

Les grands modèles de langage (LLM) transforment la technologie en alimentant des assistants virtuels, des chatbots et la génération automatisée de contenu. Mais votre modèle fonctionne-t-il au meilleur de ses capacités ?
La réponse réside dans les métriques LLM — des indicateurs clés de performance, réactivité, évolutivité et observabilité. Ce guide explore les métriques essentielles et vous montre comment optimiser votre système pour une efficacité maximale tout en renforçant son observabilité.
Que sont les métriques LLM ?
Les fondations de la performance IA
Les métriques LLM sont des mesures quantitatives qui évaluent la performance des grands modèles de langage. Elles fournissent des informations sur le débit, la fiabilité et la réactivité du système, aidant ainsi les développeurs à maintenir des performances élevées et la satisfaction des utilisateurs.
Pourquoi s’intéresser aux métriques LLM ?
- Surveiller les performances en temps réel : Les métriques révèlent les inefficacités et les goulets d’étranglement.
- Passer à l’échelle sans accroc : Assurez-vous que votre modèle gère une demande accrue sans défaillance.
- Optimiser les coûts : Utilisez les métriques pour allouer efficacement les ressources et réduire les dépenses.
- Améliorer l’expérience utilisateur : Renforcez la fiabilité et la réactivité pour une meilleure satisfaction.
Les métriques clés à suivre pour le succès des LLM
Nous allons maintenant explorer les métriques essentielles pour surveiller et optimiser les LLM, accompagnées de conseils pratiques pour tirer parti de ces informations.
1. Requêtes par minute (RPM) : Mesurer le débit de votre système
Qu’est-ce que le nombre de requêtes par minute ?
Le nombre de requêtes par minute (RPM) suit le nombre de requêtes d’inférence traitées en une minute, fournissant une mesure précise du débit de votre système.
Formule :
RPM = Total des requêtes ÷ Temps (en minutes)
Exemple :
Si votre système traite 500 requêtes en une minute, le RPM est de 500.
Pourquoi c’est important :
- Un RPM élevé indique que votre système peut gérer plus de requêtes, favorisant une meilleure évolutivité.
- Utile pour identifier les périodes de pointe et planifier les mises à niveau d’infrastructure.
Conseils pratiques :
- Surveillez les tendances du RPM pour anticiper les pics d’utilisation.
- Passez à l’échelle horizontalement (ajouter plus de serveurs) ou verticalement (ajouter plus de puissance aux serveurs existants) pour maintenir les performances.
2. Taux de succès des requêtes (RSR) : Assurer la fiabilité
Qu’est-ce que le taux de succès des requêtes ?
Le taux de succès des requêtes (RSR) indique le pourcentage de requêtes qui renvoient des réponses valides, offrant un aperçu de la fiabilité du système.
Formule :
Taux de succès (%) = (Requêtes réussies ÷ Total des requêtes) × 100
Exemple :
Si 900 requêtes sur 1 000 réussissent, le taux de succès est de 90 %.
Pourquoi c’est important :
- Indique à quel point votre système est fiable.
- Un faible taux de succès peut révéler des limitations de ressources, des erreurs ou des problèmes réseau.
Conseils pratiques :
- Surveillez régulièrement les baisses du taux de succès et enquêtez.
- Optimisez les pipelines et résolvez les problèmes d’infrastructure pour améliorer la fiabilité.
3. Nombre moyen de tokens par requête (ATPR) : Comprendre la complexité
Qu’est-ce que le nombre moyen de tokens par requête ?
Le nombre moyen de tokens par requête (ATPR) suit le nombre moyen de tokens (entrée + sortie) que votre modèle traite par requête.
Formule :
ATPR = Total des tokens traités ÷ Total des requêtes
Exemple :
Si votre système traite 300 tokens pour 10 requêtes, l’ATPR est de 30.
Pourquoi c’est important :
- Reflète la complexité des requêtes.
- Un nombre de tokens plus élevé nécessite plus de ressources et augmente les coûts de traitement.
Conseils pratiques :
- Analysez la distribution des tokens pour optimiser les stratégies de regroupement.
- Gérez les requêtes lourdes en tokens pour éviter des coûts inutiles.
4. Latence de bout en bout (e2e_latency) : Suivre le temps de réponse total
Qu’est-ce que la latence de bout en bout ?
La latence de bout en bout mesure le temps total écoulé entre la réception d’une requête et la livraison complète de la réponse.
Formule :
e2e_latency = Heure de réponse complète − Heure de la requête
Exemple :
Si une requête est reçue à 0 ms et la réponse livrée à 200 ms, la e2e_latency est de 200 ms.
Pourquoi c’est important :
- Essentielle pour les applications en temps réel comme les chatbots ou assistants virtuels.
- Une e2e_latency élevée peut frustrer les utilisateurs et réduire la satisfaction.
Conseils pratiques :
- Décomposez la e2e_latency en composantes (temps d’inférence, délai réseau) pour identifier les problèmes.
- Utilisez la mise en cache et optimisez les pipelines d’inférence pour améliorer les temps de réponse.
5. Délai avant le premier token (TTFT) : Améliorer la réactivité initiale
Qu’est-ce que le délai avant le premier token ?
Le délai avant le premier token (TTFT) mesure la rapidité avec laquelle le modèle génère le premier token de sa réponse.
Formule :
TTFT = Heure de génération du premier token − Heure de la requête
Exemple :
Si le premier token est généré 150 ms après la requête, le TTFT est de 150 ms.
Pourquoi c’est important :
- Crucial pour les interactions utilisateur en temps réel.
- Un TTFT rapide améliore la perception de réactivité du système.
Conseils pratiques :
- Préchargez ou réchauffez les modèles pour réduire les délais.
- Surveillez le TTFT en même temps que la e2e_latency pour une vue complète de la réactivité.
6. Temps par token de sortie (TPOT) : Optimiser la génération de tokens
Qu’est-ce que le temps par token de sortie ?
Le temps par token de sortie (TPOT) mesure le temps moyen nécessaire pour générer chaque token après le premier.
Formule :
TPOT = Temps total pour générer les tokens après le premier ÷ Tokens générés après le premier
Exemple :
S’il faut 100 ms pour générer 10 tokens, le TPOT est de 10 ms par token.
Pourquoi c’est important :
- Reflète l’efficacité de la génération de tokens, en particulier pour les sorties textuelles longues.
- Un TPOT élevé peut ralentir les réponses pour des sorties volumineuses.
Conseils pratiques :
- Utilisez la parallélisation ou ajustez les modèles pour améliorer la vitesse de génération.
- Surveillez le TPOT avec d’autres métriques de latence pour optimiser l’expérience utilisateur.
Guide étape par étape : Comment observer les métriques LLM
1. Définir les métriques clés
Commencez par identifier les métriques les plus pertinentes pour votre application LLM. Prenez en compte l’expérience utilisateur, les performances système et l’évolutivité. Par exemple :
- Applications en temps réel : Priorisez des métriques comme la latence de bout en bout et le délai avant le premier token.
- Systèmes à fort volume : Concentrez-vous sur le débit (requêtes par minute) et la fiabilité (taux de succès des requêtes).
- Gestion des coûts : Surveillez l’utilisation des tokens (nombre moyen de tokens par requête et temps par token de sortie).
2. Tester les limites du système avec des tests de charge
- Simulez des scénarios de forte demande pour évaluer les performances sous pression.
- Identifiez les goulets d’étranglement et planifiez la mise à l’échelle si nécessaire.
3. Profiler les performances de votre modèle
- Décomposez la latence en composantes (temps d’inférence, délai réseau) pour identifier les inefficacités.
- Suivez les temps de génération des tokens pour analyser la vitesse de traitement et optimiser les workflows.
4. Définir des alertes pour les métriques clés
- Fixez des seuils pour les métriques critiques comme les requêtes par minute et la latence de bout en bout.
- Automatisez les notifications pour détecter et résoudre rapidement les problèmes de performance.
5. Itérer et optimiser
- Examinez en continu les données de performances pour identifier les tendances.
- Optimisez l’infrastructure, les pipelines et l’architecture du modèle pour améliorer les performances.
Surveillance en temps réel : Observer les métriques LLM sur Novita AI
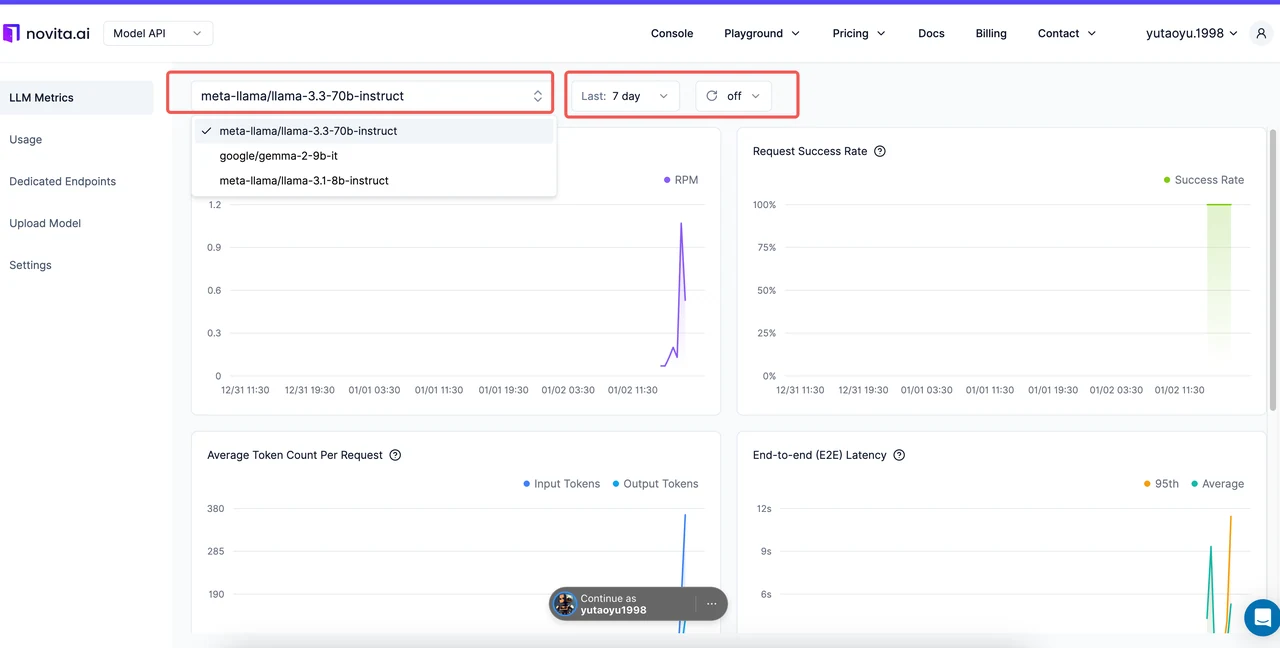
Novita AI simplifie le suivi des métriques avec sa Console de métriques dédiée, offrant des informations en temps réel sur vos déploiements LLM.
| Métrique | Ce qu’il faut surveiller sur Novita AI |
|---|---|
| Requêtes par minute | Suivez le débit pour que votre système gère efficacement les pics de trafic. |
| Taux de succès des requêtes | Observez les tendances pour identifier et résoudre les problèmes de fiabilité. |
| Nombre moyen de tokens par requête | Analysez l’utilisation des tokens pour gérer les coûts efficacement. |
| Latence de bout en bout | Surveillez la latence pour garantir une expérience utilisateur fluide. |
| Délai avant le premier token | Mesurez la réactivité initiale pour améliorer les applications en temps réel. Cette métrique n’est suivie que pour les requêtes en streaming avec le paramètre stream=true activé. |
| Temps par token de sortie | Optimisez la vitesse de génération des tokens pour les réponses longues. Cette métrique n’est suivie que pour les requêtes en streaming avec le paramètre stream=true activé. |
Explorez les métriques LLM plus en détail sur Novita AI.
Conseils pour utiliser la Console de métriques de Novita AI
- Testez votre modèle dans le LLM Playground pour observer les changements de métriques en temps réel.
- Utilisez les filtres pour analyser des métriques spécifiques pendant les heures de pointe et creuses.
- Ajustez l’allocation des ressources en fonction des tendances pour maintenir des performances élevées.
Réflexions finales : Pourquoi les métriques LLM sont essentielles
Les métriques LLM sont le pilier du succès des déploiements IA. En suivant des métriques telles que les requêtes par minute (RPM), le taux de succès des requêtes, la latence de bout en bout et le temps par token de sortie, vous pouvez obtenir des informations exploitables pour optimiser les performances, l’évolutivité et la fiabilité de votre système.
Des plateformes comme Novita AI facilitent la surveillance et l’action sur ces métriques en temps réel, garantissant que vos LLM fonctionnent toujours au meilleur de leurs capacités. Commencez dès aujourd’hui à tirer parti des métriques LLM pour proposer des solutions IA plus rapides, plus intelligentes et plus efficaces.
Foire aux questions
Que sont les métriques LLM ?
Les métriques LLM sont des mesures quantitatives qui évaluent la performance des grands modèles de langage (LLM), en se concentrant sur des aspects tels que le débit, la fiabilité et la réactivité.
Pourquoi les métriques LLM sont-elles importantes ?
Les métriques LLM sont cruciales pour la surveillance en temps réel afin d’identifier les inefficacités, d’assurer l’évolutivité en cas de demande, d’optimiser les coûts grâce à une allocation éclairée des ressources et d’améliorer l’expérience utilisateur en renforçant la fiabilité et la réactivité.
Comment surveiller efficacement les performances des LLM ?
Pour surveiller efficacement les performances des LLM, définissez des métriques pertinentes, effectuez des tests de charge, profilez les performances pour identifier les inefficacités, définissez des alertes pour des seuils critiques, et examinez et optimisez régulièrement en fonction des données de performance.
Comment mesurer la précision d’un LLM ?
La précision d’un LLM se mesure à l’aide de métriques telles que la précision, le rappel, le score F1 et le pourcentage de précision global, qui évaluent à quel point les sorties du modèle correspondent aux réponses attendues.
Comment valider la performance d’un LLM ?
La validation des performances d’un LLM implique un benchmark par rapport à des ensembles de données standardisés pour évaluer la précision, la fluidité, la cohérence et la pertinence, souvent à l’aide d’évaluations de vérité terrain avec des ensembles de données étiquetés.
Novita AI est la plateforme cloud tout-en-un qui alimente vos ambitions IA. API intégrées, serverless, instances GPU – les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.
Lecture recommandée



