

النماذج اللغوية الكبيرة (LLMs) تغير التكنولوجيا، حيث تزود المساعدات الافتراضية وروبوتات الدردشة والمحتوى الآلي بالقوة. لكن هل يعمل نموذجك بأفضل أداء؟
الإجابة تكمن في مقاييس LLM—المؤشرات الرئيسية للأداء والاستجابة وقابلية التوسع والمراقبة. في هذا الدليل، سنستكشف المقاييس الأساسية ونوضح لك كيفية تحسين نظامك لتحقيق أقصى كفاءة مع تعزيز مراقبته.
ما هي مقاييس LLM؟
اللبنات الأساسية لأداء الذكاء الاصطناعي
مقاييس LLM هي مقاييس كمية تقيم أداء النماذج اللغوية الكبيرة. توفر رؤى حول إنتاجية النظام وموثوقيته واستجابته—مما يساعد المطورين في الحفاظ على أداء عالٍ ورضا المستخدمين.
لماذا يجب أن تهتم بمقاييس LLM؟
- مراقبة الأداء في الوقت الفعلي: تكشف المقاييس عن عدم الكفاءة والاختناقات.
- التوسع بسلاسة: تأكد من أن نموذجك يتحمل الطلب المتزايد دون تعطل.
- تحسين التكاليف: استخدم المقاييس لتخصيص الموارد بفعالية وتقليل النفقات.
- تحسين تجربة المستخدم: عزز الموثوقية والاستجابة لتحقيق رضا أفضل.
المقاييس الرئيسية التي يجب تتبعها لنجاح LLM
هنا، سنستكشف المقاييس الأساسية لمراقبة وتحسين LLM، إلى جانب نصائح قابلة للتنفيذ للاستفادة من هذه الرؤى.
1. عدد الطلبات في الدقيقة (RPM): قياس إنتاجية نظامك
ما هو عدد الطلبات في الدقيقة؟
يتتبع عدد الطلبات في الدقيقة عدد طلبات الاستدلال التي تتم معالجتها في دقيقة واحدة، مما يمنحك مقياسًا دقيقًا لإنتاجية نظامك.
الصيغة:
RPM = إجمالي الطلبات ÷ الوقت (بالدقائق)
مثال:
إذا قام نظامك بمعالجة 500 طلب في دقيقة واحدة، فإن RPM يساوي 500.
لماذا هو مهم؟
- يشير ارتفاع RPM إلى أن نظامك يمكنه التعامل مع المزيد من الطلبات، مما يدعم قابلية توسع أفضل.
- مفيد لتحديد فترات ذروة الطلب والتخطيط لترقية البنية التحتية.
نصائح احترافية:
- راقب اتجاهات RPM لتوقع ارتفاعات الاستخدام.
- قم بالتوسع أفقيًا (إضافة خوادم أكثر) أو رأسيًا (إضافة طاقة أكبر للخوادم الحالية) للحفاظ على الأداء.
2. معدل نجاح الطلبات (RSR): ضمان الموثوقية
ما هو معدل نجاح الطلبات؟
يظهر معدل نجاح الطلبات النسبة المئوية للطلبات التي تعيد استجابات صالحة، مما يعطي نظرة ثاقبة على موثوقية النظام.
الصيغة:
معدل نجاح الطلبات (%) = (الطلبات الناجحة ÷ إجمالي الطلبات) × 100
مثال:
إذا نجحت 900 من 1000 طلب، فإن معدل نجاح الطلبات هو 90%.
لماذا هو مهم؟
- يشير إلى مدى اعتمادية نظامك.
- قد يشير انخفاض معدل نجاح الطلبات إلى قيود في الموارد أو أخطاء أو مشكلات في الشبكة.
نصائح احترافية:
- راقب بانتظام وحقق في الانخفاضات في معدل نجاح الطلبات.
- قم بتحسين خطوط الأنابيب ومعالجة مشكلات البنية التحتية لتحسين الموثوقية.
3. متوسط الرموز لكل طلب (ATPR): فهم التعقيد
ما هو متوسط الرموز لكل طلب؟
يتتبع متوسط الرموز لكل طلب متوسط عدد الرموز (المدخلات + المخرجات) التي يعالجها نموذجك لكل طلب.
الصيغة:
متوسط الرموز لكل طلب = إجمالي الرموز المعالجة ÷ إجمالي الطلبات
مثال:
إذا قام نظامك بمعالجة 300 رمز عبر 10 طلبات، فإن متوسط الرموز لكل طلب هو 30.
لماذا هو مهم؟
- يعكس تعقيد الطلبات.
- تتطلب أعداد الرموز الأعلى موارد أكثر وتزيد من تكاليف المعالجة.
نصائح احترافية:
- حلل توزيع الرموز لتحسين استراتيجيات التجميع.
- إدارة الطلبات ذات الرموز الثقيلة لتجنب التكاليف غير الضرورية.
4. زمن الاستجابة من البداية إلى النهاية (e2e_latency): تتبع وقت الاستجابة الإجمالي
ما هو زمن الاستجابة من البداية إلى النهاية؟
يقيس زمن الاستجابة من البداية إلى النهاية إجمالي الوقت المستغرق من استلام الطلب إلى تسليم الرد الكامل.
الصيغة:
e2e_latency = وقت الرد الكامل − وقت الطلب
مثال:
إذا تم استلام طلب عند 0 مللي ثانية وتم تسليم الرد عند 200 مللي ثانية، فإن e2e_latency هو 200 مللي ثانية.
لماذا هو مهم؟
- بالغ الأهمية للتطبيقات في الوقت الفعلي مثل روبوتات الدردشة أو المساعدات الافتراضية.
- ارتفاع e2e_latency يمكن أن يحبط المستخدمين ويقلل من الرضا.
نصائح احترافية:
- قسم e2e_latency إلى مكونات (مثل وقت الاستدلال، تأخير الشبكة) لتحديد المشكلات.
- استخدم التخزين المؤقت وقم بتحسين خطوط أنابيب الاستدلال لتحسين أوقات الاستجابة.
5. الوقت حتى أول رمز (TTFT): تحسين الاستجابة الأولية
ما هو الوقت حتى أول رمز؟
يقيس الوقت حتى أول رمز سرعة توليد النموذج لأول رمز في رده.
الصيغة:
TTFT = وقت توليد أول رمز − وقت الطلب
مثال:
إذا تم توليد أول رمز بعد 150 مللي ثانية من الطلب، فإن TTFT هو 150 مللي ثانية.
لماذا هو مهم؟
- بالغ الأهمية للتفاعلات في الوقت الفعلي مع المستخدمين.
- TTFT السريع يحسن الاستجابة المدركة للنظام.
نصائح احترافية:
- قم بتحميل النماذج مسبقًا أو تسخينها لتقليل التأخير.
- راقب TTFT جنبًا إلى جنب مع e2e_latency للحصول على رؤية كاملة للاستجابة.
6. الوقت لكل رمز مخرج (TPOT): تحسين توليد الرموز
ما هو الوقت لكل رمز مخرج؟
يقيس الوقت لكل رمز مخرج متوسط الوقت المستغرق لتوليد كل رمز بعد الرمز الأول.
الصيغة:
TPOT = إجمالي الوقت لتوليد الرموز بعد الرمز الأول ÷ الرموز المولدة بعد الرمز الأول
مثال:
إذا استغرق الأمر 100 مللي ثانية لتوليد 10 رموز، فإن TPOT هو 10 مللي ثانية لكل رمز.
لماذا هو مهم؟
- يعكس كفاءة توليد الرموز، خاصة للمخرجات الطويلة النصية.
- ارتفاع TPOT يمكن أن يسبب استجابات أبطأ للمخرجات الكبيرة.
نصائح احترافية:
- استخدم التوازي أو قم بضبط النماذج الدقيقة لتحسين سرعة توليد الرموز.
- راقب TPOT إلى جانب مقاييس زمن الاستجابة الأخرى لتحسين تجربة المستخدم.
دليل خطوة بخطوة: كيفية مراقبة مقاييس LLM
1. تحديد المقاييس الرئيسية
ابدأ بتحديد المقاييس الأكثر صلة بتطبيق LLM الخاص بك. ضع في اعتبارك عوامل مثل تجربة المستخدم وأداء النظام وقابلية التوسع. على سبيل المثال:
- التطبيقات في الوقت الفعلي: أعط الأولوية لمقاييس مثل زمن الاستجابة من البداية إلى النهاية والوقت حتى أول رمز.
- الأنظمة عالية الحجم: ركز على الإنتاجية (عدد الطلبات في الدقيقة) والموثوقية (معدل نجاح الطلبات).
- إدارة التكاليف: راقب استخدام الرموز (متوسط الرموز لكل طلب والوقت لكل رمز مخرج).
2. اختبار حدود النظام باختبارات الإجهاد
- محاكاة سيناريوهات الطلب العالي لتقييم أداء النظام تحت الضغط.
- تحديد الاختناقات والتخطيط للتوسع حسب الحاجة.
3. تحليل أداء نموذجك
- قسم زمن الاستجابة إلى مكونات (مثل وقت الاستدلال، تأخير الشبكة) لتحديد عدم الكفاءة.
- تتبع أوقات توليد الرموز لتحليل سرعة المعالجة وتحسين سير العمل.
4. ضبط التنبيهات للمقاييس الرئيسية
- حدد عتبات للمقاييس الحرجة مثل عدد الطلبات في الدقيقة وزمن الاستجابة من البداية إلى النهاية.
- أتمتة الإشعارات لاكتشاف وحل مشكلات الأداء بسرعة.
5. التكرار والتحسين
- راجع بيانات الأداء باستمرار لتحديد الاتجاهات.
- قم بتحسين البنية التحتية وخطوط الأنابيب وهندسة النموذج لتحسين الأداء.
المراقبة في الوقت الفعلي: مشاهدة مقاييس LLM على Novita AI
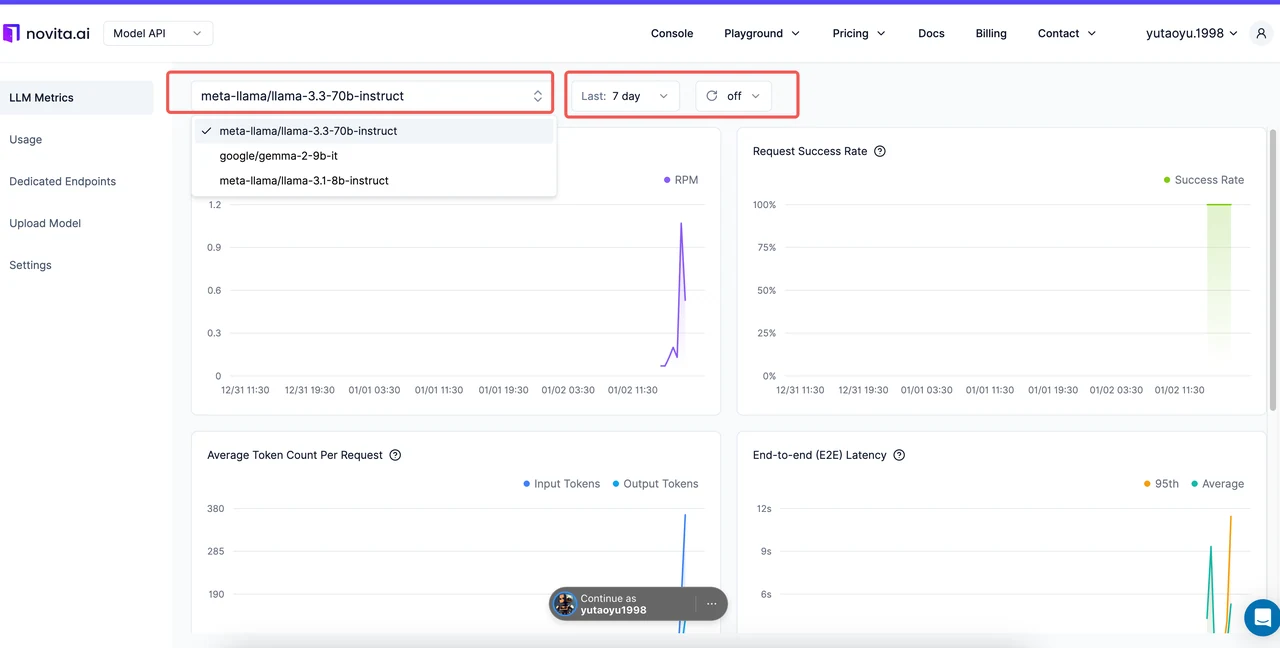
تبسط Novita AI تتبع المقاييس من خلال لوحة المقاييس المخصصة لها، مما يوفر رؤى في الوقت الفعلي لنشر LLM الخاص بك.
| المقياس | ما يجب مراقبته على Novita AI |
|---|---|
| عدد الطلبات في الدقيقة | تتبع الإنتاجية لضمان معالجة نظامك لارتفاعات حركة المرور بكفاءة. |
| معدل نجاح الطلبات | راقب الاتجاهات لتحديد وحل مشكلات الموثوقية. |
| متوسط الرموز لكل طلب | حلل استخدام الرموز لإدارة التكاليف بفعالية. |
| زمن الاستجابة من البداية إلى النهاية | راقب زمن الاستجابة لضمان تجربة مستخدم سلسة. |
| الوقت حتى أول رمز | قم بقياس الاستجابة الأولية لتحسين التطبيقات في الوقت الفعلي. يتم تتبع هذا المقياس فقط للطلبات المتدفقة مع تمكين المعامل stream=true. |
| الوقت لكل رمز مخرج | قم بتحسين سرعة توليد الرموز للاستجابات الأطول. يتم تتبع هذا المقياس فقط للطلبات المتدفقة مع تمكين المعامل stream=true. |
استكشف مقاييس LLM بمزيد من التفاصيل على Novia AI.
نصائح لاستخدام لوحة مقاييس Novita AI
- اختبر نموذجك في ملعب LLM لمراقبة تغيرات المقاييس في الوقت الفعلي.
- استخدم المرشحات لتحليل مقاييس محددة خلال ساعات الذروة وخارجها.
- اضبط تخصيص الموارد بناءً على الاتجاهات للحفاظ على أداء عالٍ.
أفكار ختامية: لماذا تعتبر مقاييس LLM حيوية
مقاييس LLM هي العمود الفقري لنشر الذكاء الاصطناعي بنجاح. من خلال تتبع مقاييس مثل عدد الطلبات في الدقيقة (RPM)، ومعدل نجاح الطلبات، وزمن الاستجابة من البداية إلى النهاية، والوقت لكل رمز مخرج، يمكنك فتح رؤى قابلة للتنفيذ لتحسين أداء نظامك وقابلية التوسع والموثوقية.
منصات مثل Novita AI تجعل من السهل مراقبة هذه المقاييس والتصرف بناءً عليها في الوقت الفعلي، مما يضمن أن نماذج LLM الخاصة بك تعمل دائمًا في أفضل حالاتها. ابدأ في الاستفادة من مقاييس LLM اليوم لتقديم حلول ذكاء اصطناعي أسرع وأذكى وأكثر كفاءة.
الأسئلة الشائعة
ما هي مقاييس LLM؟
مقاييس LLM هي مقاييس كمية تقيم أداء النماذج اللغوية الكبيرة (LLMs)، مع التركيز على جوانب مثل الإنتاجية والموثوقية والاستجابة.
لماذا تعتبر مقاييس LLM مهمة؟
مقاييس LLM ضرورية للمراقبة في الوقت الفعلي لتحديد عدم الكفاءة، وضمان قابلية التوسع تحت الطلب، وتحسين التكاليف من خلال تخصيص الموارد المستنير، وتعزيز تجربة المستخدم من خلال تحسين الموثوقية والاستجابة.
كيف يمكنني مراقبة أداء LLM بفعالية؟
لمراقبة أداء LLM بفعالية، حدد المقاييس ذات الصلة، وقم بإجراء اختبارات الإجهاد، وحلل الأداء لتحديد عدم الكفاءة، واضبط التنبيهات للعتبات الحرجة، وراجع بانتظام وحسن بناءً على بيانات الأداء.
كيف تقيس دقة LLM؟
تقاس دقة LLM باستخدام مقاييس مثل الدقة (precision) والاستدعاء (recall) ودرجة F1 ونسبة الدقة الإجمالية، والتي تقيم مدى قرب مخرجات النموذج من الاستجابات المتوقعة.
كيف تتحقق من صحة أداء LLM؟
يتضمن التحقق من صحة أداء LLM المقارنة المعيارية مقابل مجموعات البيانات الموحدة لتقييم الدقة والطلاقة والتماسك والملاءمة، وغالبًا باستخدام تقييمات الحقيقة الأساسية مع مجموعات البيانات المصنفة.
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيل GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.
قراءة موصى بها



