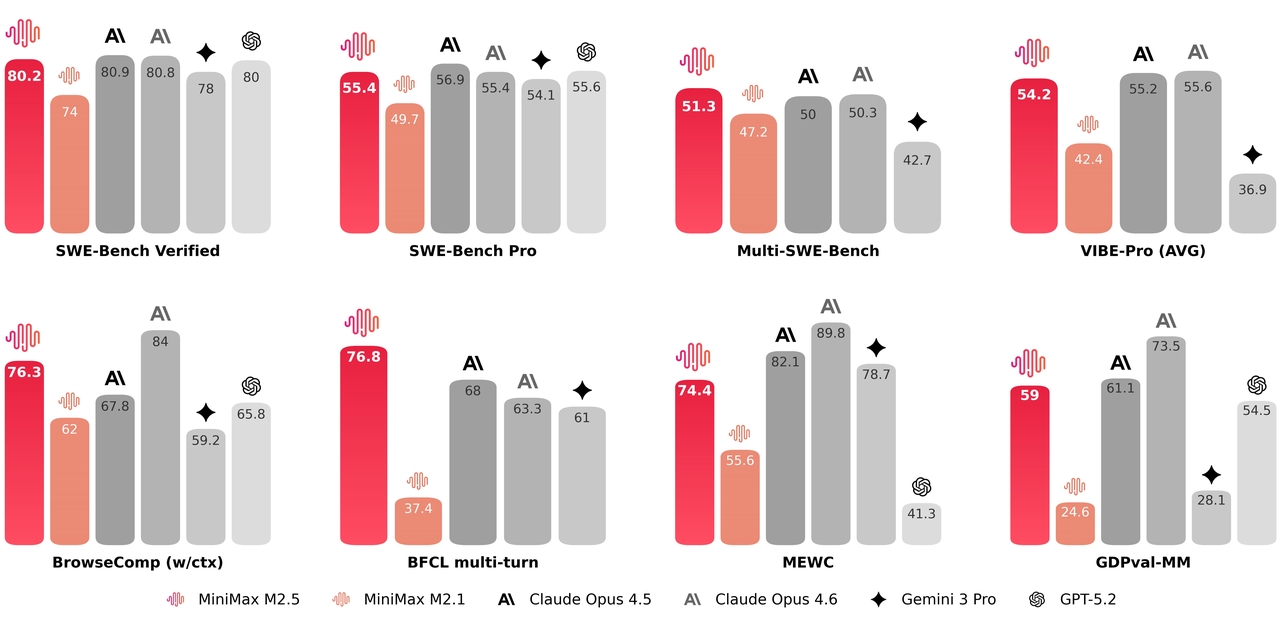
MiniMax M2.5 obtient des résultats de pointe dans les benchmarks de codage, de tâches agentiques et d’automatisation bureautique — égalant ou dépassant des modèles 3 à 5 fois plus chers. Le modèle a été entraîné par apprentissage par renforcement dans plus de 200 000 environnements réels, ce qui lui confère une généralisation inégalée pour les tâches pratiques.
Codage, tâches agentiques et utilisation d’outils
Source : HuggingFace
Source : HuggingFace
MiniMax M2.5 ne domine pas tous les benchmarks, mais il maintient des résultats constamment solides dans les tâches de simulation, de recherche et de raisonnement multitour. Son profil suggère :
- Une forte coordination de tâches de type agent
- Une intégration robuste de recherche et de récupération
- Un raisonnement multitour stable
- Une simulation compétitive d’environnements structurés
Dans l’ensemble, MiniMax M2.5 semble optimisé pour les flux de travail agentiques appliqués et l’exécution multi-étapes complexes, plutôt que pour les benchmarks de raisonnement purement académiques.
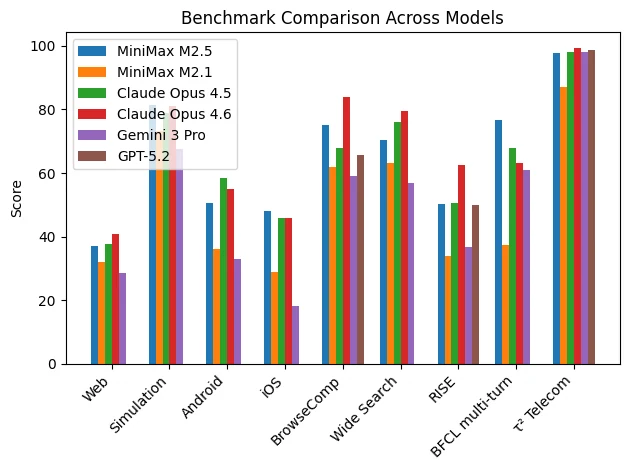
Automatisation bureautique
MiniMax M2.5 n’est pas conçu pour dominer les benchmarks de raisonnement académique abstrait ou les compétitions mathématiques pures. Sa force réside dans les tâches d’exécution professionnelles de bureau, en particulier celles nécessitant des livrables structurés.
| Benchmark | MiniMax M2.5 | MiniMax M2.1 | Claude Opus 4.5 | Claude Opus 4.6 | Gemini 3 Pro | GPT-5.2 |
|---|---|---|---|---|---|---|
| GDPval-MM | 59,0 | 24,6 | 61,1 | 73,5 | 28,1 | 54,5 |
| MEWC | 74,4 | 55,6 | 82,1 | 89,8 | 78,7 | 41,3 |
| Finance Modeling | 21,6 | 17,3 | 30,1 | 33,2 | 15,0 | 20,0 |
Essayez dès maintenant MiniMax M2.5 puissant et abordable !
Vitesse de MiniMax M2.5
Pourquoi la vitesse de M2.5 est importante : terminer SWE-Bench 37 % plus rapidement que M2.1 signifie des coûts API plus bas ET des cycles d’itération plus rapides. Pour une tâche typique de refactorisation multi-fichiers, M2.5 termine en 45 secondes contre 70 secondes pour M2.1 — économisant à la fois du temps et de l’argent à grande échelle.
Pourquoi MiniMax M2.5 sur Novita AI ?
Novita AI offre le meilleur rapport coût-performance pour exécuter MiniMax M2.5 en production. Alors que l’auto-hébergement nécessite 4 à 8 GPU H100 (au minimum 5,80 $/h), l’API serverless de Novita coûte seulement 0,30 $ d’entrée / 1,20 $ de sortie par million de tokens — sans frais d’infrastructure, avec mise à l’échelle instantanée et un SLA de disponibilité de 99,5 %.
Avantages clés de Novita AI pour MiniMax M2.5 :
| Fonctionnalité | Novita AI | Auto-hébergé |
|---|---|---|
| Temps de config. | 2 minutes (clé API) | 2 à 5 jours (provisionnement GPU + config.) |
| Modèle de coût | Paiement par token (0,30 $/1,20 $ par million) | Location fixe GPU (5,80 $/h+ pour 4×H100) |
| Mise à l’échelle | Mise à l’échelle automatique instantanée | Provisionnement manuel des GPU |
| Maintenance | Zéro (service géré) | Élevée (vLLM, drivers, mises à jour) |
| Disponibilité | SLA 99,5 % | Dépend de votre infrastructure |
| Idéal pour | Charges variables, prototypage rapide, API de production | Inférence 24/7 à volume élevé avec charge prévisible |
Comment accéder à MiniMax M2.5 sur Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez dès maintenant MiniMax M2.5 puissant et abordable !
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Settings » et copiez la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets propre à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Intégrer MiniMax M2.5 avec des outils populaires
Connectez facilement Novita AI à des plateformes partenaires comme Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow et Openclaw grâce à des intégrations officielles et des guides pas à pas.
Cas d’usage : où MiniMax M2.5 excelle
Vous pouvez également tester M2.5 de près sur des tâches de génie logiciel et observer comment il planifie et exécute dans un périmètre fermé. M2.5 produit un plan complet d’abord par spécifications, avec des maquettes d’interface utilisateur et des points d’accès API. Ensuite, il ajoute plus de 1 200 lignes de code TypeScript/JavaScript. Les tests passent du premier coup en 22 minutes, ce qui est plus rapide que la moyenne de Claude Opus 4.6. Le résultat est une application fonctionnelle avec authentification JWT et intégration MongoDB.
Build a React app with Node.js backend for user authentication, including database schema.
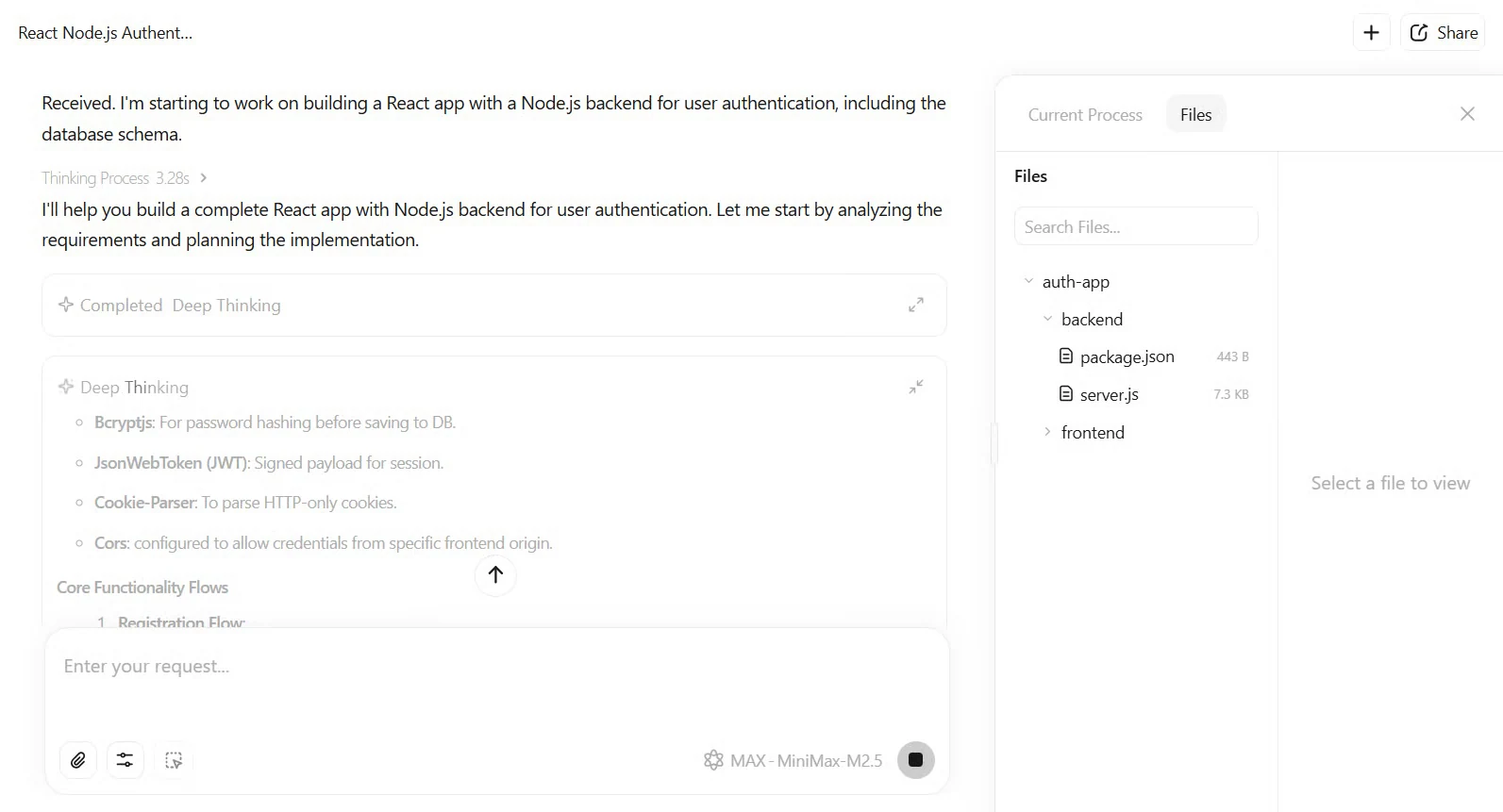
Source : site web
Essayez dès maintenant MiniMax M2.5 puissant et abordable !
MiniMax M2.5 sur Novita AI offre des performances de codage agentique de pointe pour 1/10e du coût des alternatives premium. Avec 80,2 % sur SWE-Bench Verified, une exécution 37 % plus rapide que M2.1 et un coût de 0,30 $/1,20 $ par million de tokens, c’est le choix optimal pour les agents de codage IA en production, l’automatisation bureautique et les flux d’orchestration d’outils.
Questions fréquentes
Comment MiniMax M2.5 se compare-t-il à M2.1 ?
M2.5 est 37 % plus rapide sur les tâches SWE-Bench et atteint 80,2 % contre ~70 % sur SWE-Bench Verified. Les deux coûtent le même prix (0,30 $/1,20 $ par million de tokens sur Novita), faisant de M2.5 la mise à niveau évidente.
Puis-je auto-héberger MiniMax M2.5 au lieu d’utiliser l’API Novita ?
Oui, mais cela nécessite 4 à 8 GPU H100 (au minimum 5,80 $/h sur les instances GPU Novita). L’auto-hébergement n’a de sens économique qu’au-delà de 500 millions de tokens par mois — pour la plupart des développeurs, l’API est bien plus rentable.
MiniMax M2.5 prend-il en charge l’appel de fonctions ?
Oui. M2.5 a été largement entraîné à l’utilisation d’outils et à l’appel de fonctions dans plus de 200 000 environnements réels, obtenant des performances de pointe sur BrowseComp (76,3 %) et les benchmarks de recherche étendue.
Novita AI est une plateforme cloud d’IA et d’agents qui aide les développeurs et les startups à créer, déployer et faire évoluer des modèles et des applications agentiques avec des performances, une fiabilité et une rentabilité élevées.
Lectures recommandées



