

大型語言模型(LLM)正在改變科技,驅動著虛擬助手、聊天機器人與自動化內容。但你的模型是否發揮了最佳效能?
答案就在 LLM 指標中——這些是衡量效能、回應性、可擴展性與可觀測性的關鍵指標。在本指南中,我們將探討這些必要指標,並告訴你如何優化系統以達到最高效率,同時增強其可觀測性。
什麼是 LLM 指標?
AI 效能的基礎元件
LLM 指標是用來評估大型語言模型表現的量化測量方式。它們提供了對系統吞吐量、可靠性和回應性的洞察——幫助開發者維持高效能與使用者滿意度。
為什麼你應該關心 LLM 指標?
- 即時監控效能:指標能揭示效率低落與瓶頸所在。
- 無縫擴展:確保你的模型能夠處理增加的需求而不致崩潰。
- 最佳化成本:利用指標有效分配資源並減少開支。
- 提升使用者體驗:透過改善可靠性與回應性來提高滿意度。
追蹤 LLM 成功的關鍵指標
接下來,我們將探討監控與優化 LLM 的必要指標,以及如何將這些洞察化為可行建議。
1. 每分鐘請求數(RPM):衡量系統吞吐量
什麼是每分鐘請求數?
每分鐘請求數追蹤在一分鐘內處理的推論請求數量,讓你準確掌握系統的吞吐量。
公式:
RPM = 總請求數 ÷ 時間(分鐘)
範例:
若你的系統在一分鐘內處理 500 個請求,則 RPM 為 500。
為何重要:
- 高 RPM 表示你的系統能處理更多請求,支援更好的可擴展性。
- 有助於識別尖峰需求時段並規劃基礎設施升級。
專業建議:
- 監控 RPM 趨勢以預測使用量暴增。
- 橫向擴展(增加伺服器)或縱向擴展(增加現有伺服器效能)以維持效能。
2. 請求成功率(RSR):確保可靠性
什麼是請求成功率?
請求成功率顯示成功回傳有效回應的請求百分比,反映系統的可靠性。
公式:
請求成功率 (%) = (成功請求數 ÷ 總請求數) × 100
範例:
若 1000 個請求中有 900 個成功,則請求成功率為 90%。
為何重要:
- 表示系統的可靠程度。
- 低成功率可能指向資源限制、錯誤或網路問題。
專業建議:
- 定期監控並調查成功率的下降。
- 優化管線並解決基礎設施問題以提高可靠性。
3. 每請求平均 Tokens 數(ATPR):了解複雜度
什麼是每請求平均 Tokens 數?
每請求平均 Tokens 數追蹤你的模型在每個請求中處理的平均 tokens 數量(輸入 + 輸出)。
公式:
每請求平均 Tokens 數 = 處理的總 Tokens 數 ÷ 總請求數
範例:
若你的系統在 10 個請求中處理了 300 個 tokens,則每請求平均 Tokens 數為 30。
為何重要:
- 反映請求的複雜度。
- 較高的 token 數量需要更多資源並增加處理成本。
專業建議:
- 分析 token 分佈以最佳化批次處理策略。
- 管理 token 繁重的請求以避免不必要的成本。
4. 端對端延遲(e2e_latency):追蹤總回應時間
什麼是端對端延遲?
端對端延遲衡量從收到請求到傳送完整回應所花的總時間。
公式:
e2e_latency = 完整回應時間 − 請求時間
範例:
若請求在 0 毫秒收到,回應在 200 毫秒傳送,則 e2e_latency 為 200 毫秒。
為何重要:
- 對聊天機器人或虛擬助手等即時應用至關重要。
- 高 e2e_latency 可能讓使用者感到沮喪並降低滿意度。
專業建議:
- 將 e2e_latency 分解為組成部分(如推論時間、網路延遲)以找出問題。
- 使用快取並最佳化推論管線來改善回應時間。
5. 首個 Token 生成時間(TTFT):改善初始回應速度
什麼是首個 Token 生成時間?
首個 Token 生成時間衡量模型生成第一個回應 token 的速度。
公式:
TTFT = 第一個 Token 生成時間 − 請求時間
範例:
若請求後 150 毫秒生成第一個 token,則 TTFT 為 150 毫秒。
為何重要:
- 對即時使用者互動至關重要。
- 快速的 TTFT 能提升系統的感知回應性。
專業建議:
- 預載或預熱模型以減少延遲。
- 將 TTFT 與 e2e_latency 一同監控,以獲得回應性的完整畫面。
6. 每個輸出 Token 時間(TPOT):最佳化 Token 生成
什麼是每個輸出 Token 時間?
每個輸出 Token 時間衡量從第一個 token 之後,生成每個 token 所需的平均時間。
公式:
TPOT = 生成第一個之後 Token 的總時間 ÷ 第一個之後生成的 Token 數
範例:
若生成 10 個 token 需要 100 毫秒,則 TPOT 為每個 token 10 毫秒。
為何重要:
- 反映 token 生成效率,尤其是對於文字量大的輸出。
- 高 TPOT 可能導致大型輸出的回應變慢。
專業建議:
- 使用平行化或微調模型來提升 token 生成速度。
- 將 TPOT 與其他延遲指標一同監控,以最佳化使用者體驗。
逐步指南:如何觀測 LLM 指標
1. 定義關鍵指標
首先,針對你的 LLM 應用,找出最相關的指標。考慮使用者體驗、系統效能與可擴展性等因素。例如:
- 即時應用: 優先關注端對端延遲和首個 Token 生成時間等指標。
- 高吞吐量系統: 著重吞吐量(每分鐘請求數)與可靠性(請求成功率)。
- 成本管理: 監控 token 使用量(每請求平均 Tokens 數和每個輸出 Token 時間)。
2. 透過壓力測試系統極限
- 模擬高需求情境,評估系統在壓力下的表現。
- 找出瓶頸並根據需要規劃擴展。
3. 剖析模型的效能
- 將延遲分解為組成部分(如推論時間、網路延遲)以找出效率低落處。
- 追蹤 token 生成時間以分析處理速度並最佳化工作流程。
4. 為關鍵指標設定警示
- 為每分鐘請求數和端對端延遲等關鍵指標定義閾值。
- 自動化通知,以便快速偵測並解決效能問題。
5. 反覆迭代與最佳化
- 持續檢視效能數據,找出趨勢。
- 最佳化基礎設施、管線與模型架構,以提升效能。
即時監控:在 Novita AI 上觀測 LLM 指標
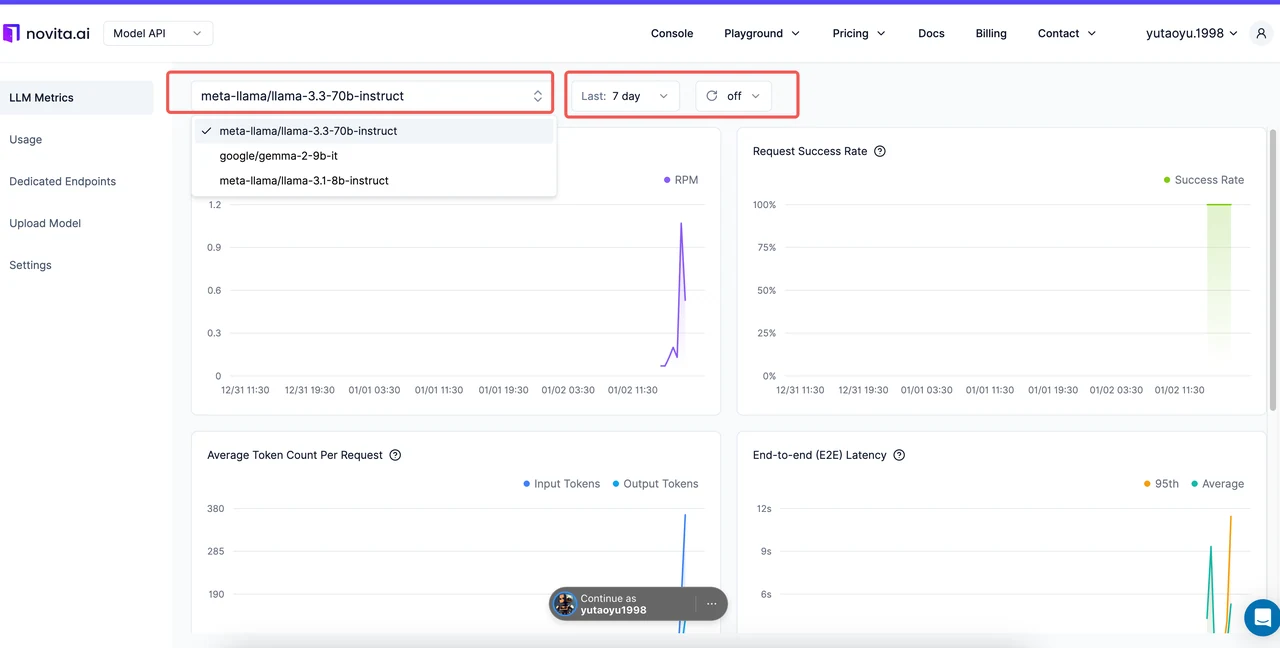
Novita AI 透過專屬的 Metrics Console 簡化指標追蹤,為你的 LLM 部署提供即時洞察。
| **指標 ** | ** 在 Novita AI 上監控什麼** |
|---|---|
| 每分鐘請求數 | 追蹤吞吐量,確保系統能有效處理流量高峰。 |
| 請求成功率 | 觀察趨勢,找出並排除可靠性問題。 |
| 每請求平均 Tokens 數 | 分析 token 使用量,有效管理成本。 |
| 端對端延遲 | 監控延遲,確保使用者體驗流暢。 |
| 首個 Token 生成時間 | 衡量初始回應性,改善即時應用。此指標僅在啟用 stream=true 參數的串流請求中追蹤。 |
| 每個輸出 Token 時間 | 針對較長回應最佳化 token 生成速度。此指標僅在啟用 stream=true 參數的串流請求中追蹤。 |
在 Novita AI 上進一步探索 LLM 指標的詳細資訊。
使用 Novita AI 指標控制台的建議
- 在 LLM Playground 中測試你的模型,即時觀察指標變化。
- 使用篩選器在尖峰與離峰時段分析特定指標。
- 根據趨勢調整資源分配,維持高效能。
結語:為何 LLM 指標至關重要
LLM 指標是成功 AI 部署的基石。透過追蹤每分鐘請求數(RPM)、請求成功率、端對端延遲與每個輸出 Token 時間等指標,你可以獲得可行的洞察,最佳化系統的效能、可擴展性與可靠性。
像 Novita AI 這樣的平台讓你能輕鬆即時監控並針對這些指標採取行動,確保你的 LLM 始終處於最佳狀態。立即開始善用 LLM 指標,提供更快、更智慧、更高效的 AI 解決方案。
常見問題
什麼是 LLM 指標?
LLM 指標是評估大型語言模型(LLM)表現的量化測量方式,重點在於吞吐量、可靠性和回應性等方面。
為何 LLM 指標很重要?
LLM 指標對於即時監控以找出效率低落點、確保在需求下擴展、透過明智的資源分配最佳化成本,以及提升使用者體驗(藉由改善可靠性與回應性)至關重要。
如何有效監控 LLM 效能?
要有效監控 LLM 效能,請定義相關指標、進行壓力測試、剖析效能以找出效率低落處、為關鍵閾值設定警示,並定期根據效能數據檢視與最佳化。
如何衡量 LLM 的準確度?
LLM 的準確度使用精確度、召回率、F1 分數和整體準確率百分比等指標來衡量,這些指標評估模型輸出與預期回應的接近程度。
如何驗證 LLM 效能?
驗證 LLM 效能涉及針對標準化資料集進行基準測試,評估準確性、流暢性、連貫性與相關性,通常使用帶標籤資料集的真實性評估。
Novita AI 是一個全能雲端平台,助你實現 AI 抱負。整合 API、無伺服器、GPU 實例——這些節省成本的工具你都需要。無需基礎設施,免費開始,讓你的 AI 願景成真。
推薦閱讀



