

Große Sprachmodelle (LLMs) verändern die Technologie und treiben virtuelle Assistenten, Chatbots und automatisierte Inhalte an. Aber arbeitet Ihr Modell optimal?
Die Antwort liegt in LLM-Metriken – Schlüsselindikatoren für Leistung, Reaktionsfähigkeit, Skalierbarkeit und Beobachtbarkeit. In diesem Leitfaden erkunden wir die wesentlichen Metriken und zeigen Ihnen, wie Sie Ihr System für optimale Effizienz optimieren und gleichzeitig die Beobachtbarkeit verbessern.
Was sind LLM-Metriken?
Die Bausteine der KI-Leistung
LLM-Metriken sind quantitative Messgrößen, die bewerten, wie gut große Sprachmodelle funktionieren. Sie liefern Einblicke in den Systemdurchsatz, die Zuverlässigkeit und die Reaktionsfähigkeit – und helfen Entwicklern, hohe Leistung und Benutzerzufriedenheit aufrechtzuerhalten.
Warum sollten Sie sich um LLM-Metriken kümmern?
- Leistung in Echtzeit überwachen: Metriken decken Ineffizienzen und Engpässe auf.
- Nahtlos skalieren: Stellen Sie sicher, dass Ihr Modell erhöhte Nachfrage ohne Ausfälle bewältigt.
- Kosten optimieren: Nutzen Sie Metriken, um Ressourcen effektiv zuzuweisen und Ausgaben zu senken.
- Benutzererfahrung verbessern: Steigern Sie Zuverlässigkeit und Reaktionsfähigkeit für mehr Zufriedenheit.
Die wichtigsten Metriken für den LLM-Erfolg
Hier betrachten wir die wesentlichen Metriken zur Überwachung und Optimierung von LLMs sowie umsetzbare Tipps zur Nutzung dieser Erkenntnisse.
1. Requests Per Minute (RPM): Messen Sie den Durchsatz Ihres Systems
Was sind Requests Per Minute?
Requests Per Minute erfasst die Anzahl der Inferenzanfragen, die in einer Minute verarbeitet werden, und liefert ein genaues Maß für den Systemdurchsatz.
Formel:
RPM = Gesamtzahl der Anfragen ÷ Zeit (in Minuten)
Beispiel:
Wenn Ihr System 500 Anfragen in einer Minute verarbeitet, beträgt der RPM 500.
Warum wichtig:
- Hoher RPM zeigt an, dass Ihr System mehr Anfragen bewältigen kann, was eine bessere Skalierbarkeit unterstützt.
- Nützlich, um Spitzenlastzeiten zu identifizieren und Infrastruktur-Upgrades zu planen.
Profitipps:
- Überwachen Sie RPM-Trends, um Nutzungsspitzen vorherzusehen.
- Skalieren Sie horizontal (mehr Server hinzufügen) oder vertikal (vorhandene Server aufrüsten), um die Leistung zu erhalten.
2. Request Success Rate (RSR): Zuverlässigkeit sicherstellen
Was ist die Request Success Rate?
Die Request Success Rate gibt den Prozentsatz der Anfragen an, die gültige Antworten zurückgeben, und gibt Aufschluss über die Zuverlässigkeit des Systems.
Formel:
Request Success Rate (%) = (Erfolgreiche Anfragen ÷ Gesamtzahl der Anfragen) × 100
Beispiel:
Wenn 900 von 1.000 Anfragen erfolgreich sind, beträgt die Request Success Rate 90 %.
Warum wichtig:
- Zeigt an, wie zuverlässig Ihr System ist.
- Eine niedrige Request Success Rate kann auf Ressourcenengpässe, Fehler oder Netzwerkprobleme hinweisen.
Profitipps:
- Überwachen Sie regelmäßig Einbrüche der Request Success Rate und untersuchen Sie diese.
- Optimieren Sie Pipelines und beheben Sie Infrastrukturprobleme, um die Zuverlässigkeit zu verbessern.
3. Average Tokens Per Request (ATPR): Komplexität verstehen
Was sind Average Tokens Per Request?
Average Tokens Per Request erfasst die durchschnittliche Anzahl von Tokens (Eingabe + Ausgabe), die Ihr Modell pro Anfrage verarbeitet.
Formel:
Average Tokens Per Request = Verarbeitete Tokens insgesamt ÷ Anfragen insgesamt
Beispiel:
Wenn Ihr System 300 Tokens über 10 Anfragen verarbeitet, beträgt der ATPR 30.
Warum wichtig:
- Spiegelt die Komplexität der Anfragen wider.
- Höhere Token-Anzahlen erfordern mehr Ressourcen und erhöhen die Verarbeitungskosten.
Profitipps:
- Analysieren Sie die Token-Verteilung, um Batching-Strategien zu optimieren.
- Verwalten Sie tokenlastige Anfragen, um unnötige Kosten zu vermeiden.
4. End-to-End-Latenz (e2e_latency): Gesamtreaktionszeit verfolgen
Was ist die End-to-End-Latenz?
Die End-to-End-Latenz misst die Gesamtzeit vom Empfang einer Anfrage bis zur vollständigen Antwort.
Formel:
e2e_latency = Zeitpunkt der vollständigen Antwort − Zeitpunkt der Anfrage
Beispiel:
Wenn eine Anfrage bei 0 ms eingeht und die Antwort bei 200 ms geliefert wird, beträgt die e2e_latency 200 ms.
Warum wichtig:
- Entscheidend für Echtzeitanwendungen wie Chatbots oder virtuelle Assistenten.
- Hohe e2e_latency kann Benutzer frustrieren und die Zufriedenheit verringern.
Profitipps:
- Zerlegen Sie die e2e_latency in Komponenten (z. B. Inferenzzeit, Netzwerkverzögerung), um Probleme zu identifizieren.
- Nutzen Sie Caching und optimieren Sie Inferenz-Pipelines, um die Reaktionszeiten zu verbessern.
5. Time to First Token (TTFT): Initiale Reaktionsfähigkeit verbessern
Was ist Time to First Token?
Time to First Token misst, wie schnell das Modell das erste Token seiner Antwort generiert.
Formel:
TTFT = Zeitpunkt der ersten Token-Generierung − Zeitpunkt der Anfrage
Beispiel:
Wenn das erste Token 150 ms nach der Anfrage generiert wird, beträgt der TTFT 150 ms.
Warum wichtig:
- Entscheidend für Echtzeit-Benutzerinteraktionen. Ein schneller TTFT verbessert die wahrgenommene Systemreaktionsfähigkeit.
Profitipps:
- Laden Sie Modelle vor oder wärmen Sie sie auf, um Verzögerungen zu reduzieren.
- Überwachen Sie TTFT zusammen mit der e2e_latency für ein vollständiges Bild der Reaktionsfähigkeit.
6. Time Per Output Token (TPOT): Token-Generierung optimieren
Was ist Time Per Output Token?
Time Per Output Token misst die durchschnittliche Zeit, die benötigt wird, um jedes Token nach dem ersten zu generieren.
Formel:
TPOT = Gesamtzeit zur Generierung der Tokens nach dem ersten Token ÷ Anzahl der nach dem ersten Token generierten Tokens
Beispiel:
Wenn es 100 ms dauert, um 10 Tokens zu generieren, beträgt der TPOT 10 ms pro Token.
Warum wichtig:
- Spiegelt die Effizienz der Token-Generierung wider, insbesondere bei textlastigen Ausgaben.
- Hoher TPOT kann bei großen Ausgaben zu langsameren Antworten führen.
Profitipps:
- Nutzen Sie Parallelisierung oder feinabgestimmte Modelle, um die Token-Generierungsgeschwindigkeit zu verbessern.
- Überwachen Sie TPOT zusammen mit anderen Latenzmetriken, um die Benutzererfahrung zu optimieren.
Schritt-für-Schritt-Anleitung: LLM-Metriken beobachten
1. Definieren Sie Schlüsselmetriken
Identifizieren Sie zunächst die relevantesten Metriken für Ihre LLM-Anwendung. Berücksichtigen Sie Faktoren wie Benutzererfahrung, Systemleistung und Skalierbarkeit. Zum Beispiel:
- Echtzeitanwendungen: Priorisieren Sie Metriken wie End-to-End-Latenz und Time to First Token.
- Systeme mit hohem Volumen: Konzentrieren Sie sich auf Durchsatz (Requests Per Minute) und Zuverlässigkeit (Request Success Rate).
- Kostenmanagement: Überwachen Sie die Token-Nutzung (Average Tokens Per Request und Time Per Output Token).
2. Testen Sie Systemgrenzen mit Stresstests
- Simulieren Sie Szenarien mit hoher Nachfrage, um die Systemleistung unter Druck zu bewerten.
- Identifizieren Sie Engpässe und planen Sie bei Bedarf die Skalierung.
3. Profilieren Sie die Leistung Ihres Modells
- Zerlegen Sie die Latenz in Komponenten (z. B. Inferenzzeit, Netzwerkverzögerung), um Ineffizienzen zu identifizieren.
- Verfolgen Sie Token-Generierungszeiten, um die Verarbeitungsgeschwindigkeit zu analysieren und Arbeitsabläufe zu optimieren.
4. Legen Sie Alarme für Schlüsselmetriken fest
- Definieren Sie Schwellenwerte für kritische Metriken wie Requests Per Minute und End-to-End-Latenz.
- Automatisieren Sie Benachrichtigungen, um Leistungsprobleme schnell zu erkennen und zu beheben.
5. Iterieren und optimieren
- Überprüfen Sie kontinuierlich Leistungsdaten, um Trends zu identifizieren.
- Optimieren Sie Infrastruktur, Pipelines und Modellarchitektur, um die Leistung zu verbessern.
Echtzeit-Überwachung: LLM-Metriken auf Novita AI beobachten
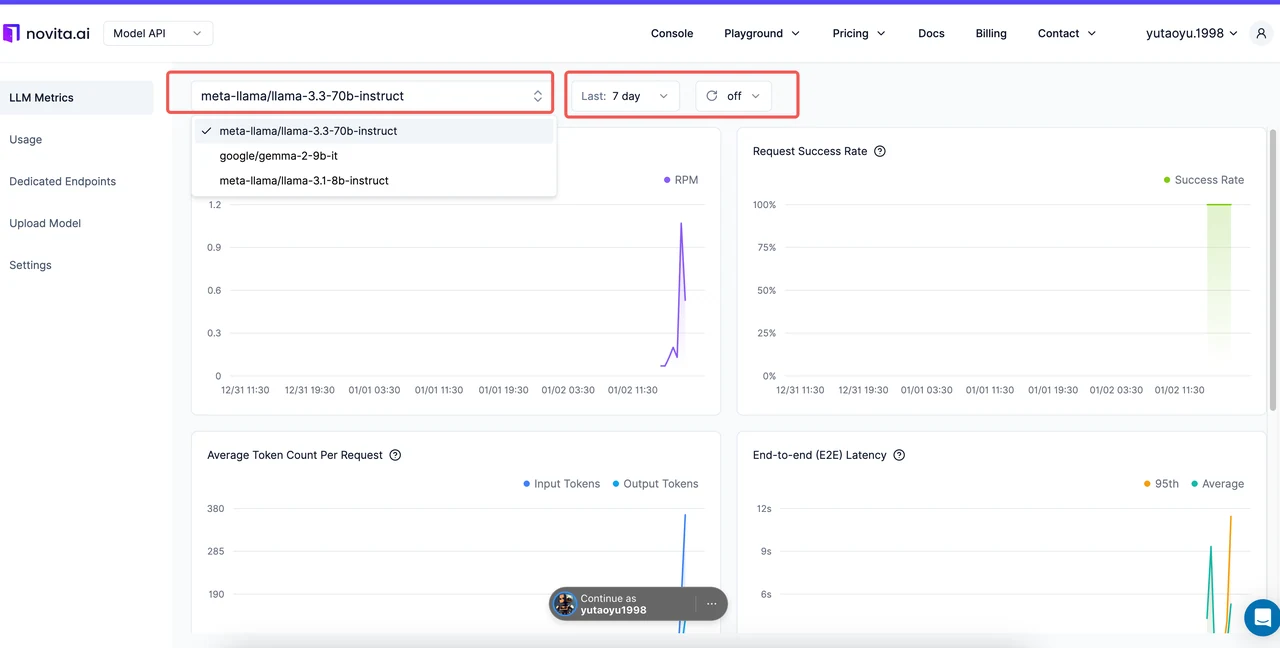
Novita AI vereinfacht die Metrikverfolgung mit seiner dedizierten Metrics Console und bietet Echtzeiteinblicke in Ihre LLM-Bereitstellungen.
| Metrik | Was auf Novita AI zu überwachen ist |
|---|---|
| Requests Per Minute | Verfolgen Sie den Durchsatz, um sicherzustellen, dass Ihr System Traffic-Spitzen effizient bewältigt. |
| Request Success Rate | Beobachten Sie Trends, um Zuverlässigkeitsprobleme zu identifizieren und zu beheben. |
| Average Tokens Per Request | Analysieren Sie die Token-Nutzung, um Kosten effektiv zu verwalten. |
| End-to-End-Latenz | Überwachen Sie die Latenz, um eine reibungslose Benutzererfahrung zu gewährleisten. |
| Time to First Token | Messen Sie die anfängliche Reaktionsfähigkeit, um Echtzeitanwendungen zu verbessern. Diese Metrik wird nur für Streaming-Anfragen verfolgt, bei denen der Parameter stream=true aktiviert ist. |
| Time Per Output Token | Optimieren Sie die Token-Generierungsgeschwindigkeit für längere Antworten. Diese Metrik wird nur für Streaming-Anfragen verfolgt, bei denen der Parameter stream=true aktiviert ist. |
Erkunden Sie LLM-Metriken ausführlicher bei Novia AI.
Tipps zur Nutzung der Metrics Console von Novita AI
- Testen Sie Ihr Modell im LLM Playground , um Metrikänderungen in Echtzeit zu beobachten.
- Verwenden Sie Filter, um bestimmte Metriken während Spitzen- und Nebenzeiten zu analysieren.
- Passen Sie die Ressourcenzuweisung basierend auf Trends an, um eine hohe Leistung aufrechtzuerhalten.
Abschließende Gedanken: Warum LLM-Metriken entscheidend sind
LLM-Metriken sind das Rückgrat erfolgreicher KI-Bereitstellungen. Durch die Verfolgung von Metriken wie Requests Per Minute (RPM), Request Success Rate, End-to-End-Latenz und Time Per Output Token können Sie umsetzbare Erkenntnisse gewinnen, um die Leistung, Skalierbarkeit und Zuverlässigkeit Ihres Systems zu optimieren.
Plattformen wie Novita AI erleichtern die Überwachung und das Reagieren auf diese Metriken in Echtzeit, sodass Ihre LLMs stets optimal arbeiten. Beginnen Sie noch heute damit, LLM-Metriken zu nutzen, um schnellere, intelligentere und effizientere KI-Lösungen zu liefern.
Häufig gestellte Fragen
Was sind LLM-Metriken?
LLM-Metriken sind quantitative Messgrößen, die die Leistung großer Sprachmodelle (LLMs) bewerten, mit Fokus auf Aspekte wie Durchsatz, Zuverlässigkeit und Reaktionsfähigkeit.
Warum sind LLM-Metriken wichtig?
LLM-Metriken sind entscheidend für die Echtzeitüberwachung zur Identifizierung von Ineffizienzen, zur Sicherstellung der Skalierbarkeit bei Nachfrage, zur Kostenoptimierung durch fundierte Ressourcenzuweisung und zur Verbesserung der Benutzererfahrung durch gesteigerte Zuverlässigkeit und Reaktionsfähigkeit.
Wie kann ich die LLM-Leistung effektiv überwachen?
Um die LLM-Leistung effektiv zu überwachen, definieren Sie relevante Metriken, führen Sie Stresstests durch, profilieren Sie die Leistung, um Ineffizienzen zu identifizieren, legen Sie Alarme für kritische Schwellenwerte fest und überprüfen und optimieren Sie regelmäßig basierend auf Leistungsdaten.
Wie misst man die Genauigkeit eines LLM?
Die Genauigkeit eines LLM wird mit Metriken wie Präzision, Recall, F1-Score und Gesamtgenauigkeitsprozentsatz gemessen, die bewerten, wie genau die Ausgaben des Modells mit den erwarteten Antworten übereinstimmen.
Wie validiert man die LLM-Leistung?
Die Validierung der LLM-Leistung umfasst Benchmarking gegen standardisierte Datensätze zur Bewertung von Genauigkeit, Flüssigkeit, Kohärenz und Relevanz, häufig unter Verwendung von Ground-Truth-Evaluierungen mit gekennzeichneten Datensätzen.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen stärkt. Integrierte APIs, serverlos, GPU-Instanz – die kosteneffizienten Tools, die Sie brauchen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.
Empfohlene Lektüre



