

Qwen3-VL-8B-Instruct 現已上線 Novita AI,是 Qwen 系列中視覺語言能力最先進的模型。此次新版本在多個維度都有重大升級:從更精準的文字理解與生成,到更豐富的視覺推理、擴展的上下文處理能力、更優的空間與影片理解,以及更強大的代理級互動能力。模型提供 Dense 與 MoE 兩種版本,可從邊緣裝置擴展到雲端環境,同時還有專注推理的 Thinking 版本與 Instruct 版本,能根據需求彈性部署。
其效能超越主流替代方案,與頂尖視覺語言模型(VLM)相比毫不遜色,且維持適合真實應用的快速推論速度。
什麼是 Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct 是一款最先進的視覺語言模型,設計用於整體理解圖像與文字。基於最新的 Qwen3 架構構建,它以輕量化的 80 億參數規模,提供強大的多模態推理、精準的視覺定位與自然語言生成能力。與前代版本相比,Instruct 版本針對真實場景可用性進行了優化:支援更精準的指令遵循、更優的上下文理解,以及在各種部署環境中更快的推論速度。這些升級使其非常適合從圖像理解、文件解析到多模態代理與互動式 AI 系統等各類應用。
關鍵升級
- 視覺代理能力:可與 PC 與行動裝置介面互動——辨識 UI 元件、解讀其功能、觸發工具並端到端執行任務。
- 視覺轉程式碼加速:可將圖像或影片幀轉換為 Draw.io 圖表、HTML、CSS 或 JavaScript 程式碼。
- 優異的空間智能:可評估物體關聯、視角與遮擋情況;提供更強的 2D 定位能力,並支援 3D 理解以實現空間推理與具身 AI。
- 擴展上下文與影片理解:原生支援 256K 上下文,可擴展至 100 萬,能處理完整長度文件與多小時的影片分析,並提供精準的時間導航功能。
- 先進的多模態推理:在 STEM 與數學領域表現尤其突出——支援因果解讀與基於邏輯、證據的回應。
- 優化的視覺辨識能力:更大規模、更高品質的訓練資料使其能辨識廣泛對象——從名人、動漫角色到消費品、地標、植物與動物。
- 更強大的 OCR 能力:現支援 32 種語言(原為 19 種);在模糊、低光源或傾斜文字場景下表現優異;能更好地處理罕見/古文字、領域術語與長文件結構。
- 與純文字 LLM 相當的文字理解能力:實現文字與視覺的無縫整合,達成完全統一的資訊理解,無資訊遺失。
模型架構
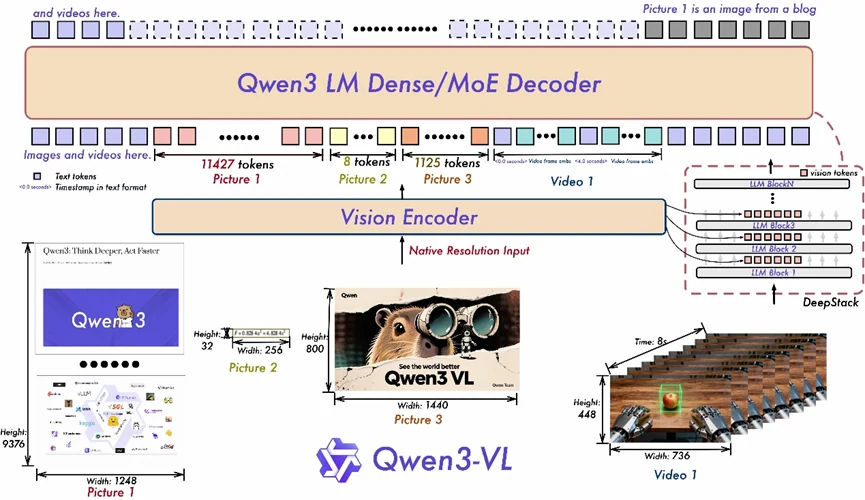
- 交錯式 MRoPE:跨時間與空間維度(時間、寬度、高度)使用全面的位置編碼,提升長距離影片推理能力。
- DeepStack:整合多層 ViT 表徵,保留細部細節,強化視覺內容與文字之間的對齊。
- 文字-時間戳對齊:超越 T-RoPE,將事件錨定到精準的時間戳,大幅提升影片的時間理解能力。
Qwen3-VL-8B-Instruct:模型效能
多模態效能
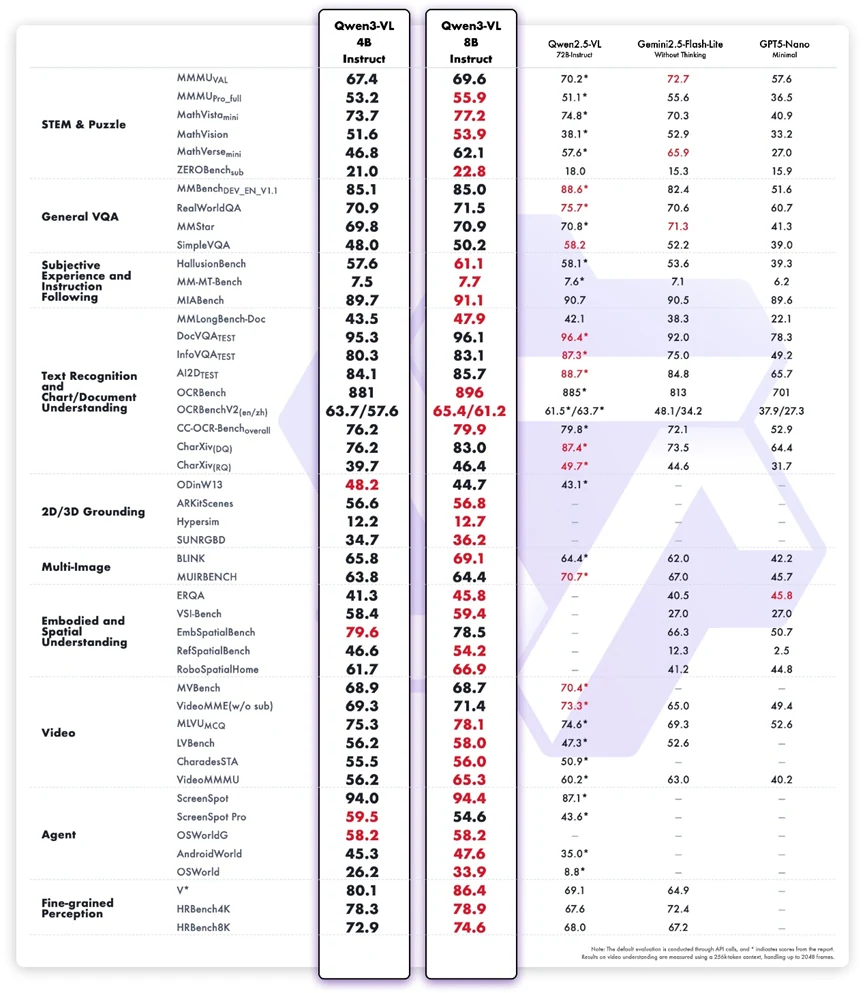
基準測試結果顯示,Qwen3-VL-8B-Instruct 的多模態效能非常全面,尤其考慮到其緊湊的規模。它在 STEM 推理、視覺文件理解與多模態指令遵循方面表現突出,明顯優於同系列的 4B 版本,與更大規模或封閉源系統相比也能取得競爭力的分數。MathVista、InfoVQA 測試、A12Dataset、RobospatialHome、ScreenSpot 等任務凸顯了它結合文字與視覺推理以處理實際工作流程的能力。它在代理相關基準測試中的優異表現也反映了扎實的感知到行動的錨定能力。
純文字效能
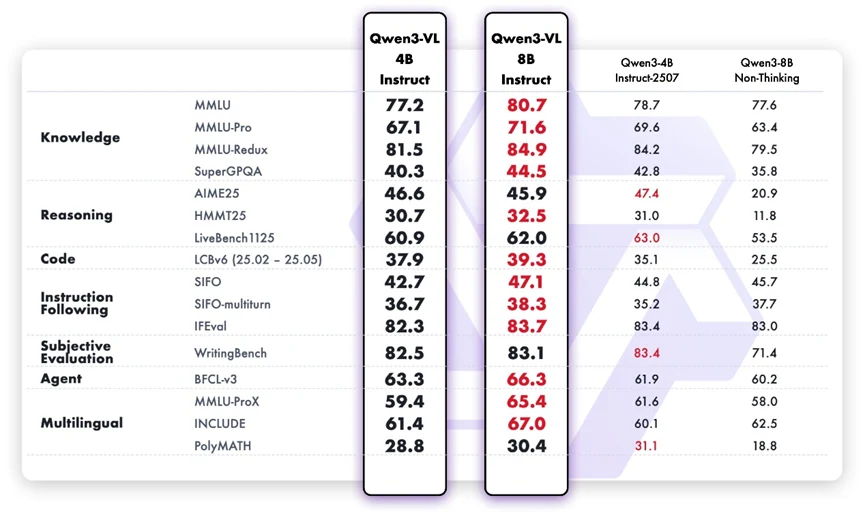
儘管 Qwen3-VL-8B-Instruct 是設計為多模態模型,它在純文字任務上仍展現出強大的語言能力。與 4B 版本相比,它在事實知識、邏輯推理、程式碼能力與多輪任務處理方面都有明顯提升。它能更精準地遵循使用者意圖,在更長的對話中保持連貫性,在偏好對齊這類主觀任務上展現出更可靠的判斷力。其多語言能力的提升也意味著能更好地支援全球使用場景。
Qwen3-VL-8B-Instruct:應用場景
企業知識協作助手
協助員工從大型文件庫中檢索政策、產品規格與作業流程。自動提取重點並生成摘要,支援合規、財務與技術部門的決策。
自動化應用操作與 UI 導航
利用視覺理解與 PC 或行動裝置介面互動——開啟應用程式、提交表單或瀏覽選單。非常適合取代或擴展傳統 RPA,應用於重複性的辦公或營運工作流程。
影片審查與事件提取
分析會議、課堂錄影、監控串流等長時間錄影內容。偵測關鍵時刻、標記片段,並提供基於時間軸的搜尋功能,提升內容審查效率。
企業文件處理
將真實場景拍攝的發票、收據、合約與物流文件數位化並結構化。結合版面感知提取關鍵欄位,簡化財務審計與入職流程。
視覺輔助客戶服務
理解使用者提供的截圖與裝置照片,診斷登入問題、配置錯誤或產品不符情況。提供逐步指引,提升遠端疑難排解與服務效率。
機器人與 AR 裝置的空間 AI
解讀 2D 與 3D 環境以實現導航與物體互動。適用於倉儲機器人、居家服務代理,以及複雜空間中的擴增實境指引。
設計轉程式碼生產力
將 UI 截圖或草圖轉換為前端程式碼原型。加速數位產品開發中設計與工程團隊的交接流程。
如何取用 Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct 現已上線 Novita AI,定價為每 100 萬個輸入 token 0.08 美元,每 100 萬個輸出 token 0.50 美元。
使用 Playground(無需編碼)
註冊 後即可透過互動式介面在幾秒內開始實驗 Qwen3-VL-8B-Instruct。測試提示詞、使用完整的 200K 上下文視窗即時查看輸出,並將 GLM-4.6 與其他領先模型進行比較。非常適合在構建完整實現前進行原型驗證,了解模型的能力。
透過 API 整合(適用開發者)
使用 Novita AI 的统一 REST API 將 Qwen3-VL-8B-Instruct 連接至您的應用程式。
選項 1:直接 API 整合(Python 範例)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
選項 2:使用 OpenAI Agents SDK 構建多代理工作流程
利用 Qwen3-VL-8B-Instruct 先進的文件解析能力,構建複雜的多代理系統:
- 即插即用整合:可在任何 OpenAI Agents 工作流程中使用 Qwen3-VL-8B-Instruct
- 先進代理能力:支援交接、路由,以及結合文件理解的工具整合
- 可擴展架構:設計能利用 Qwen3-VL-8B-Instruct 多語言 OCR 與元素辨識能力的代理
選項 3:連接第三方平台
開發工具:透過 OpenAI 相容 API 與 Anthropic 相容 API,無縫整合 Cursor、Trae、Cline 等熱門 IDE 與開發環境。 編排框架:使用官方連接器連接 LangChain、Dify、CrewAI、Langflow 等 AI 編排平台。 Hugging Face 整合:Novita AI 是 Hugging Face 的官方推論提供者,確保廣泛的生態系統相容性。
什麼是 Qwen3-VL-8B? Qwen3-VL-8B 是一款緊湊型多模態模型,可理解與處理文字與視覺資訊,支援分析、推理與代理驅動的任務執行。
Qwen3-VL-8B 如何處理多模態輸入? 它可以處理圖像、截圖、影片與文件,並將這些內容與文字指令結合,產生連貫且可執行的輸出。
Qwen3-VL-8B 與標準 LLM 有什麼不同? 它不僅能理解資訊,還能與使用者介面與真實世界視覺內容互動,非常適合智慧自動化與具身 AI 場景。
Novita AI 是全能雲端平台,助您實現 AI 抱負。整合 API、無伺服器、GPU 實例——都是您需要的高性價比工具。免除基礎設施煩惱,免費開始,讓您的 AI 願景成為現實。



