

Qwen3-VL-8B-Instruct 现已登陆 Novita AI,带来 Qwen 系列中最先进的视觉语言能力。此次新版本在各个方面均有重大提升——从更准确的文本理解与生成,到更丰富的视觉推理、扩展的上下文处理、更强大的空间与视频理解,以及更智能的智能体交互能力。提供 Dense 和 MoE 两种变体,可从边缘设备扩展到云端环境;同时提供 Instruct 和专注推理的 Thinking 版本,实现灵活、按需的部署。
它超越了主流竞品,可与领先的 VLM 相媲美,并保持适合实际应用的快速推理性能。
什么是 Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct 是一款尖端的视觉语言模型,旨在整体理解图像和文本。基于最新的 Qwen3 架构,它以轻量级 8B 参数规格提供了强大的多模态推理、精准的视觉定位和自然语言生成能力。与之前版本相比,Instruct 变体针对实际可用性进行了优化——支持更准确的指令遵循、改进的上下文理解以及跨多种部署环境的更快推理。这些升级使其非常适合从图像理解、文档解析到多模态智能体和交互式 AI 系统等应用场景。
主要增强
- 视觉智能体能力: 与 PC 和移动界面交互——识别 UI 组件、解释其功能、触发工具并端到端执行任务。
- 视觉到代码加速: 将图像或视频帧转换为 Draw.io 图表、HTML、CSS 或 JavaScript。
- 卓越的空间智能: 评估对象关系、视角和遮挡;提供更强的 2D 定位能力,并支持 3D 理解以用于空间推理和具身 AI。
- 扩展上下文与视频理解: 原生 256K 上下文可扩展至 1M,支持全长文档处理和多小时视频分析,并具备精准的时间定位能力。
- 先进的多模态推理: 在 STEM 和数学领域表现尤为出色——支持因果解释和基于逻辑、证据驱动的响应。
- 改进的视觉识别: 扩展的高质量训练支持广泛识别——从名人、动漫到消费品、地标、植物和动物。
- 更强的 OCR 能力: 现支持 32 种语言(从 19 种扩展);在模糊、低光照或倾斜文本下表现良好;更好地处理稀有/古老文字、领域术语和长文档结构。
- 媲美纯 LLM 的文本理解: 实现文本与视觉的无缝整合,实现统一理解而无信息损失。
模型架构
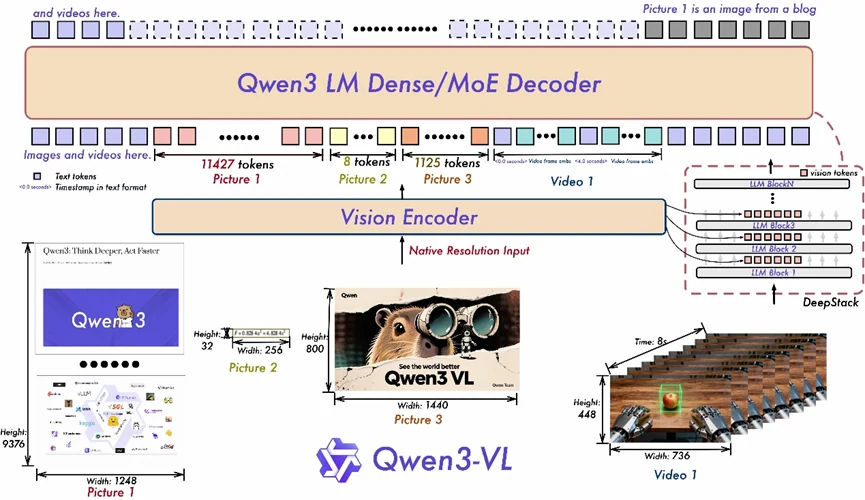
- Interleaved-MRoPE: 利用跨时间和空间维度(时间、宽度、高度)的综合位置编码,提升长程视频推理能力。
- DeepStack: 整合多层 ViT 表示以保留细节,并增强视觉内容与文本之间的对齐。
- 文本-时间戳对齐: 超越 T-RoPE,将事件与精确时间戳相关联,显著提升视频中的时间理解能力。
Qwen3-VL-8B-Instruct:模型性能
多模态性能
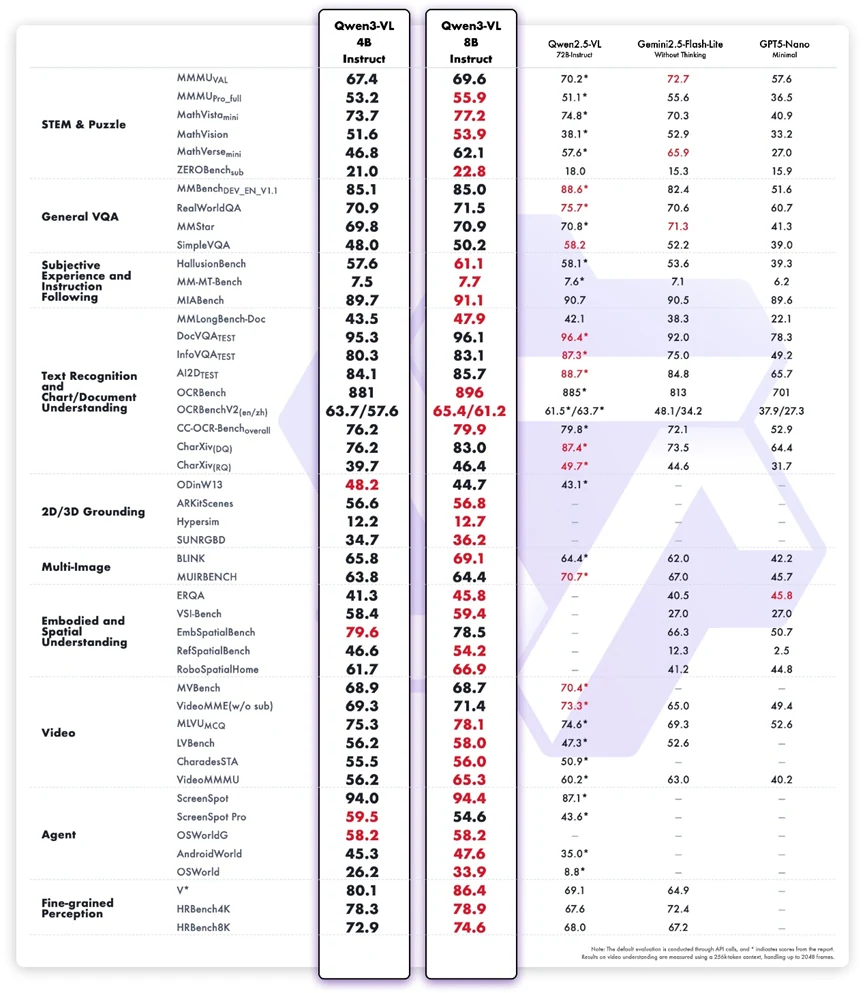
基准测试结果显示,Qwen3-VL-8B Instruct 在紧凑规模下提供了全面均衡的多模态性能。它在 STEM 推理、视觉文档理解和多模态指令遵循方面表现突出,明显超越其 4B 版本,并在与更大或闭源系统的比较中取得了有竞争力的分数。MathVista、InfoVQA Test、A12Dataset、RobospatialHome 和 ScreenSpot 等任务突显了它结合文本与视觉推理以应对实际工作流的能力。在智能体相关基准测试中的强劲表现也反映了稳健的感知到行动的对齐能力。
纯文本性能
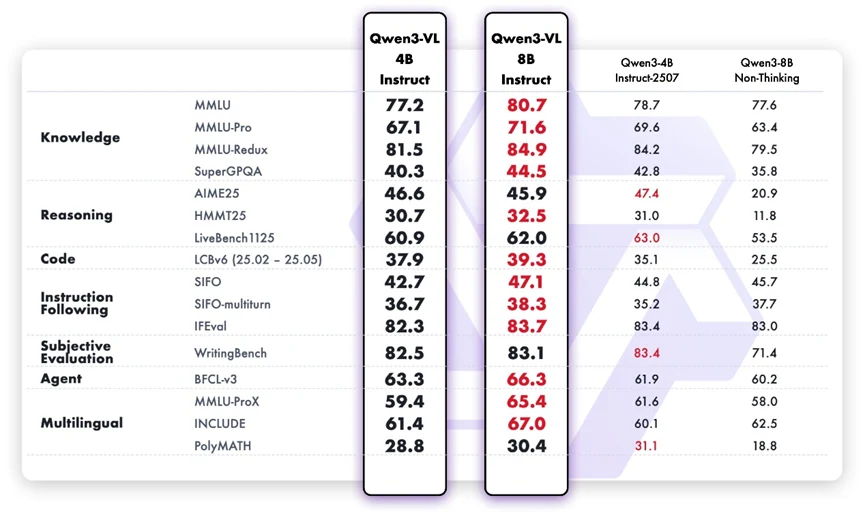
尽管专为多模态设计,Qwen3-VL-8B Instruct 在纯文本任务上同样展现了强大的语言能力。与 4B 版本相比,它在事实知识、逻辑推理、编码能力和多轮任务处理方面有显著提升。它更准确地遵循用户意图,在较长的对话中保持连贯性,并在偏好对齐等主观任务中表现出更可靠的判断力。其多语言能力的改进也意味着对全球使用场景更具包容性。
Qwen3-VL-8B-Instruct:用例
企业知识助理
协助员工从大型文档库中检索政策、产品规格和操作流程。自动提取要点并生成摘要,支持合规、财务和技术部门的决策。
自动化应用操作与 UI 导航
利用视觉理解与 PC 或移动界面交互——打开应用、提交表单或导航菜单。非常适合在重复性的办公或操作工作流中替代或扩展传统 RPA。
视频审查与事件提取
分析会议、课堂和监控录像等长视频。检测关键时刻,标记片段,并提供基于时间轴的搜索以实现高效内容审查。
商业文档处理
数字化并结构化真实场景中拍摄的发票、收据、合同和物流文件。利用布局感知提取关键字段,简化财务审计和入职流程。
带视觉辅助的客服
理解用户提供的截图和设备照片,诊断登录问题、配置错误或产品不匹配。提供逐步指导,提升远程故障排除和客服效率。
用于机器人和 AR 设备的空间 AI
解释 2D 和 3D 环境以进行导航和对象交互。适用于仓库机器人、家庭服务智能体以及复杂空间中的增强现实引导。
设计到代码的生产力提升
将 UI 截图或草图转换为前端代码原型。加速数字产品开发中设计与工程团队之间的交接。
如何访问 Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct 现已在 Novita AI 上可用,价格为 $0.08 / 1M 输入 token 和 $0.50 / 1M 输出 token。
使用 Playground(无需编码)
注册后,通过交互界面在几秒钟内开始体验 Qwen3-VL-8B-Instruct。测试提示,在完整的 200K 上下文窗口中实时查看输出,并将 GLM-4.6 与其他领先模型进行比较。非常适合在构建完整实现前进行原型设计和了解模型能力。
通过 API 集成(面向开发者)
使用 Novita AI 的统一 REST API 将 Qwen3-VL-8B-Instruct 连接到您的应用程序。
选项 1:直接 API 集成(Python 示例)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
选项 2:基于 OpenAI Agents SDK 的多智能体工作流
构建利用 Qwen3-VL-8B-Instruct 高级文档解析功能的复杂多智能体系统:
- 即插即用集成:在任何 OpenAI Agents 工作流中使用 Qwen3-VL-8B-Instruct
- 高级智能体能力:支持交接、路由以及与文档理解结合的工具集成
- 可扩展架构:设计利用 Qwen3-VL-8B-Instruct 多语言 OCR 和元素识别能力的智能体
选项 3:连接第三方平台
开发工具:通过兼容 OpenAI 和 Anthropic 的 API,与流行的 IDE 和开发环境(如 Cursor、Trae 和 Cline)无缝集成。
编排框架:使用官方连接器与 LangChain、Dify、CrewAI、Langflow 及其他 AI 编排平台连接。
Hugging Face 集成:Novita AI 是 Hugging Face 的官方推理提供商,确保广泛的生态兼容性。
什么是 Qwen3-VL-8B?
Qwen3-VL-8B 是一款紧凑型多模态模型,能够理解和处理文本及视觉信息,支持分析、推理以及智能体驱动的任务执行。
Qwen3-VL-8B 如何处理多模态输入?
它可以处理图像、截图、视频和文档,同时结合文本指令生成连贯且可操作的输出。
Qwen3-VL-8B 与标准 LLM 有何不同?
它不仅理解信息,还能与用户界面和真实世界视觉内容交互,使其适用于智能自动化和具身 AI。
Novita AI 是一站式云平台,助力您的 AI 雄心。集成 API、无服务器、GPU 实例——您需要的经济高效的工具。消除基础设施负担,免费开始,让您的 AI 愿景成为现实。



