

MiniMax M2.5 ist einer der schnellsten und kosteneffizientesten KI-Coding-Agenten auf dem Markt – und mit Novita AI kannst du ihn für nur 0,30 $/1,20 $ pro 1M Tokens nutzen. Mit 80,2 % auf SWE-Bench Verified und 51,3 % auf Multi-SWE-Bench liefert M2.5 Spitzenleistungen beim Coding und erledigt Aufgaben 37 % schneller als M2.1 – bei gleicher Geschwindigkeit wie Claude Opus 4.6, aber zu einem Bruchteil der Kosten.
Diese Anleitung zeigt dir genau, wie du MiniMax M2.5 über die OpenAI-kompatible API von Novita AI nutzt, für Produktions-Workloads einsetzt und seine einzigartigen Stärken im agentischen Coding, Tool-Einsatz und der Büroautomatisierung maximierst.
Jetzt leistungsstarken und erschwinglichen Minimax M2.5 ausprobieren!
Was ist MiniMax M2.5?
MiniMax M2.5 ist ein Mixture-of-Experts (MoE)-Modell mit 228,7 Milliarden Parametern, das speziell für Produktivitätsaufgaben in der realen Welt trainiert wurde. Mit 256 Experten, von denen pro Token 8 aktiviert werden, liefert es Spitzenleistungen beim Programmieren, beim agentischen Tool-Einsatz, bei der Websuche und Büroautomatisierung – bei extrem hoher Inferenzeffizienz.
Architektur von Minimax M2.5
| Spezifikation | MiniMax M2.5 |
|---|---|
| Gesamtparameter | 229B |
| Architektur | Mixture-of-Experts (MoE) |
| Anzahl Experten | 256 gesamt, 8 aktiv pro Token |
| Kontextlänge | 196.608 Tokens (~196K) |
| Hidden Size | 3072 |
| Layer | 62 |
| Vokabulargröße | 200.064 |
Benchmark-Ergebnisse von Minimax M2.5
MiniMax M2.5 erzielt in Coding-, agentischen und Büroautomatisierungs-Benchmarks Spitzenresultate – auf dem Niveau oder besser als Modelle, die 3-5x teurer sind. Das Modell wurde mit Reinforcement Learning in über 200.000 realen Umgebungen trainiert, was ihm eine unübertroffene Generalisierungsfähigkeit bei praktischen Aufgaben verleiht.
Coding, Agentik und Tool-Nutzung
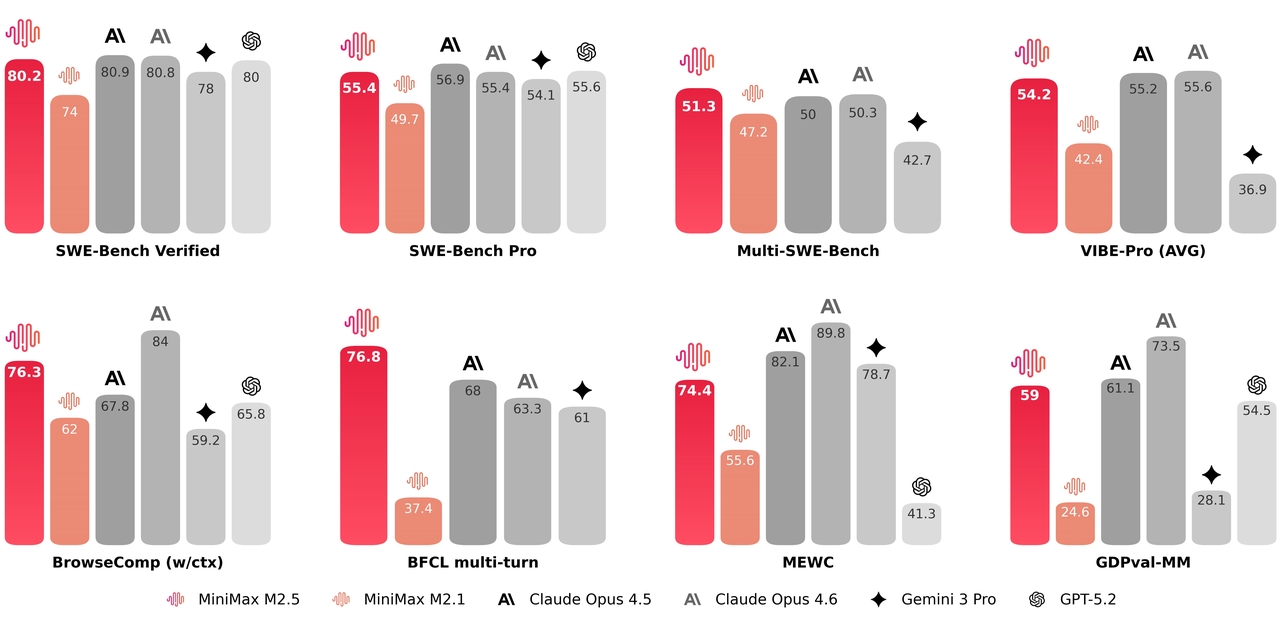
Von HuggingFace
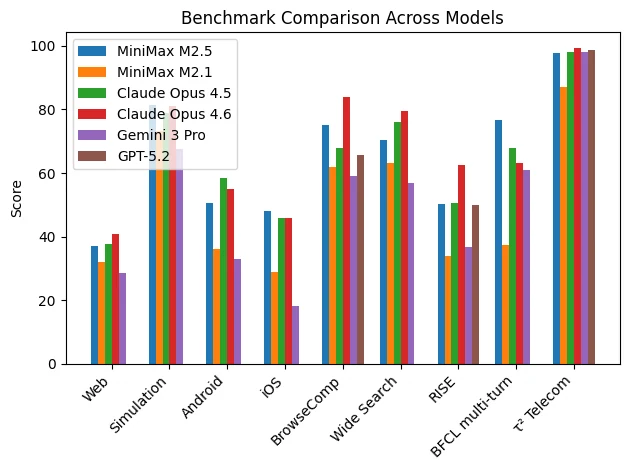
Von HuggingFace
MiniMax M2.5 dominiert nicht jeden Benchmark, erzielt aber konstant starke Ergebnisse bei Simulation, Retrieval und mehrschrittigem Reasoning. Sein Profil deutet auf Folgendes hin:
- Starke Koordination agentischer Aufgaben
- Robuste Retrieval- und Suchintegration
- Stabiles mehrschrittiges Reasoning
- Wettbewerbsfähige Simulation strukturierter Umgebungen
Insgesamt scheint MiniMax M2.5 eher für angewandte agentische Workflows und komplexe mehrschrittige Ausführungen optimiert zu sein als für rein akademische Reasoning-Benchmarks.
Büroautomatisierung
MiniMax M2.5 ist nicht darauf ausgelegt, abstrakte akademische Reasoning-Benchmarks oder rein mathematische Wettbewerbe zu dominieren. Seine Stärke liegt in professionellen Büroausführungsaufgaben, insbesondere solchen, die strukturierte, lieferbare Ergebnisse erfordern.
| Benchmark | MiniMax M2.5 | MiniMax M2.1 | Claude Opus 4.5 | Claude Opus 4.6 | Gemini 3 Pro | GPT-5.2 |
|---|---|---|---|---|---|---|
| GDPval-MM | 59,0 | 24,6 | 61,1 | 73,5 | 28,1 | 54,5 |
| MEWC | 74,4 | 55,6 | 82,1 | 89,8 | 78,7 | 41,3 |
| Finance Modeling | 21,6 | 17,3 | 30,1 | 33,2 | 15,0 | 20,0 |
Jetzt leistungsstarken und erschwinglichen Minimax M2.5 ausprobieren!
Geschwindigkeit von Minimax M2.5
Warum M2.5s Geschwindigkeit wichtig ist: SWE-Bench 37 % schneller zu absolvieren als M2.1 bedeutet niedrigere API-Kosten UND schnellere Iterationszyklen. Bei einer typischen Refactoring-Aufgabe über mehrere Dateien hinweg ist M2.5 in 45 Sekunden fertig, M2.1 benötigt 70 Sekunden – das spart bei Skalierung sowohl Zeit als auch Geld.
Warum MiniMax M2.5 auf Novita AI?
Novita AI bietet das beste Kosten-Leistungs-Verhältnis für den Produktionseinsatz von MiniMax M2.5. Während ein Selbsthosting 4-8 H100-GPUs erfordert (mindestens 5,80 $/h), kostet Novitas serverlose API nur 0,30 $ Input / 1,20 $ Output pro 1M Tokens – ohne Infrastruktur-Overhead, mit sofortiger Skalierung und 99,5 % Verfügbarkeits-SLA.
Hauptvorteile von Novita AI für MiniMax M2.5:
| Funktion | Novita AI | Selbst gehostet |
|---|---|---|
| Einrichtungszeit | 2 Minuten (API-Schlüssel) | 2-5 Tage (GPU-Bereitstellung + Einrichtung) |
| Kostenmodell | Pay-per-Token (0,30 $/1,20 $ pro 1M) | Feste GPU-Miete (5,80 $/h+ für 4×H100) |
| Skalierung | Sofortige Auto-Skalierung | Manuelle GPU-Bereitstellung |
| Wartung | Keine (Managed Service) | Hoch (vLLM, Treiber, Updates) |
| Verfügbarkeit | 99,5 % SLA | Abhängig von deiner Infrastruktur |
| Ideal für | Variable Workloads, schnelles Prototyping, Produktions-APIs | 24/7 High-Volume-Inferenz mit vorhersagbarer Last |
So greifst du auf MiniMax M2.5 auf Novita AI zu
Schritt 1: Einloggen und die Modellbibliothek aufrufen
Logge dich in dein Konto ein und klicke auf die Schaltfläche Model Library.

Schritt 2: Wähle dein Modell
Durchstöbere die verfügbaren Optionen und wähle das Modell aus, das deinen Anforderungen entspricht.

Schritt 3: Starte deine kostenlose Testversion
Beginne deine kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
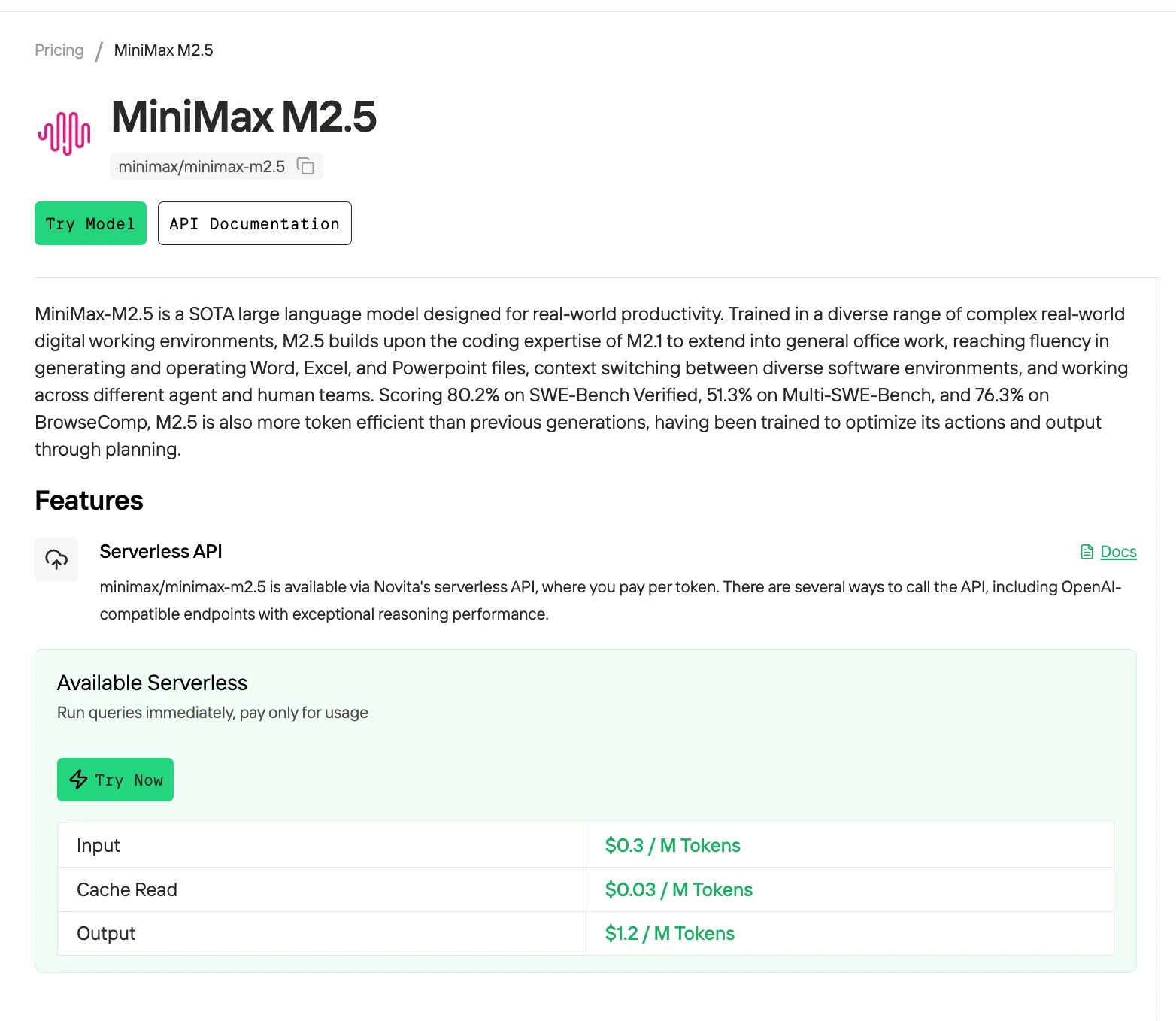
Jetzt leistungsstarken und erschwinglichen Minimax M2.5 ausprobieren!
Schritt 4: Deinen API-Schlüssel abrufen
Zur Authentifizierung bei der API stellen wir dir einen neuen API-Schlüssel zur Verfügung. Rufe die Seite „Settings“ auf und kopiere den API-Schlüssel, wie im Bild gezeigt.

Schritt 5: Die API installieren
Installiere die API mit dem für deine Programmiersprache spezifischen Paketmanager.
Nach der Installation importiere die erforderlichen Bibliotheken in deine Entwicklungsumgebung. Initialisiere die API mit deinem API-Schlüssel, um mit Novita AI LLM zu interagieren. Das ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "Du bist ein hilfsbereiter Assistent."},
{"role": "user", "content": "Hallo, wie geht es dir?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Integration von MiniMax M2.5 in beliebte Tools
Verbinde Novita AI ganz einfach mit Partnerplattformen wie Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow und Openclaw – mithilfe offizieller Integrationen und Schritt-für-Schritt-Anleitungen.
Anwendungsfälle: Wo MiniMax M2.5 glänzt
Du könntest M2.5 auch eingehend bei Softwareentwicklungsaufgaben testen und beobachten, wie es einen geschlossenen Aufgabenbereich plant und ausführt. M2.5 würde einen vollständigen, zuerst spezifizierten Plan mit UI-Drahtmodellen und API-Endpunkten ausgeben. Daraufhin würde es über 1200 Zeilen TypeScript/JavaScript-Code hinzufügen. Die Tests bestanden beim ersten Durchlauf in 22 Minuten – das ist schneller als der Durchschnitt von Claude Opus 4.6. Das Ergebnis ist eine funktionale Anwendung mit JWT-Authentifizierung und MongoDB-Integration.
Baue eine React-App mit Node.js-Backend für die Benutzerauthentifizierung, inklusive Datenbankschema.
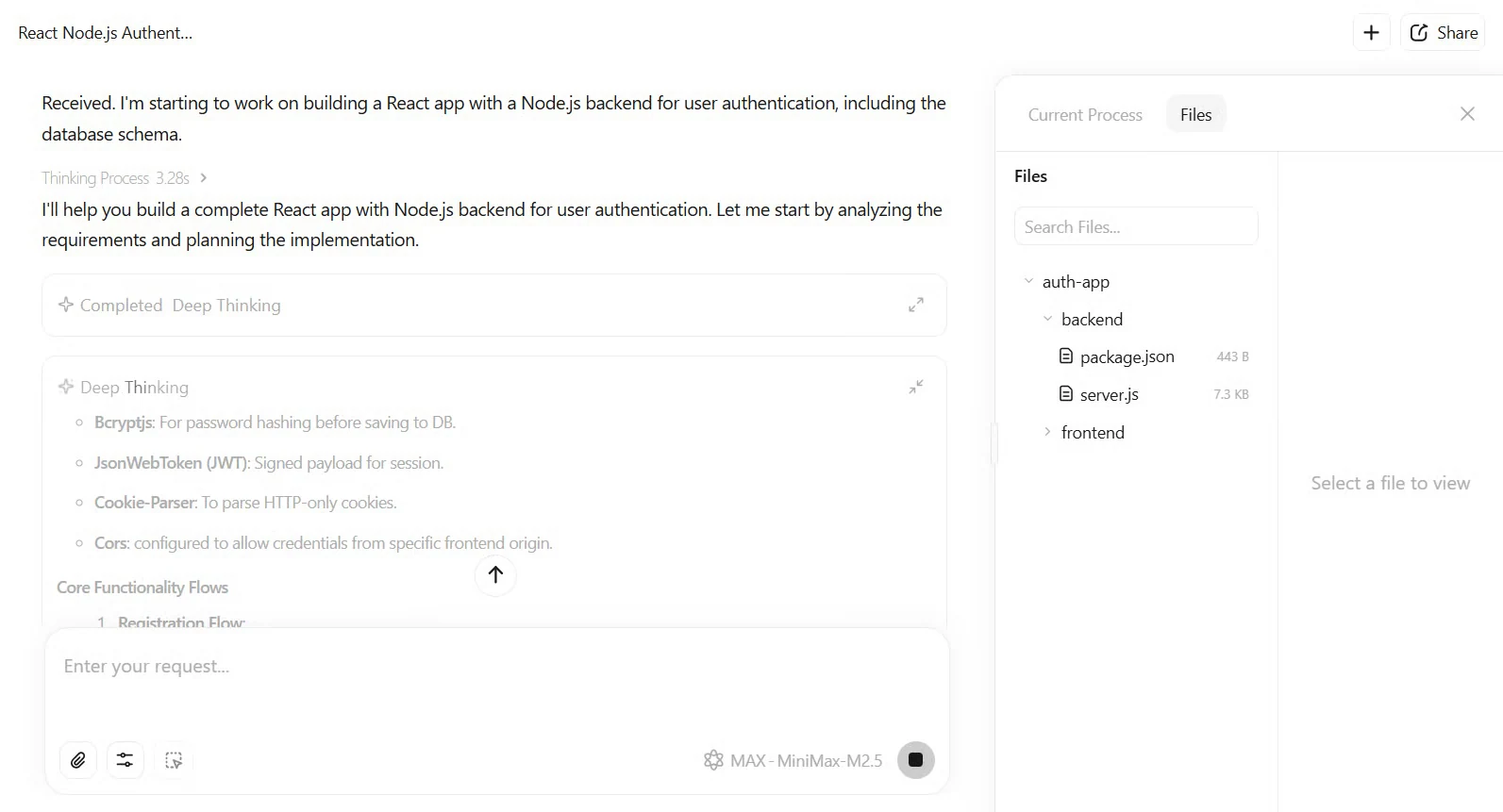
Von Website
Jetzt leistungsstarken und erschwinglichen Minimax M2.5 ausprobieren!
MiniMax M2.5 auf Novita AI liefert agentische Coding-Spitzenleistung zu 1/10 der Kosten von Premium-Alternativen. Mit 80,2 % SWE-Bench Verified, 37 % schnellerer Aufgabenerledigung als M2.1 und 0,30 $/1,20 $ pro 1M Tokens ist es die optimale Wahl für KI-Coding-Agenten in der Produktion, Büroautomatisierung und Tool-Orchestrierungs-Workflows.
Häufig gestellte Fragen
Wie schneidet MiniMax M2.5 im Vergleich zu M2.1 ab?
M2.5 ist 37 % schneller bei SWE-Bench-Aufgaben und erreicht 80,2 % vs. ~70 % auf SWE-Bench Verified. Beide kosten gleich viel (0,30 $/1,20 $ pro 1M Tokens auf Novita), daher ist M2.5 das klare Upgrade.
Kann ich MiniMax M2.5 selbst hosten anstatt die Novita-API zu nutzen?
Ja, aber es werden 4-8 H100-GPUs benötigt (mindestens 5,80 $/h auf Novita GPU-Instanzen). Selbsthosting lohnt sich wirtschaftlich erst ab 500M Tokens/Monat – für die meisten Entwickler ist die API weitaus kosteneffizienter.
Unterstützt MiniMax M2.5 Function Calling?
Ja. M2.5 wurde umfassend auf Tool-Nutzung und Function Calling in über 200.000 realen Umgebungen trainiert und erzielt branchenführende Leistung bei BrowseComp (76,3 %) und Wide-Search-Benchmarks.
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen zu bauen, bereitzustellen und zu skalieren – mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz.
Empfohlene Lektüre



