

Qwen3-VL-8B-Instruct ist jetzt auf Novita AI verfügbar und bietet die bisher fortschrittlichsten Vision-Language-Funktionen der Qwen-Reihe. Dieses neue Release bringt deutliche Verbesserungen in allen Bereichen – von genauerer Textverständnis und -generation über umfangreichere visuelle Schlussfolgerung, erweiterte Kontextverarbeitung, bessere räumliche und Video-Verständnis bis hin zu leistungsfähigeren Interaktionen auf Agent-Ebene. Es ist sowohl in Dense- als auch MoE-Varianten erhältlich, die von Edge-Geräten bis zu Cloud-Umgebungen skalierbar sind, sowie in Instruct- und auf Schlussfolgerung fokussierten Thinking-Editionen für anpassbare, bedarfsgerechte Bereitstellung.
Es übertrifft gängige Alternativen, hält mit führenden VLMs mit und bietet eine schnelle Inferenzleistung, die für den Einsatz in der Praxis geeignet ist.
Testen Sie die Qwen3-VL-8B-Instruct Demo
Was ist Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct ist ein hochmodernes Vision-Language-Modell, das entwickelt wurde, um Bilder und Text ganzheitlich zu verstehen. Es basiert auf der neuesten Qwen3-Architektur, bietet starke multimodale Schlussfolgerungsfähigkeiten, präzise visuelle Verankerung und natürliche Sprachgenerierung in einem leichten 8B-Parameter-Formfaktor. Im Vergleich zu früheren Iterationen wurde die Instruct-Variante für den Einsatz in der Praxis optimiert – sie unterstützt genauere Befolgung von Anweisungen, verbessertes Kontextverständnis und schnellere Inferenz in unterschiedlichen Bereitstellungsumgebungen. Diese Upgrades machen es ideal für Anwendungen von Bildverständnis und Dokumentenanalyse bis hin zu multimodalen Agenten und interaktiven KI-Systemen.
Wichtige Verbesserungen
- Visuelle Agent-Funktionen: Interagiert mit PC- und mobilen Benutzeroberflächen – identifiziert UI-Komponenten, interpretiert deren Funktionen, löst Tools aus und führt Aufgaben Ende-zu-Ende aus.
- Beschleunigung von visuell zu Code: Konvertiert Bilder oder Videoframes in Draw.io-Diagramme, HTML, CSS oder JavaScript.
- Überlegene räumliche Intelligenz: Bewertet Objektbeziehungen, Blickwinkel und Verdeckungen; bietet stärkere 2D-Verankerung und unterstützt 3D-Verständnis für räumliche Schlussfolgerung und verkörperte KI.
- Erweiterter Kontext & Video-Verständnis: Nativ 256K Kontext, erweiterbar auf 1M, ermöglicht die Verarbeitung vollständiger Dokumente und mehrstündiger Videoanalysen mit präziser zeitlicher Navigation.
- Fortschrittliche multimodale Schlussfolgerung: Besonders stark in MINT und Mathematik – unterstützt kausale Interpretation und logisch fundierte, evidenzbasierte Antworten.
- Verbesserte visuelle Erkennung: Erweiterte, hochwertigere Trainingsdaten ermöglichen eine breite Erkennung – von Prominenten und Anime über Konsumgüter bis hin zu Wahrzeichen, Pflanzen und Tieren.
- Leistungsfähigere OCR: Unterstützt jetzt 32 Sprachen (vorher 19); funktioniert gut bei Unschärfe, schwachem Licht oder geneigtem Text; verarbeitet seltene/antike Schriften, Fachbegriffe und die Struktur langer Dokumente besser.
- Textverständnis vergleichbar mit reinen LLMs: Ermöglicht die nahtlose Integration von Text und Vision für ein vollständig einheitliches Verständnis ohne Informationsverlust.
Modellarchitektur
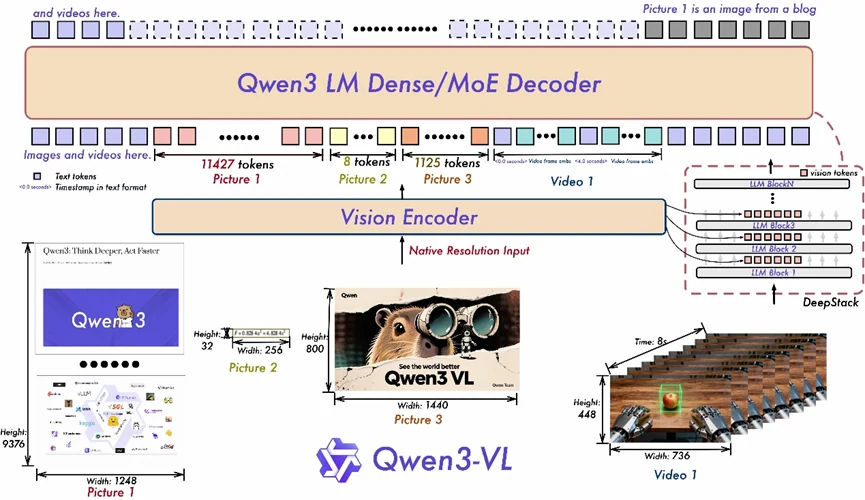
- Interleaved-MRoPE: Nutzt eine umfassende Positionscodierung über zeitliche und räumliche Dimensionen (Zeit, Breite, Höhe), was die Schlussfolgerung über lange Videoentfernungen verbessert.
- DeepStack: Integriert mehrschichtige ViT-Darstellungen, um feine Details zu bewahren und die Ausrichtung zwischen visuellem Inhalt und Text zu stärken.
- Text-Zeitstempel-Ausrichtung: Geht über T-RoPE hinaus, indem Ereignisse auf genaue Zeitstempel verankert werden, was das zeitliche Verständnis in Videos deutlich verbessert.
Qwen3-VL-8B-Instruct: Modellleistung
Multimodale Leistung
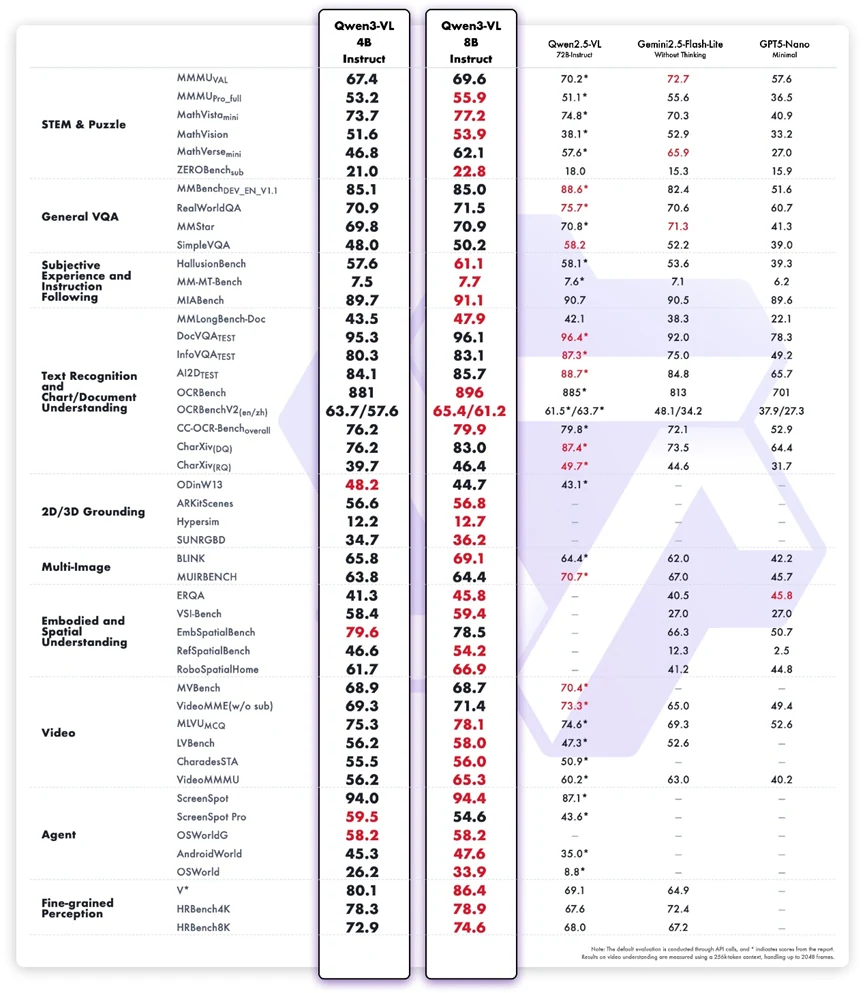
Die Benchmark-Ergebnisse zeigen, dass Qwen3-VL-8B-Instruct eine ausgewogene multimodale Leistung bietet, insbesondere angesichts seiner kompakten Größe. Es zeigt bemerkenswerte Stärken in MINT-Schlussfolgerung, visuellem Dokumentenverständnis und der Befolgung multimodaler Anweisungen, übertrifft sein 4B-Pendant deutlich und erreicht wettbewerbsfähige Werte im Vergleich zu größeren oder proprietären Systemen. Aufgaben wie MathVista, InfoVQA-Test, A12Dataset, RobospatialHome und ScreenSpot unterstreichen seine Fähigkeit, textuelle und visuelle Schlussfolgerung für praktische Workflows zu kombinieren. Seine starken Ergebnisse in agentenbezogenen Benchmarks spiegeln zudem eine solide Verankerung von Wahrnehmung zu Aktion wider.
Reine Textleistung
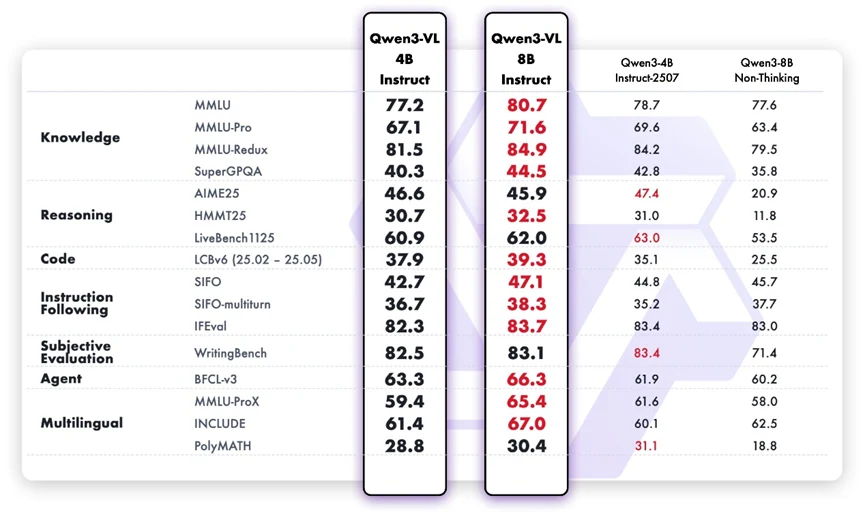
Obwohl es als multimodales Modell entwickelt wurde, zeigt Qwen3-VL-8B-Instruct starke sprachliche Fähigkeiten bei reinen Textaufgaben. Im Vergleich zur 4B-Version gibt es deutliche Verbesserungen bei Faktenwissen, logischer Schlussfolgerung, Programmierfähigkeit und der Bearbeitung von Aufgaben mit mehreren Turns. Es befolgt die Benutzerabsicht genauer, bleibt in längeren Gesprächen kohärent und zeigt zuverlässigeres Urteilsvermögen bei subjektiven Aufgaben wie der Ausrichtung an Präferenzen. Seine mehrsprachigen Verbesserungen bedeuten zudem eine bessere Inklusivität für globale Anwendungsszenarien.
Qwen3-VL-8B-Instruct: Anwendungsfälle
Unternehmens-Wissens-Copilot
Unterstützt Mitarbeiter bei der Abfrage von Richtlinien, Produktspezifikationen und Betriebsverfahren aus großen Dokumentenarchiven. Extrahiert automatisch Kernpunkte und erstellt Zusammenfassungen, um die Entscheidungsfindung in Compliance-, Finanz- und Technikabteilungen zu unterstützen.
Automatisierte App-Bedienung & UI-Navigation
Nutzt visuelles Verständnis, um mit PC- oder mobilen Benutzeroberflächen zu interagieren – Apps zu öffnen, Formulare einzureichen oder durch Menüs zu navigieren. Ideal zum Ersetzen oder Erweitern von traditioneller RPA in sich wiederholenden Büro- oder Betriebsabläufen.
Video-Überprüfung & Ereignisextraktion
Analysiert lange Aufnahmen wie Meetings, Unterrichtsstunden und Überwachungsstreams. Erkennt Schlüsselmomente, markiert Segmente und bietet eine zeitbasierte Suche für effiziente Inhaltsprüfung.
Geschäftsdokumentenverarbeitung
Digitalisiert und strukturiert Rechnungen, Belege, Verträge und Logistikdokumente, die unter realen Bedingungen erfasst wurden. Extrahiert wesentliche Felder unter Berücksichtigung des Layouts, um Finanzprüfungen und Onboarding-Workflows zu optimieren.
Kundensupport mit visueller Unterstützung
Versteht Screenshots und Gerätefotos von Benutzern, um Login-Probleme, Konfigurationsfehler oder Produktabweichungen zu diagnostizieren. Bietet Schritt-für-Schritt-Anleitungen, um die Ferndiagnose und Serviceeffizienz zu verbessern.
Räumliche KI für Robotik & AR-Geräte
Interpretiert 2D- und 3D-Umgebungen für Navigation und Objektinteraktion. Anwendbar auf Lagerroboter, Heimservice-Agenten und Augmented-Reality-Navigation in komplexen Räumen.
Design-to-Code-Produktivität
Konvertiert UI-Screenshots oder Skizzen in Frontend-Code-Prototypen. Beschleunigt die Übergabe zwischen Design- und Entwicklungsteams in der digitalen Produktentwicklung.
Wie greifen Sie auf Qwen3-VL-8B-Instruct zu?
Qwen3-VL-8B-Instruct ist jetzt auf Novita AI zum Preis von 0,08 $ pro 1M Eingabetoken und 0,50 $ pro 1M Ausgabetoken verfügbar.
Nutzen Sie den Playground (ohne Programmierung)
Registrieren Sie sich und beginnen Sie innerhalb von Sekunden mit der Experimentierung mit Qwen3-VL-8B-Instruct über eine interaktive Oberfläche. Testen Sie Prompts, sehen Sie Ausgaben in Echtzeit mit dem vollen 200K-Kontextfenster und vergleichen Sie GLM-4.6 mit anderen führenden Modellen. Perfekt für Prototyping und um zu verstehen, was das Modell leisten kann, bevor Sie vollständige Implementierungen erstellen.
Integration über API (für Entwickler)
Verbinden Sie Qwen3-VL-8B-Instruct mit Ihren Anwendungen über die einheitliche REST-API von Novita AI.
Option 1: Direkte API-Integration (Python-Beispiel)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2: Multi-Agent-Workflows mit OpenAI Agents SDK
Erstellen Sie anspruchsvolle Multi-Agent-Systeme, die die fortschrittlichen Dokumentenanalysefähigkeiten von Qwen3-VL-8B-Instruct nutzen:
- Plug-and-Play-Integration: Nutzen Sie Qwen3-VL-8B-Instruct in jedem OpenAI Agents-Workflow
- Erweiterte Agent-Funktionen: Unterstützung für Übergaben, Routing und Tool-Integration mit Dokumentenverständnis
- Skalierbare Architektur: Entwerfen Sie Agenten, die die mehrsprachige OCR- und Elementerkennungsfähigkeiten von Qwen3-VL-8B-Instruct nutzen
Option 3: Verbindung mit Plattformen von Drittanbietern
Entwicklungstools: Integrieren Sie sich nahtlos in beliebte IDEs und Entwicklungsumgebungen wie Cursor, Trae und Cline über OpenAI-kompatible APIs und Anthropic-kompatible APIs.
Orchestrierungsframeworks: Verbinden Sie sich mit LangChain, Dify, CrewAI, Langflow und anderen KI-Orchestrierungsplattformen über offizielle Connectors.
Hugging Face Integration: Novita AI ist offizieller Inferenzanbieter von Hugging Face und gewährleistet eine breite Ökosystemkompatibilität.
Was ist Qwen3-VL-8B? Qwen3-VL-8B ist ein kompaktes multimodales Modell, das sowohl Text- als auch visuelle Informationen versteht und verarbeitet und Analyse, Schlussfolgerung und agentengesteuerte Aufgabenausführung unterstützt.
Wie verarbeitet Qwen3-VL-8B multimodale Eingaben? Es kann Bilder, Screenshots, Videos und Dokumente verarbeiten und diese mit Textanweisungen kombinieren, um kohärente und umsetzbare Ausgaben zu erzeugen.
Was unterscheidet Qwen3-VL-8B von Standard-LLMs? Es versteht nicht nur Informationen, sondern kann auch mit Benutzeroberflächen und realen visuellen Inhalten interagieren, was es für intelligente Automatisierung und verkörperte KI geeignet macht.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanzen – die kostengünstigen Tools, die Sie brauchen. Eliminieren Sie Infrastrukturaufwand, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



