

Los modelos de lenguaje grandes (LLM) están transformando la tecnología, impulsando asistentes virtuales, chatbots y contenido automatizado. Pero, ¿está tu modelo rindiendo al máximo?
La respuesta está en las métricas de LLM: indicadores clave de rendimiento, capacidad de respuesta, escalabilidad y observabilidad. En esta guía, exploraremos las métricas esenciales y te mostraremos cómo optimizar tu sistema para lograr la máxima eficiencia mientras mejoras su observabilidad.
¿Qué son las métricas de LLM?
Los componentes básicos del rendimiento de la IA
Las métricas de LLM son medidas cuantitativas que evalúan qué tan bien se desempeñan los modelos de lenguaje grandes. Proporcionan información sobre el rendimiento, la confiabilidad y la capacidad de respuesta del sistema, ayudando a los desarrolladores a mantener un alto rendimiento y satisfacción del usuario.
¿Por qué deberían importarte las métricas de LLM?
- Monitoreo del rendimiento en tiempo real: Las métricas revelan ineficiencias y cuellos de botella.
- Escalado sin problemas: Asegura que tu modelo maneje una mayor demanda sin colapsar.
- Optimización de costos: Usa las métricas para asignar recursos de manera efectiva y reducir gastos.
- Mejora de la experiencia del usuario: Aumenta la confiabilidad y la capacidad de respuesta para una mejor satisfacción.
Las métricas clave a seguir para el éxito de los LLM
Aquí exploraremos las métricas esenciales para monitorear y optimizar los LLM, junto con consejos prácticos para aprovechar estos conocimientos.
1. Solicitudes por minuto (RPM): mide el rendimiento de tu sistema
¿Qué son las solicitudes por minuto?
Las solicitudes por minuto rastrean la cantidad de solicitudes de inferencia procesadas en un minuto, proporcionándote una medida precisa del rendimiento de tu sistema.
Fórmula:
RPM = Solicitudes totales ÷ Tiempo (en minutos)
Ejemplo:
Si tu sistema procesa 500 solicitudes en un minuto, el RPM es 500.
¿Por qué es importante?
- Un RPM alto indica que tu sistema puede manejar más solicitudes, lo que respalda una mejor escalabilidad.
- Útil para identificar períodos de máxima demanda y planificar actualizaciones de infraestructura.
Consejos profesionales:
- Monitorea las tendencias de RPM para anticipar picos de uso.
- Escala horizontalmente (agrega más servidores) o verticalmente (agrega más potencia a los servidores existentes) para mantener el rendimiento.
2. Tasa de éxito de solicitudes (RSR): asegura la confiabilidad
¿Qué es la tasa de éxito de solicitudes?
La tasa de éxito de solicitudes muestra el porcentaje de solicitudes que devuelven respuestas válidas, brindando información sobre la confiabilidad del sistema.
Fórmula:
Tasa de éxito de solicitudes (%) = (Solicitudes exitosas ÷ Solicitudes totales) × 100
Ejemplo:
Si 900 de 1000 solicitudes tienen éxito, la tasa de éxito de solicitudes es del 90%.
¿Por qué es importante?
- Indica qué tan confiable es tu sistema.
- Una tasa de éxito de solicitudes baja puede indicar limitaciones de recursos, errores o problemas de red.
Consejos profesionales:
- Monitorea e investiga regularmente las caídas en la tasa de éxito de solicitudes.
- Optimiza los pipelines y soluciona problemas de infraestructura para mejorar la confiabilidad.
3. Tokens promedio por solicitud (ATPR): comprende la complejidad
¿Qué son los tokens promedio por solicitud?
Los tokens promedio por solicitud rastrean el número promedio de tokens (entrada + salida) que tu modelo procesa por solicitud.
Fórmula:
Tokens promedio por solicitud = Total de tokens procesados ÷ Solicitudes totales
Ejemplo:
Si tu sistema procesa 300 tokens en 10 solicitudes, el promedio de tokens por solicitud es 30.
¿Por qué es importante?
- Refleja la complejidad de las solicitudes.
- Cantidades más altas de tokens requieren más recursos y aumentan los costos de procesamiento.
Consejos profesionales:
- Analiza la distribución de tokens para optimizar las estrategias de agrupación (batching).
- Gestiona las solicitudes con muchos tokens para evitar costos innecesarios.
4. Latencia de extremo a extremo (e2e_latency): rastrea el tiempo total de respuesta
¿Qué es la latencia de extremo a extremo?
La latencia de extremo a extremo mide el tiempo total desde que se recibe una solicitud hasta que se entrega la respuesta completa.
Fórmula:
e2e_latency = Tiempo de respuesta completa − Tiempo de solicitud
Ejemplo:
Si una solicitud se recibe en 0 ms y la respuesta se entrega en 200 ms, la e2e_latency es de 200 ms.
¿Por qué es importante?
- Es crítica para aplicaciones en tiempo real como chatbots o asistentes virtuales.
- Una e2e_latency alta puede frustrar a los usuarios y reducir la satisfacción.
Consejos profesionales:
- Desglosa la e2e_latency en componentes (por ejemplo, tiempo de inferencia, retardo de red) para identificar problemas.
- Usa almacenamiento en caché y optimiza los pipelines de inferencia para mejorar los tiempos de respuesta.
5. Tiempo hasta el primer token (TTFT): mejora la capacidad de respuesta inicial
¿Qué es el tiempo hasta el primer token?
El tiempo hasta el primer token mide la rapidez con la que el modelo genera el primer token de su respuesta.
Fórmula:
TTFT = Tiempo de generación del primer token − Tiempo de solicitud
Ejemplo:
Si el primer token se genera 150 ms después de la solicitud, el TTFT es de 150 ms.
¿Por qué es importante?
- Es crucial para las interacciones de usuario en tiempo real.
- Un TTFT rápido mejora la percepción de la capacidad de respuesta del sistema.
Consejos profesionales:
- Precarga o calienta los modelos para reducir demoras.
- Monitorea el TTFT junto con la e2e_latency para obtener una visión completa de la capacidad de respuesta.
6. Tiempo por token de salida (TPOT): optimiza la generación de tokens
¿Qué es el tiempo por token de salida?
El tiempo por token de salida mide el tiempo promedio que se tarda en generar cada token después del primero.
Fórmula:
TPOT = Tiempo total para generar tokens después del primer token ÷ Tokens generados después del primer token
Ejemplo:
Si se necesitan 100 ms para generar 10 tokens, el TPOT es de 10 ms por token.
¿Por qué es importante?
- Refleja la eficiencia de la generación de tokens, especialmente para salidas con mucho texto.
- Un TPOT alto puede provocar respuestas más lentas para salidas grandes.
Consejos profesionales:
- Usa paralelización o ajusta modelos para mejorar la velocidad de generación de tokens.
- Monitorea el TPOT junto con otras métricas de latencia para optimizar la experiencia del usuario.
Guía paso a paso: cómo observar las métricas de LLM
1. Define las métricas clave
Comienza por identificar las métricas más relevantes para tu aplicación LLM. Considera factores como la experiencia del usuario, el rendimiento del sistema y la escalabilidad. Por ejemplo:
- Aplicaciones en tiempo real: Prioriza métricas como la latencia de extremo a extremo y el tiempo hasta el primer token.
- Sistemas de alto volumen: Concéntrate en el rendimiento (solicitudes por minuto) y la confiabilidad (tasa de éxito de solicitudes).
- Gestión de costos: Monitorea el uso de tokens (tokens promedio por solicitud y tiempo por token de salida).
2. Prueba los límites del sistema con pruebas de estrés
- Simula escenarios de alta demanda para evaluar el rendimiento del sistema bajo presión.
- Identifica cuellos de botella y planifica el escalado según sea necesario.
3. Perfila el rendimiento de tu modelo
- Desglosa la latencia en componentes (por ejemplo, tiempo de inferencia, retardo de red) para identificar ineficiencias.
- Rastrea los tiempos de generación de tokens para analizar la velocidad de procesamiento y optimizar los flujos de trabajo.
4. Configura alertas para métricas clave
- Define umbrales para métricas críticas como solicitudes por minuto y latencia de extremo a extremo.
- Automatiza las notificaciones para detectar y resolver rápidamente problemas de rendimiento.
5. Itera y optimiza
- Revisa continuamente los datos de rendimiento para identificar tendencias.
- Optimiza la infraestructura, los pipelines y la arquitectura del modelo para mejorar el rendimiento.
Monitoreo en tiempo real: observación de métricas de LLM en Novita AI
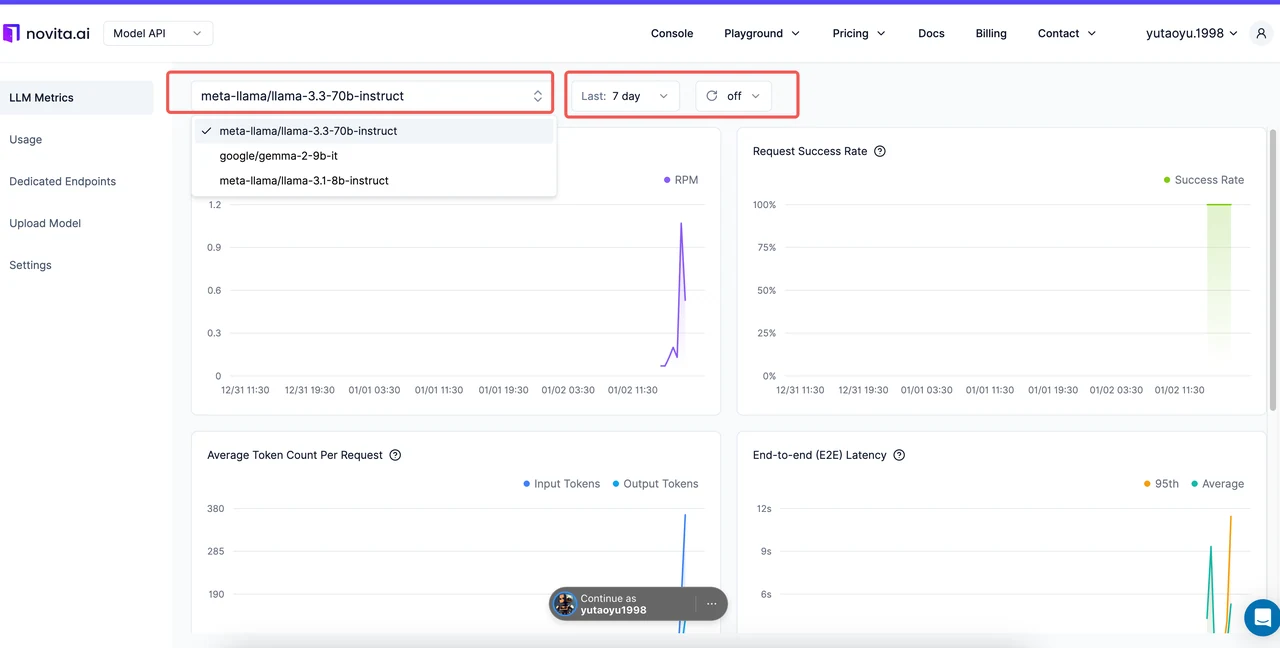
Novita AI simplifica el seguimiento de métricas con su Consola de Métricas dedicada, que proporciona información en tiempo real sobre tus implementaciones de LLM.
| Métrica | Qué monitorear en Novita AI |
|---|---|
| Solicitudes por minuto | Rastrea el rendimiento para asegurar que tu sistema maneje los picos de tráfico de manera eficiente. |
| Tasa de éxito de solicitudes | Observa las tendencias para identificar y solucionar problemas de confiabilidad. |
| Tokens promedio por solicitud | Analiza el uso de tokens para gestionar los costos de manera efectiva. |
| Latencia de extremo a extremo | Monitorea la latencia para garantizar una experiencia de usuario fluida. |
| Tiempo hasta el primer token | Mide la capacidad de respuesta inicial para mejorar las aplicaciones en tiempo real. Esta métrica solo se rastrea para solicitudes de streaming con el parámetro stream=true habilitado. |
| Tiempo por token de salida | Optimiza la velocidad de generación de tokens para respuestas más largas. Esta métrica solo se rastrea para solicitudes de streaming con el parámetro stream=true habilitado. |
Explora las métricas de LLM con más detalle en Novita AI.
Consejos para usar la Consola de Métricas de Novita AI
- Prueba tu modelo en el LLM Playground para observar los cambios en las métricas en tiempo real.
- Usa filtros para analizar métricas específicas durante las horas pico y valle.
- Ajusta la asignación de recursos según las tendencias para mantener un alto rendimiento.
Reflexiones finales: por qué las métricas de LLM son vitales
Las métricas de LLM son la columna vertebral de las implementaciones exitosas de IA. Al rastrear métricas como solicitudes por minuto (RPM), tasa de éxito de solicitudes, latencia de extremo a extremo y tiempo por token de salida, puedes obtener información procesable para optimizar el rendimiento, la escalabilidad y la confiabilidad de tu sistema.
Plataformas como Novita AI facilitan el monitoreo y la acción sobre estas métricas en tiempo real, asegurando que tus LLM siempre estén funcionando al máximo. Comienza a aprovechar las métricas de LLM hoy para ofrecer soluciones de IA más rápidas, inteligentes y eficientes.
Preguntas frecuentes
¿Qué son las métricas de LLM?
Las métricas de LLM son medidas cuantitativas que evalúan el rendimiento de los modelos de lenguaje grandes (LLM), centrándose en aspectos como el rendimiento, la confiabilidad y la capacidad de respuesta.
¿Por qué son importantes las métricas de LLM?
Las métricas de LLM son cruciales para el monitoreo en tiempo real a fin de identificar ineficiencias, garantizar la escalabilidad bajo demanda, optimizar costos mediante una asignación informada de recursos y mejorar la experiencia del usuario al aumentar la confiabilidad y la capacidad de respuesta.
¿Cómo puedo monitorear el rendimiento de los LLM de manera efectiva?
Para monitorear el rendimiento de los LLM de manera efectiva, define métricas relevantes, realiza pruebas de estrés, perfila el rendimiento para identificar ineficiencias, configura alertas para umbrales críticos y revisa y optimiza regularmente según los datos de rendimiento.
¿Cómo se mide la precisión de un LLM?
La precisión de un LLM se mide utilizando métricas como precisión, exhaustividad (recall), puntuación F1 y porcentaje de precisión general, que evalúan qué tan cerca coinciden las salidas del modelo con las respuestas esperadas.
¿Cómo validar el rendimiento de un LLM?
Validar el rendimiento de un LLM implica realizar evaluaciones comparativas con conjuntos de datos estandarizados para evaluar precisión, fluidez, coherencia y relevancia, a menudo utilizando evaluaciones de verdad fundamental con conjuntos de datos etiquetados.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, serverless, instancias GPU: las herramientas rentables que necesitas. Elimina infraestructura, comienza gratis y haz realidad tu visión de IA.
Lectura recomendada



