

Modelos de Linguagem de Grande Escala (LLMs) estão transformando a tecnologia, alimentando assistentes virtuais, chatbots e conteúdo automatizado. Mas seu modelo está com o melhor desempenho possível?
A resposta está nas métricas de LLM — indicadores-chave de desempenho, capacidade de resposta, escalabilidade e observabilidade. Neste guia, exploraremos as métricas essenciais e mostraremos como otimizar seu sistema para máxima eficiência, melhorando sua observabilidade.
O Que São Métricas de LLM?
Os Blocos de Construção do Desempenho de IA
Métricas de LLM são medidas quantitativas que avaliam o desempenho de Modelos de Linguagem de Grande Escala. Elas fornecem insights sobre taxa de transferência, confiabilidade e capacidade de resposta do sistema — ajudando desenvolvedores a manter alto desempenho e satisfação do usuário.
Por Que Você Deve se Importar com Métricas de LLM?
- Monitore o Desempenho em Tempo Real: Métricas revelam ineficiências e gargalos.
- Escale de Forma Integrada: Garanta que seu modelo lide com o aumento da demanda sem falhas.
- Otimize Custos: Use métricas para alocar recursos de forma eficaz e reduzir despesas.
- Melhore a Experiência do Usuário: Aumente a confiabilidade e a capacidade de resposta para melhor satisfação.
As Métricas-Chave para Acompanhar o Sucesso do LLM
Aqui, exploraremos as métricas essenciais para monitorar e otimizar LLMs, juntamente com dicas práticas para aproveitar esses insights.
1. Requisições por Minuto (RPM): Meça a Taxa de Transferência do Seu Sistema
O Que São Requisições por Minuto?
Requisições por Minuto rastreia o número de requisições de inferência processadas em um minuto, fornecendo uma medida precisa da taxa de transferência do seu sistema.
Fórmula:
RPM = Total de Requisições ÷ Tempo (em Minutos)
Exemplo:
Se seu sistema processa 500 requisições em um minuto, o RPM é 500.
Por Que É Importante:
- RPM alto indica que seu sistema pode lidar com mais requisições, suportando melhor escalabilidade.
- Útil para identificar períodos de pico de demanda e planejar atualizações de infraestrutura.
Dicas Profissionais:
- Monitore tendências de RPM para antecipar picos de uso.
- Escale horizontalmente (adicione mais servidores) ou verticalmente (adicione mais potência aos servidores existentes) para manter o desempenho.
2. Taxa de Sucesso de Requisições (RSR): Garanta Confiabilidade
O Que É Taxa de Sucesso de Requisições?
A Taxa de Sucesso de Requisições mostra a porcentagem de requisições que retornam respostas válidas, fornecendo insights sobre a confiabilidade do sistema.
Fórmula:
Taxa de Sucesso de Requisições (%) = (Requisições Bem-sucedidas ÷ Total de Requisições) × 100
Exemplo:
Se 900 de 1.000 requisições são bem-sucedidas, a Taxa de Sucesso de Requisições é 90%.
Por Que É Importante:
- Indica o quão confiável é seu sistema.
- Uma Taxa de Sucesso de Requisições baixa pode apontar limitações de recursos, erros ou problemas de rede.
Dicas Profissionais:
- Monitore regularmente e investigue quedas na Taxa de Sucesso de Requisições.
- Otimize pipelines e resolva problemas de infraestrutura para melhorar a confiabilidade.
3. Média de Tokens por Requisição (ATPR): Entenda a Complexidade
O Que É Média de Tokens por Requisição?
A Média de Tokens por Requisição rastreia o número médio de tokens (entrada + saída) que seu modelo processa por requisição.
Fórmula:
Média de Tokens por Requisição = Total de Tokens Processados ÷ Total de Requisições
Exemplo:
Se seu sistema processa 300 tokens em 10 requisições, a Média de Tokens por Requisição é 30.
Por Que É Importante:
- Reflete a complexidade das requisições.
- Contagens mais altas de tokens exigem mais recursos e aumentam os custos de processamento.
Dicas Profissionais:
- Analise a distribuição de tokens para otimizar estratégias de loteamento.
- Gerencie requisições com muitos tokens para evitar custos desnecessários.
4. Latência Ponto a Ponto (e2e_latency): Acompanhe o Tempo Total de Resposta
O Que É Latência Ponto a Ponto?
A Latência Ponto a Ponto mede o tempo total desde o recebimento de uma requisição até a entrega da resposta completa.
Fórmula:
e2e_latency = Tempo da Resposta Completa − Tempo da Requisição
Exemplo:
Se uma requisição é recebida em 0 ms e a resposta é entregue em 200 ms, a e2e_latency é 200 ms.
Por Que É Importante:
- Crítica para aplicações em tempo real, como chatbots ou assistentes virtuais.
- Alta e2e_latency pode frustrar usuários e reduzir a satisfação.
Dicas Profissionais:
- Divida a e2e_latency em componentes (por exemplo, tempo de inferência, atraso de rede) para identificar problemas.
- Use cache e otimize pipelines de inferência para melhorar os tempos de resposta.
5. Tempo para o Primeiro Token (TTFT): Melhore a Capacidade de Resposta Inicial
O Que É Tempo para o Primeiro Token?
O Tempo para o Primeiro Token mede a rapidez com que o modelo gera o primeiro token de sua resposta.
Fórmula:
TTFT = Tempo da Geração do Primeiro Token − Tempo da Requisição
Exemplo:
Se o primeiro token é gerado 150 ms após a requisição, o TTFT é 150 ms.
Por Que É Importante:
- Crucial para interações em tempo real com o usuário.
- Um TTFT rápido melhora a percepção de capacidade de resposta do sistema.
Dicas Profissionais:
- Pré-carregue ou aqueça modelos para reduzir atrasos.
- Monitore o TTFT junto com a e2e_latency para uma visão completa da capacidade de resposta.
6. Tempo por Token de Saída (TPOT): Otimize a Geração de Tokens
O Que É Tempo por Token de Saída?
O Tempo por Token de Saída mede o tempo médio para gerar cada token após o primeiro.
Fórmula:
TPOT = Tempo Total para Gerar Tokens Após o Primeiro Token ÷ Tokens Gerados Após o Primeiro Token
Exemplo:
Se leva 100 ms para gerar 10 tokens, o TPOT é 10 ms por token.
Por Que É Importante:
- Reflete a eficiência da geração de tokens, especialmente para saídas com muito texto.
- TPOT alto pode causar respostas mais lentas para saídas grandes.
Dicas Profissionais:
- Use paralelização ou ajuste fino de modelos para melhorar a velocidade de geração de tokens.
- Monitore o TPOT junto com outras métricas de latência para otimizar a experiência do usuário.
Guia Passo a Passo: Como Observar Métricas de LLM
1. Defina Métricas-Chave
Comece identificando as métricas mais relevantes para sua aplicação de LLM. Considere fatores como experiência do usuário, desempenho do sistema e escalabilidade. Por exemplo:
- Aplicações em Tempo Real: Priorize métricas como Latência Ponto a Ponto e Tempo para o Primeiro Token.
- Sistemas de Alto Volume: Foque na taxa de transferência (Requisições por Minuto) e confiabilidade (Taxa de Sucesso de Requisições).
- Gestão de Custos: Monitore o uso de tokens (Média de Tokens por Requisição e Tempo por Token de Saída).
2. Teste os Limites do Sistema com Testes de Estresse
- Simule cenários de alta demanda para avaliar o desempenho do sistema sob pressão.
- Identifique gargalos e planeje a escalabilidade conforme necessário.
3. Perfile o Desempenho do Seu Modelo
- Divida a latência em componentes (por exemplo, tempo de inferência, atraso de rede) para identificar ineficiências.
- Acompanhe os tempos de geração de tokens para analisar a velocidade de processamento e otimizar fluxos de trabalho.
4. Configure Alertas para Métricas-Chave
- Defina limites para métricas críticas como Requisições por Minuto e Latência Ponto a Ponto.
- Automatize notificações para detectar e resolver problemas de desempenho rapidamente.
5. Itere e Otimize
- Revise continuamente os dados de desempenho para identificar tendências.
- Otimize infraestrutura, pipelines e arquitetura do modelo para melhorar o desempenho.
Monitoramento em Tempo Real: Observando Métricas de LLM na Novita AI
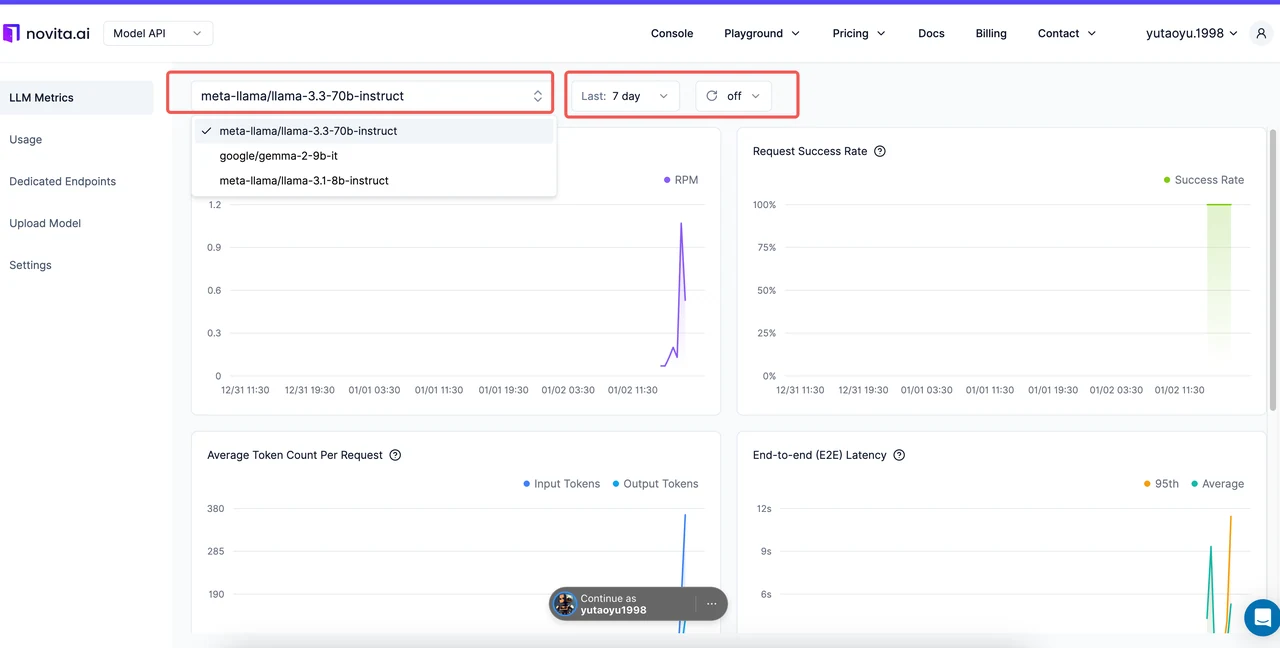
A Novita AI simplifica o rastreamento de métricas com seu Console de Métricas dedicado, fornecendo insights em tempo real sobre suas implantações de LLM.
| Métrica | O Que Monitorar na Novita AI |
|---|---|
| Requisições por Minuto | Acompanhe a taxa de transferência para garantir que seu sistema lide com picos de tráfego de forma eficiente. |
| Taxa de Sucesso de Requisições | Observe tendências para identificar e solucionar problemas de confiabilidade. |
| Média de Tokens por Requisição | Analise o uso de tokens para gerenciar custos de forma eficaz. |
| Latência Ponto a Ponto | Monitore a latência para garantir uma experiência de usuário fluida. |
| Tempo para o Primeiro Token | Meça a capacidade de resposta inicial para melhorar aplicações em tempo real. Essa métrica é rastreada apenas para requisições de streaming com o parâmetro stream=true ativado. |
| Tempo por Token de Saída | Otimize a velocidade de geração de tokens para respostas mais longas. Essa métrica é rastreada apenas para requisições de streaming com o parâmetro stream=true ativado. |
Explore as métricas de LLM em mais detalhes na Novita AI.
Dicas para Usar o Console de Métricas da Novita AI
- Teste seu modelo no LLM Playground para observar as mudanças nas métricas em tempo real.
- Use filtros para analisar métricas específicas durante horários de pico e fora de pico.
- Ajuste a alocação de recursos com base nas tendências para manter o alto desempenho.
Considerações Finais: Por Que as Métricas de LLM São Vitais
As métricas de LLM são a espinha dorsal de implantações bem-sucedidas de IA. Ao rastrear métricas como Requisições por Minuto (RPM), Taxa de Sucesso de Requisições, Latência Ponto a Ponto e Tempo por Token de Saída, você pode obter insights acionáveis para otimizar o desempenho, a escalabilidade e a confiabilidade do seu sistema.
Plataformas como a Novita AI facilitam o monitoramento e a ação sobre essas métricas em tempo real, garantindo que seus LLMs estejam sempre operando em seu melhor. Comece a aproveitar as métricas de LLM hoje para oferecer soluções de IA mais rápidas, inteligentes e eficientes.
Perguntas Frequentes
O que são métricas de LLM?
Métricas de LLM são medidas quantitativas que avaliam o desempenho de Modelos de Linguagem de Grande Escala (LLMs), focando em aspectos como taxa de transferência, confiabilidade e capacidade de resposta.
Por que as métricas de LLM são importantes?
As métricas de LLM são cruciais para monitoramento em tempo real para identificar ineficiências, garantir escalabilidade sob demanda, otimizar custos por meio de alocação informada de recursos e melhorar a experiência do usuário aumentando a confiabilidade e a capacidade de resposta.
Como posso monitorar o desempenho do LLM de forma eficaz?
Para monitorar o desempenho do LLM de forma eficaz, defina métricas relevantes, realize testes de estresse, perfile o desempenho para identificar ineficiências, configure alertas para limites críticos e revise e otimize regularmente com base nos dados de desempenho.
Como medir a precisão de um LLM?
A precisão de um LLM é medida usando métricas como precisão, recall, pontuação F1 e porcentagem de precisão geral, que avaliam o quão próximas as saídas do modelo correspondem às respostas esperadas.
Como validar o desempenho do LLM?
Validar o desempenho do LLM envolve benchmarking contra conjuntos de dados padronizados para avaliar precisão, fluência, coerência e relevância, geralmente usando avaliações de verdade fundamental com conjuntos de dados rotulados.
Novita AI é a plataforma tudo-em-um na nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, Instância GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.
Leitura Recomendada



