

Qwen3-VL-8B-Instruct is now on Novita AI, offering the most advanced vision-language capabilities yet in the Qwen lineup. This new release brings major improvements in every dimension—from more accurate text comprehension and generation to richer visual reasoning, expanded context handling, better spatial and video understanding, and more capable agent-level interactions. Offered in both Dense and MoE variants that can scale from edge devices to cloud environments, along with Instruct and reasoning-focused Thinking editions for adaptable, on-demand deployment.
It surpasses mainstream alternatives, holds its own against leading VLMs, and maintains rapid inference performance suited for real-world applications.
What is Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct is a cutting-edge vision-language model designed to understand images and text holistically. Built on the latest Qwen3 architecture, it delivers strong multimodal reasoning, precise visual grounding, and natural language generation in a lightweight 8B-parameter form factor. Compared with previous iterations, the Instruct variant has been optimized for real-world usability—supporting more accurate instruction following, improved contextual understanding, and faster inference across diverse deployment environments. These upgrades make it well-suited for applications ranging from image understanding and document parsing to multimodal agents and interactive AI systems.
Key Enhancement
- Visual Agent Capabilities: Interacts with PC and mobile interfaces—identifies UI components, interprets their functions, triggers tools, and executes tasks end-to-end.
- Visual-to-Code Acceleration: Converts images or video frames into Draw.io diagrams, HTML, CSS, or JavaScript.
- Superior Spatial Intelligence: Evaluates object relations, viewpoints, and occlusions; delivers stronger 2D grounding and supports 3D understanding for spatial reasoning and embodied AI.
- Extended Context & Video Comprehension: Native 256K context expandable to 1M, enabling full-length document processing and multi-hour video analysis with precise temporal navigation.
- Advanced Multimodal Reasoning: Particularly strong in STEM and math—supports causal interpretation and logically grounded, evidence-driven responses.
- Improved Visual Recognition: Expanded, higher-quality training allows broad recognition—from celebrities and anime to consumer goods, landmarks, plants, and animals.
- More Capable OCR: Now supports 32 languages (from 19); performs well under blur, low light, or tilted text; better handles rare/ancient scripts, domain terms, and long-document structure.
- Text Understanding Comparable to Pure LLMs: Achieves seamless integration of text and vision for fully unified comprehension without information loss.
Model Architecture
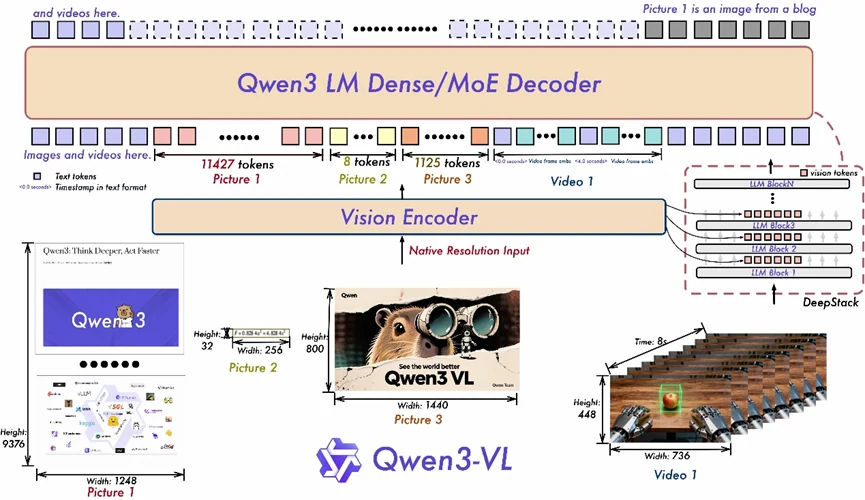
- Interleaved-MRoPE: Utilizes comprehensive positional encoding across temporal and spatial dimensions (time, width, height), boosting long-range video reasoning.
- DeepStack: Integrates multi-layer ViT representations to preserve fine details and strengthen alignment between visual content and text.
- Text–Timestamp Alignment: Advances beyond T-RoPE by grounding events to precise timestamps, significantly improving temporal understanding in video.
Qwen3-VL-8B-Instruct: Model Performance
Multimodal performance
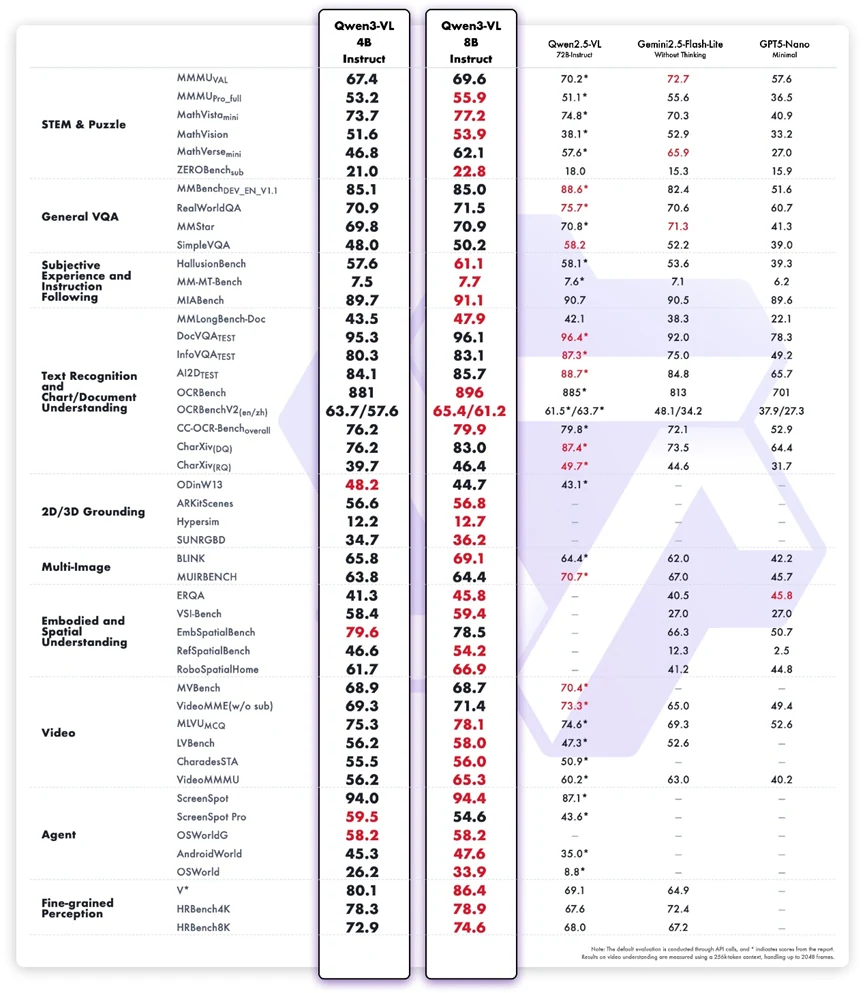
The benchmark results show that Qwen3-VL-8B Instruct delivers well-rounded multimodal performance, especially given its compact scale. It demonstrates notable strengths in STEM reasoning, visual document understanding, and multimodal instruction following, outperforming its 4B counterpart by a clear margin and achieving competitive scores compared with larger or closed-source systems. Tasks such as MathVista, InfoVQA Test, A12Dataset, RobospatialHome, and ScreenSpot highlight its capability to combine textual and visual reasoning for practical workflows. Its strong showing in agent-related benchmarks also reflects solid perception-to-action grounding.
Pure text performance
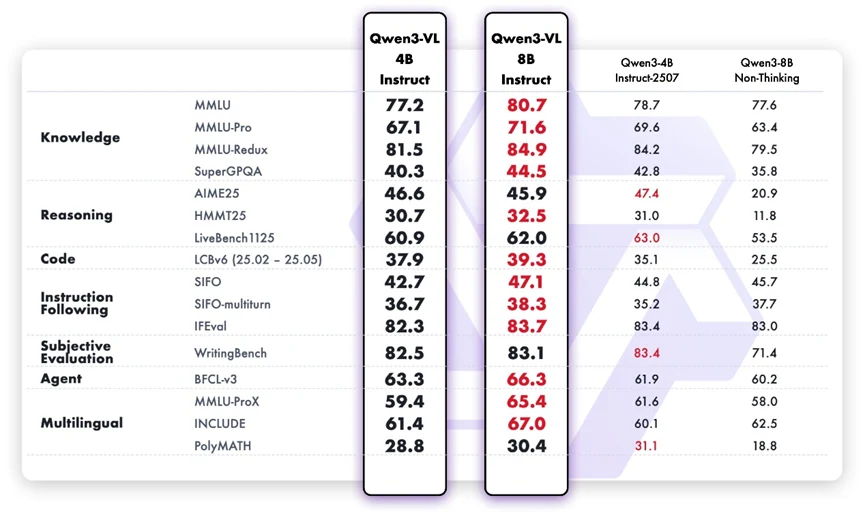
Although designed as a multimodal model, Qwen3-VL-8B Instruct shows strong linguistic strength on pure text tasks. Compared with the 4B version, it exhibits clear gains in factual knowledge, logical reasoning, coding ability, and multi-turn task handling. It follows user intent more accurately, maintains coherence in longer conversations, and demonstrates more reliable judgment in subjective tasks such as preference alignment. Its multilingual improvement also means better inclusiveness for global usage scenarios.
Qwen3-VL-8B-Instruct: Use Cases
Enterprise Knowledge Copilot
Assist employees in retrieving policies, product specifications, and operational procedures from large document repositories. Automatically extract key points and generate summaries to support decision-making in compliance, finance, and technical departments.
Automated App Operation & UI Navigation
Use visual understanding to interact with PC or mobile interfaces—opening apps, submitting forms, or navigating menus. Ideal for replacing or extending traditional RPA in repetitive office or operational workflows.
Video Review & Event Extraction
Analyze long recordings such as meetings, classroom sessions, and surveillance streams. Detect key moments, tag segments, and provide timeline-based search for efficient content review.
Business Document Processing
Digitize and structure invoices, receipts, contracts, and logistics documents captured in real-world conditions. Extract essential fields with layout awareness to streamline financial auditing and onboarding workflows.
Customer Support with Visual Assistance
Understand screenshots and device photos from users to diagnose login issues, configuration errors, or product mismatches. Provide step-by-step guidance to improve remote troubleshooting and service efficiency.
Spatial AI for Robotics & AR Devices
Interpret 2D and 3D environments for navigation and object interaction. Applicable to warehouse robots, home service agents, and augmented-reality guidance in complex spaces.
Design-to-Code Productivity
Convert UI screenshots or sketches into front-end code prototypes. Accelerate handoff between design and engineering teams in digital product development.
How to Access Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct is now available on Novita AI priced at $0.08 / 1M input tokens and $0.50 / 1M output tokens.
Use the Playground (No Coding Required)
Sign up and start experimenting with Qwen3-VL-8B-Instruct in seconds through an interactive interface. Test prompts, see outputs in real-time with the full 200K context window, and compare GLM-4.6 with other leading models. Perfect for prototyping and understanding what the model can do before building full implementations.
Integrate via API (For Developers)
Connect Qwen3-VL-8B-Instruct to your applications using Novita AI’s unified REST API.
Option 1: Direct API Integration (Python Example)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build sophisticated multi-agent systems leveraging Qwen3-VL-8B-Instruct’s advanced document parsing capabilities:
- Plug-and-Play Integration: Use Qwen3-VL-8B-Instruct in any OpenAI Agents workflow
- Advanced Agent Capabilities: Support for handoffs, routing, and tool integration with document understanding
- Scalable Architecture: Design agents that leverage Qwen3-VL-8B-Instruct’s multilingual OCR and element recognition capabilities
Option 3: Connect with Third-Party Platforms
Development Tools: Seamlessly integrate with popular IDEs and development environments like Cursor, Trae, and Cline through OpenAI-compatible APIs and Anthropic-compatible APIs.
Orchestration Frameworks: Connect with LangChain, Dify, CrewAI, Langflow, and other AI orchestration platforms using official connectors.
Hugging Face Integration: Novita AI serves as an official inference provider of Hugging Face, ensuring broad ecosystem compatibility.
What is Qwen3-VL-8B?
Qwen3-VL-8B is a compact multimodal model that understands and processes both text and visual information, supporting analysis, reasoning, and agent-driven task execution.
How does Qwen3-VL-8B handle multimodal input?
It can process images, screenshots, videos, and documents while combining them with text instructions to produce coherent and actionable outputs.
What makes Qwen3-VL-8B different from standard LLMs?
It not only understands information but can also interact with user interfaces and real-world visuals, making it suitable for intelligent automation and embodied AI.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



