

大規模言語モデル(LLM)は、テクノロジーを変革し、バーチャルアシスタント、チャットボット、自動コンテンツ生成を支えています。しかし、あなたのモデルは最高のパフォーマンスを発揮していますか?
その答えは、LLMメトリクス(パフォーマンス、応答性、スケーラビリティ、可観測性を示す主要な指標)にあります。このガイドでは、主要なLLMメトリクスを解説し、可観測性を高めながらシステムを最大効率に最適化する方法を紹介します。
LLMメトリクスとは?
AIパフォーマンスの基本構成要素
LLMメトリクスは、大規模言語モデルのパフォーマンスを評価する定量的な指標です。これらの指標は、システムのスループット、信頼性、応答性に関する洞察を提供し、開発者が高いパフォーマンスとユーザー満足度を維持するのに役立ちます。
LLMメトリクスが重要な理由
- リアルタイムのパフォーマンス監視:メトリクスは非効率性やボトルネックを明らかにします。
- シームレスなスケーリング:需要増加に対応できるようモデルを強化します。
- コスト最適化:メトリクスを活用してリソースを適切に割り当て、コストを削減します。
- ユーザーエクスペリエンスの向上:信頼性と応答性を改善し、満足度を高めます。
LLM成功のために追跡すべき主要メトリクス
ここでは、LLMの監視と最適化に欠かせないメトリクスと、その洞察を活用するための実践的なヒントを紹介します。
1. 1分あたりのリクエスト数(RPM):システムのスループットを測定する
RPMとは?
RPMは、1分間に処理された推論リクエストの数を追跡し、システムのスループットを正確に測定します。
計算式:
RPM = 総リクエスト数 ÷ 時間(分)
例:
システムが1分間に500リクエストを処理した場合、RPMは500です。
重要性:
- RPMが高いほど、システムはより多くのリクエストを処理でき、スケーラビリティが向上します。
- ピーク需要期間を特定し、インフラストラクチャのアップグレードを計画するのに役立ちます。
プロのヒント:
- RPMのトレンドを監視して、使用量の急増を予測しましょう。
- 水平スケーリング(サーバー追加)または垂直スケーリング(既存サーバーの強化)でパフォーマンスを維持しましょう。
2. リクエスト成功率(RSR):信頼性を確保する
RSRとは?
リクエスト成功率は、有効な応答を返したリクエストの割合を示し、システムの信頼性を把握します。
計算式:
リクエスト成功率(%) = (成功リクエスト数 ÷ 総リクエスト数) × 100
例:
1,000リクエスト中900が成功した場合、リクエスト成功率は90%です。
重要性:
- システムの信頼性を示します。
- 低いRSRは、リソース不足、エラー、ネットワークの問題を示している可能性があります。
プロのヒント:
- RSRの低下を定期的に監視し、原因を調査しましょう。
- パイプラインを最適化し、インフラストラクチャの問題に対処して信頼性を向上させましょう。
3. リクエストあたりの平均トークン数(ATPR):複雑さを理解する
ATPRとは?
リクエストあたりの平均トークン数は、モデルが1リクエストあたりに処理するトークン(入力+出力)の平均数を追跡します。
計算式:
リクエストあたりの平均トークン数 = 総処理トークン数 ÷ 総リクエスト数
例:
システムが10リクエストで300トークンを処理した場合、ATPRは30です。
重要性:
- リクエストの複雑さを反映します。
- トークン数が多いほど、より多くのリソースが必要となり、処理コストが増加します。
プロのヒント:
- トークン分布を分析して、バッチ処理戦略を最適化しましょう。
- トークン数の多いリクエストを管理して、不必要なコストを回避しましょう。
4. エンドツーエンドレイテンシー(e2e_latency):総応答時間を追跡する
e2eレイテンシーとは?
エンドツーエンドレイテンシーは、リクエストを受信してから完全な応答を送信するまでの合計時間を測定します。
計算式:
e2e_latency = 完全応答の時刻 − リクエストの時刻
例:
リクエストが0msに受信され、応答が200msに送信された場合、e2e_latencyは200msです。
重要性:
- チャットボットやバーチャルアシスタントなどのリアルタイムアプリケーションでは重要です。
- e2e_latencyが高いと、ユーザーのフラストレーションや満足度低下につながります。
プロのヒント:
- e2e_latencyを推論時間、ネットワーク遅延などのコンポーネントに分解して問題を特定しましょう。
- キャッシュや推論パイプラインの最適化で応答時間を改善しましょう。
5. 最初のトークンまでの時間(TTFT):初期応答性を向上させる
TTFTとは?
最初のトークンまでの時間は、モデルが応答の最初のトークンを生成する速度を測定します。
計算式:
TTFT = 最初のトークン生成の時刻 − リクエストの時刻
例:
リクエストから150ms後に最初のトークンが生成された場合、TTFTは150msです。
重要性:
- リアルタイムのユーザーインタラクションでは重要です。
- TTFTが速いと、システムの応答性が向上して認識されます。
プロのヒント:
- モデルをプリロードまたはウォームアップして遅延を減らしましょう。
- TTFTをe2e_latencyと併せて監視し、応答性を総合的に把握しましょう。
6. 出力トークンあたりの時間(TPOT):トークン生成を最適化する
TPOTとは?
出力トークンあたりの時間は、最初のトークン以降の各トークンの生成にかかる平均時間を測定します。
計算式:
TPOT = 最初のトークン以降のトークン生成にかかる総時間 ÷ 最初のトークン以降に生成されたトークン数
例:
10トークンの生成に100msかかった場合、TPOTはトークンあたり10msです。
重要性:
- テキスト量が多い出力におけるトークン生成効率を反映します。
- TPOTが高いと、大きな出力の応答が遅くなる可能性があります。
プロのヒント:
- 並列化やモデルのファインチューニングでトークン生成速度を向上させましょう。
- TPOTを他のレイテンシーメトリクスと併せて監視し、ユーザーエクスペリエンスを最適化しましょう。
ステップバイステップガイド:LLMメトリクスの観測方法
1. 主要メトリクスを定義する
まず、LLMアプリケーションに最も関連性の高いメトリクスを特定します。ユーザーエクスペリエンス、システムパフォーマンス、スケーラビリティなどの要素を考慮します。例えば:
- リアルタイムアプリケーション:エンドツーエンドレイテンシーと最初のトークンまでの時間を優先します。
- 高トラフィックシステム:スループット(RPM)と信頼性(RSR)に注目します。
- コスト管理:トークン使用量(ATPRとTPOT)を監視します。
2. ストレステストでシステムの限界を試す
- 高負荷シナリオをシミュレートして、プレッシャー下でのシステムパフォーマンスを評価します。
- ボトルネックを特定し、必要に応じてスケーリングを計画します。
3. モデルのパフォーマンスをプロファイリングする
- レイテンシーを推論時間やネットワーク遅延などのコンポーネントに分解し、非効率性を特定します。
- トークン生成時間を追跡して処理速度を分析し、ワークフローを最適化します。
4. 主要メトリクスにアラートを設定する
- RPMやe2eレイテンシーなどの重要なメトリクスにしきい値を設定します。
- 通知を自動化し、パフォーマンス問題を迅速に検出・解決します。
5. 反復して最適化する
- パフォーマンスデータを継続的にレビューし、トレンドを特定します。
- インフラストラクチャ、パイプライン、モデルアーキテクチャを最適化してパフォーマンスを向上させます。
リアルタイムモニタリング:Novita AI での LLM メトリクス観測
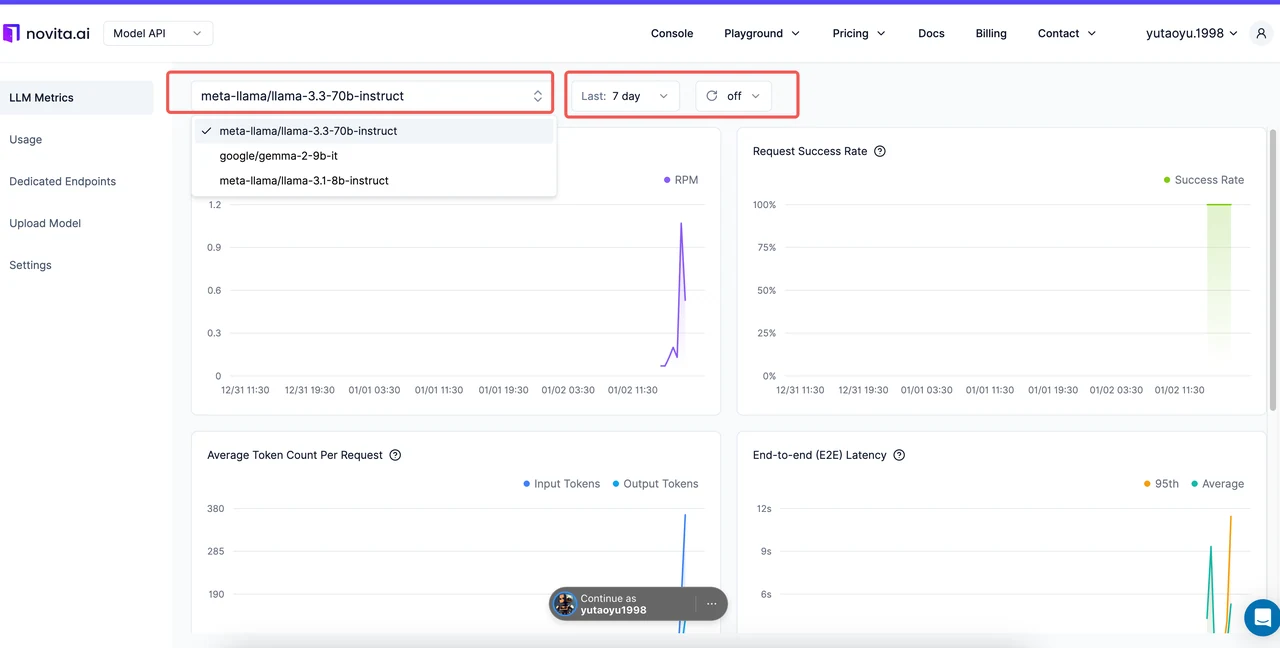
Novita AI は、専用の Metrics Console でメトリクスの追跡を簡素化し、LLM デプロイメントのリアルタイムインサイトを提供します。
| **メトリクス ** | Novita AI で監視すべき項目 |
|---|---|
| Requests Per Minute | スループットを追跡し、トラフィックスパイクにシステムが効率的に対応できるようにします。 |
| Request Success Rate | トレンドを観測して、信頼性の問題を特定しトラブルシューティングします。 |
| Average Tokens Per Request | トークン使用量を分析して、コストを効果的に管理します。 |
| End-to-End Latency | レイテンシーを監視し、スムーズなユーザーエクスペリエンスを確保します。 |
| Time to First Token | 初期応答性を測定し、リアルタイムアプリケーションを改善します。このメトリクスは、stream=true パラメータが有効なストリーミングリクエストでのみ追跡されます。 |
| Time Per Output Token | より長い応答のトークン生成速度を最適化します。このメトリクスは、stream=true パラメータが有効なストリーミングリクエストでのみ追跡されます。 |
Novita AI で LLM メトリクス をさらに詳しく見る。
Novita AI の Metrics Console を使用するためのヒント
- LLM Playground でモデルをテストし、メトリクスの変化をリアルタイムで観測します。
- フィルターを使用して、ピーク時とオフピーク時の特定のメトリクスを分析します。
- トレンドに基づいてリソース割り当てを調整し、高いパフォーマンスを維持します。
最後に:LLM メトリクスが不可欠な理由
LLM メトリクスは、AI デプロイメント成功の基盤です。Requests Per Minute(RPM)、Request Success Rate、End-to-End Latency、Time Per Output Token などのメトリクスを追跡することで、システムのパフォーマンス、スケーラビリティ、信頼性を最適化するための実用的なインサイトを得られます。
Novita AI のようなプラットフォームを使用すれば、これらのメトリクスをリアルタイムで簡単に監視・対応でき、LLM が常に最高の状態で動作することを確保できます。今すぐ LLM メトリクスを活用して、より高速でスマートかつ効率的な AI ソリューションを提供しましょう。
よくある質問
LLM メトリクスとは何ですか?
LLM メトリクスは、大規模言語モデル(LLM)のパフォーマンスを評価する定量的な指標であり、スループット、信頼性、応答性などの側面に焦点を当てています。
なぜ LLM メトリクスが重要なのですか?
LLM メトリクスは、非効率性を特定するためのリアルタイムモニタリング、需要に応じたスケーラビリティの確保、情報に基づいたリソース割り当てによるコスト最適化、そして信頼性と応答性の向上によるユーザーエクスペリエンスの向上に不可欠です。
LLM パフォーマンスを効果的に監視するにはどうすればよいですか?
LLM パフォーマンスを効果的に監視するには、関連するメトリクスを定義し、ストレステストを実施し、パフォーマンスをプロファイリングして非効率性を特定し、重要なしきい値にアラートを設定し、パフォーマンスデータを定期的にレビューして最適化します。
LLM の精度はどのように測定しますか?
LLM の精度は、適合率、再現率、F1 スコア、全体的な精度パーセンテージなどのメトリクスを使用して測定します。これらは、モデルの出力が期待される応答にどの程度一致しているかを評価します。
LLM パフォーマンスを検証するにはどうすればよいですか?
LLM パフォーマンスの検証には、標準化されたデータセットに対するベンチマークテストを実施し、正確性、流暢性、一貫性、関連性を評価します。多くの場合、ラベル付きデータセットを使用したグラウンドトゥルース評価が用いられます。
Novita AI は、AI の野心を実現するオールインワンクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンスなど、コスト効率の高いツールを提供します。インフラストラクチャの手間を省き、無料で始めて、AI ビジョンを現実にしましょう。
おすすめの記事



