

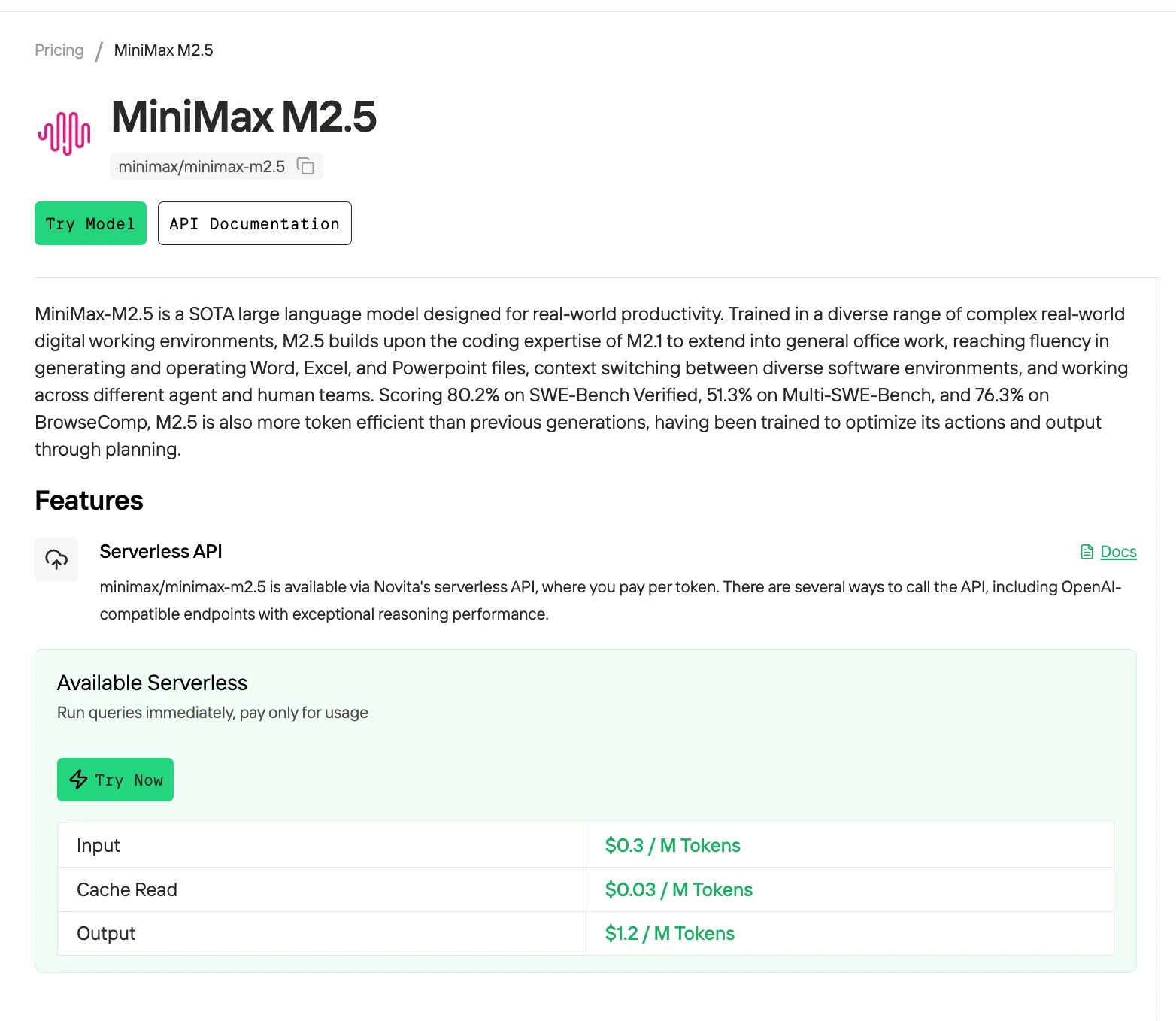
MiniMax M2.5 は、現在利用可能な最速かつ最もコスト効率の高い AI コーディングエージェントの 1 つです。Novita AI を利用すれば、100 万トークンあたりわずか $0.30/$1.20 でアクセスできます。SWE-Bench Verified で 80.2%、Multi-SWE-Bench で 51.3% を達成し、M2.1 より 37% 高速にタスクを完了しながら、最先端のコーディングパフォーマンスを提供します。これは Claude Opus 4.6 の速度に匹敵し、コストはわずかです。
このガイドでは、Novita AI の OpenAI 互換 API を通じて MiniMax M2.5 にアクセスし、本番環境のワークロードにデプロイし、エージェント型コーディング、ツール使用、オフィス自動化における独自の強みを最大限に活用する方法を正確に説明します。
MiniMax M2.5 とは?
MiniMax M2.5 は、228.7B パラメータの mixture-of-experts (MoE) モデルであり、実際の生産性タスク向けに特別にトレーニングされています。256 のエキスパートとトークンあたり 8 つのアクティブなエキスパートで構築されており、コーディング、エージェント型ツール使用、Web 検索、オフィス自動化において最先端のパフォーマンスを提供しながら、極めて高い推論効率を維持します。
Minimax M2.5 のアーキテクチャ
| 仕様 | MiniMax M2.5 |
|---|---|
| 総パラメータ数 | 229B |
| アーキテクチャ | Mixture-of-Experts (MoE) |
| エキスパート数 | 合計 256、トークンあたり 8 アクティブ |
| コンテキスト長 | 196,608 トークン (~196K) |
| 隠れ層サイズ | 3072 |
| レイヤー数 | 62 |
| 語彙サイズ | 200,064 |
Minimax M2.5 のベンチマーク
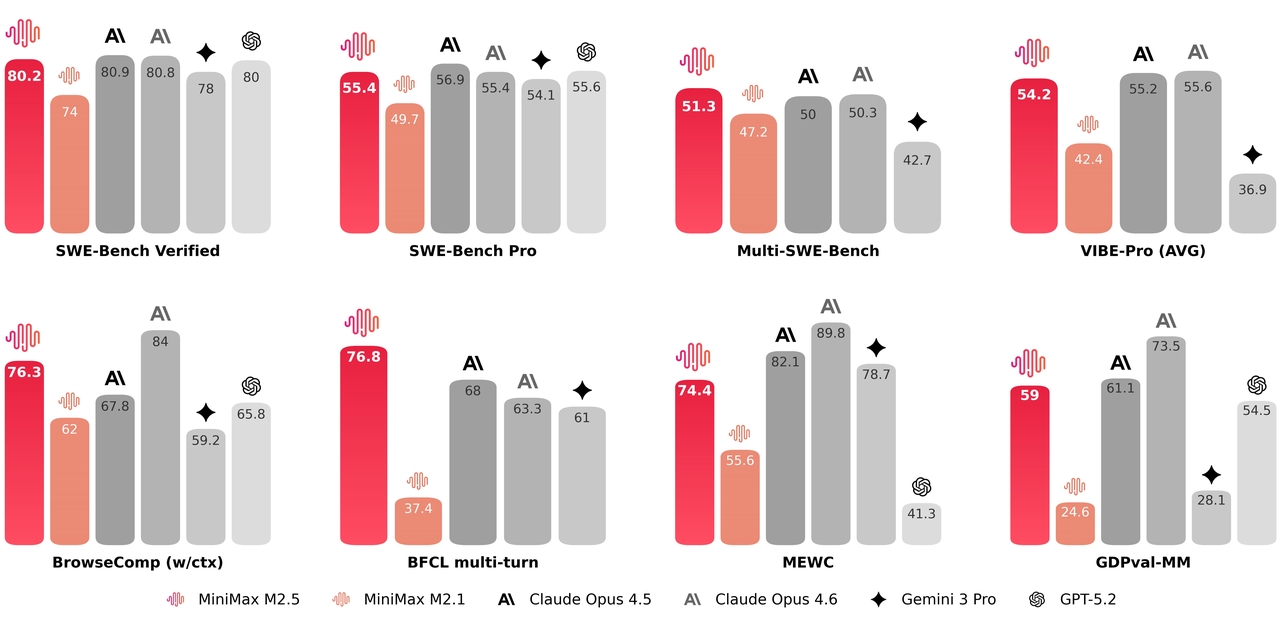
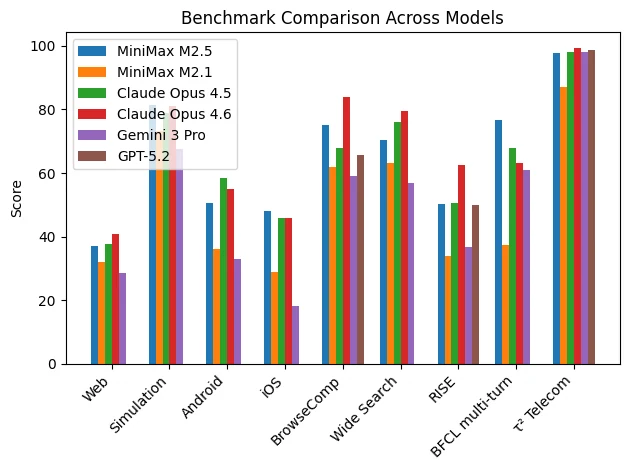
MiniMax M2.5 は、コーディング、エージェント型タスク、オフィス自動化のベンチマークで最先端の結果を達成し、3~5 倍高価なモデルに匹敵またはそれを上回ります。このモデルは、200,000 以上の実世界環境での強化学習によってトレーニングされており、実用的なタスクにおいて比類のない汎化能力を発揮します。
コーディング、エージェント型 & ツール使用
HuggingFace より
HuggingFace より
MiniMax M2.5 はすべてのベンチマークで支配的というわけではありませんが、シミュレーション、検索、マルチターン推論タスクで一貫して強力な結果を維持しています。そのプロファイルは以下を示唆しています:
- 強力なエージェント型タスク調整
- 堅牢な検索と検索統合
- 安定したマルチターン推論
- 競争力のある構造化環境シミュレーション
全体として、MiniMax M2.5 は純粋な学術的推論ベンチマークではなく、応用エージェント型ワークフローと複雑なマルチステップ実行に最適化されているように見えます。
オフィス自動化
MiniMax M2.5 は、抽象的な学術的推論ベンチマークや純粋な数学コンテストで支配的になるように設計されていません。その強みは、特に構造化された成果物を必要とするプロフェッショナルなオフィス実行タスクにあります。
| ベンチマーク | MiniMax M2.5 | MiniMax M2.1 | Claude Opus 4.5 | Claude Opus 4.6 | Gemini 3 Pro | GPT-5.2 |
|---|---|---|---|---|---|---|
| GDPval-MM | 59.0 | 24.6 | 61.1 | 73.5 | 28.1 | 54.5 |
| MEWC | 74.4 | 55.6 | 82.1 | 89.8 | 78.7 | 41.3 |
| Finance Modeling | 21.6 | 17.3 | 30.1 | 33.2 | 15.0 | 20.0 |
Minimax M2.5 の速度
M2.5 の速度が重要な理由: SWE-Bench を M2.1 より 37% 高速に完了するということは、API コストの削減と反復サイクルの高速化を意味します。典型的なマルチファイルリファクタリングタスクでは、M2.5 は 45 秒で完了するのに対し、M2.1 は 70 秒かかります。スケールが大きくなると、時間とコストの両方を節約できます。
Novita AI で MiniMax M2.5 を選ぶ理由
Novita AI は、MiniMax M2.5 を本番環境で実行するための最良のコストパフォーマンスを提供します。セルフホスティングには 4~8 台の H100 GPU(最低 $5.80/時間)が必要ですが、Novita のサーバーレス API は 100 万トークンあたり入力 $0.30 / 出力 $1.20 で、インフラストラクチャのオーバーヘッドゼロ、即時スケーリング、99.5% のアップタイム SLA を実現します。
Novita AI で MiniMax M2.5 を利用する主な利点:
| 機能 | Novita AI | セルフホスティング |
|---|---|---|
| セットアップ時間 | 2 分(API キー) | 2~5 日(GPU プロビジョニング + セットアップ) |
| コストモデル | トークン単位の従量課金(100 万トークンあたり $0.30/$1.20) | 固定 GPU レンタル(4×H100 で $5.80/時間以上) |
| スケーリング | 即時自動スケーリング | 手動 GPU プロビジョニング |
| メンテナンス | ゼロ(マネージドサービス) | 高(vLLM、ドライバー、アップデート) |
| 可用性 | 99.5% SLA | インフラストラクチャに依存 |
| 最適な用途 | 変動するワークロード、迅速なプロトタイピング、本番 API | 24 時間 365 日の高ボリューム推論、予測可能な負荷 |
Novita AI で MiniMax M2.5 にアクセスする方法
ステップ 1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。

ステップ 3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試します。
ステップ 4:API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像に示されているように API キーをコピーします。

ステップ 5:API をインストール
プログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。
インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "あなたは役立つアシスタントです。"},
{"role": "user", "content": "こんにちは、お元気ですか?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
MiniMax M2.5 を人気ツールと統合する
公式の統合とステップバイステップガイドを通じて、Novita AI を Trae、Continue、Codex、OpenCode、AnythingLLM、LangChain、Dify、Langflow、Openclaw などのパートナープラットフォームと簡単に接続できます。
ユースケース:MiniMax M2.5 が輝く場面
ソフトウェアエンジニアリングタスクで M2.5 を詳細にテストし、クローズドスコープでどのように計画し実行するかを確認することもできます。M2.5 は、UI ワイヤーフレームと API エンドポイントを含む完全な仕様ファーストの計画を出力します。その後、1200 行以上の TypeScript/JavaScript コードを追加します。テストは 22 分で初回実行に合格し、Claude Opus 4.6 の平均よりも高速です。結果は、JWT 認証と MongoDB 統合を備えた機能的なアプリケーションです。
ユーザー認証のための React アプリと Node.js バックエンドを構築し、データベーススキーマを含めてください。
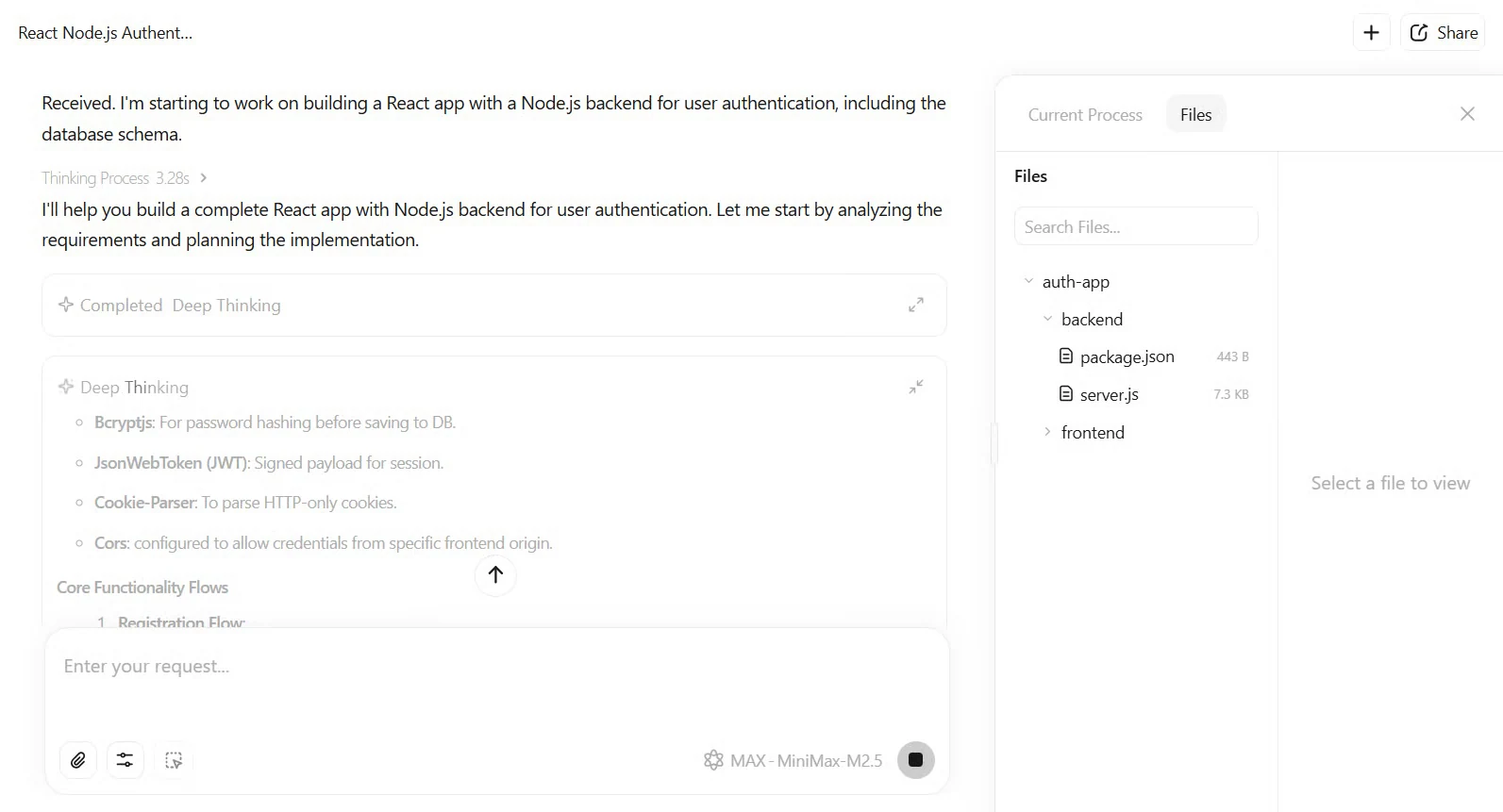
ウェブサイト より
Novita AI 上の MiniMax M2.5 は、プレミアム代替品の 1/10 のコストで最先端のエージェント型コーディングパフォーマンスを提供します。SWE-Bench Verified で 80.2%、M2.1 より 37% 高速なタスク完了、100 万トークンあたり $0.30/$1.20 で、本番 AI コーディングエージェント、オフィス自動化、ツールオーケストレーションワークフローに最適な選択肢です。
よくある質問
MiniMax M2.5 は M2.1 と比較してどうですか?
M2.5 は SWE-Bench タスクで 37% 高速で、SWE-Bench Verified で約 70% に対して 80.2% を達成しています。両方とも同じコスト(Novita では 100 万トークンあたり $0.30/$1.20)であるため、M2.5 が明確なアップグレードです。
Novita API の代わりに MiniMax M2.5 をセルフホストできますか?
はい、ただし 4~8 台の H100 GPU(Novita GPU インスタンスで最低 $5.80/時間)が必要です。セルフホスティングが経済的に意味を持つのは、月間 5 億トークン以上の場合のみです。ほとんどの開発者にとって、API の方がはるかにコスト効率が高いです。
MiniMax M2.5 は関数呼び出しをサポートしていますか?
はい。M2.5 は 200,000 以上の実世界環境でツール使用と関数呼び出しについて広範にトレーニングされており、BrowseComp (76.3%) および Wide Search ベンチマークで業界をリードするパフォーマンスを達成しています。
Novita AI は、開発者やスタートアップが高性能、信頼性、コスト効率に優れたモデルとエージェント型アプリケーションを構築、デプロイ、スケーリングできる AI & エージェントクラウドプラットフォームです。
おすすめの記事



