

أصبح نموذج Qwen3-VL-8B-Instruct متاحًا الآن على منصة Novita AI، ويقدم أقوى قدرات معالجة الرؤية والنصوص حتى الآن ضمن سلسلة نماذج Qwen. يقدم هذا الإصدار الجديد تحسينات كبيرة في جميع الجوانب—بدءًا من فهم النصوص وتوليدها بدقة أكبر، وصولًا إلى تفكير بصري أكثر ثراءً، ومعالجة سياق أوسع، وفهم مكاني وفيديوهات أفضل، وتفاعلات على مستوى الوكلاء أكثر كفاءة. يتوفر النموذج في نسختين: Dense و MoE، ويمكن توسيع نطاقه من الأجهزة الطرفية إلى بيئات السحابة، بالإضافة إلى نسخ Instruct ونسخ Thinking المخصصة للتفكير، مما يسمح بنشر مرن وفقًا للطلب.
يتفوق هذا النموذج على البدائل السائدة، وينافس النماذج الرائدة في مجال الرؤية والنصوص (VLMs)، ويحافظ على أداء استدلال سريع مناسب للتطبيقات الواقعية.
جرب نسخة تجريبية من Qwen3-VL-8B-Instruct
ما هو نموذج Qwen3-VL-8B-Instruct؟
نموذج Qwen3-VL-8B-Instruct هو نموذج رؤية-نصوص متطور مصمم لفهم الصور والنصوص بشكل شامل. مبني على أحدث بنية Qwen3، ويقدم تفكيرًا متعدد الوسائط قويًا، وتحديدًا بصريًا دقيقًا، وتوليدًا للغة الطبيعية في شكل خفيف الوزن بعدد 8 مليار معامل. مقارنة بالإصدارات السابقة، تم تحسين نسخة Instruct للاستخدام الواقعي—فهي تدعم اتباع التعليمات بدقة أكبر، وفهم سياقي محسّن، واستدلال أسرع عبر بيئات نشر متنوعة. تجعل هذه التحسينات النموذج مناسبًا بشكل مثالي للتطبيقات التي تتراوح من فهم الصور وتحليل المستندات إلى الوكلاء متعددي الوسائط وأنظمة الذكاء الاصطناعي التفاعلية.
التحسينات الرئيسية
- قدرات الوكيل البصري: يتفاعل مع واجهات أجهزة الكمبيوتر والأجهزة المحمولة—يتعرف على مكونات واجهة المستخدم، يفسر وظائفها، يشغل الأدوات، وينفذ المهام من البداية إلى النهاية.
- تسريع التحويل من البصري إلى الكود: يحول الصور أو إطارات الفيديو إلى مخططات Draw.io، أو HTML، أو CSS، أو JavaScript.
- ذكاء مكاني متفوق: يقيم علاقات الكائنات، وجهات النظر، والاحتجابات؛ يقدم تحديدًا مكانيًا ثنائي الأبعاد أقوى ويدعم الفهم ثلاثي الأبعاد للتفكير المكاني والذكاء الاصطناعي المادي.
- سياق ممتد وفهم الفيديو: سياق أصلي يبلغ 256 ألف رمز قابل للتوسيع حتى 1 مليون رمز، مما يتيح معالجة المستندات كاملة الطول وتحليل الفيديوهات التي تصل إلى عدة ساعات مع تنقل زمني دقيق.
- تفكير متعدد الوسائط متقدم: قوي بشكل خاص في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM)—يدعم التفسير السببي والاستندادات المنطقية القائمة على الأدلة.
- تعرف بصري محسّن: تدريب موسع وعالي الجودة يسمح بتعرف واسع النطاق—بدءًا من المشاهير والأنيمي، وصولًا إلى السلع الاستهلاكية، والمعالم، والنباتات، والحيوانات.
- تقنية التعرف الضوئي على الحروف (OCR) أكثر كفاءة: تدعم الآن 32 لغة (مقابل 19 سابقًا)، وتؤدي أداءً جيدًا حتى مع النصوص الضبابية، أو الإضاءة المنخفضة، أو النصوص المائلة، وتتعامل بشكل أفضل مع النصوص النادرة/القديمة، والمصطلحات المتخصصة، وهيكل المستندات الطويلة.
- فهم النصوص مكافئ للنماذج اللغوية الكبيرة النقية (LLMs): يحقق تكاملًا سلسًا بين النصوص والرؤية لفهم موحد بالكامل دون فقدان للمعلومات.
بنية النموذج
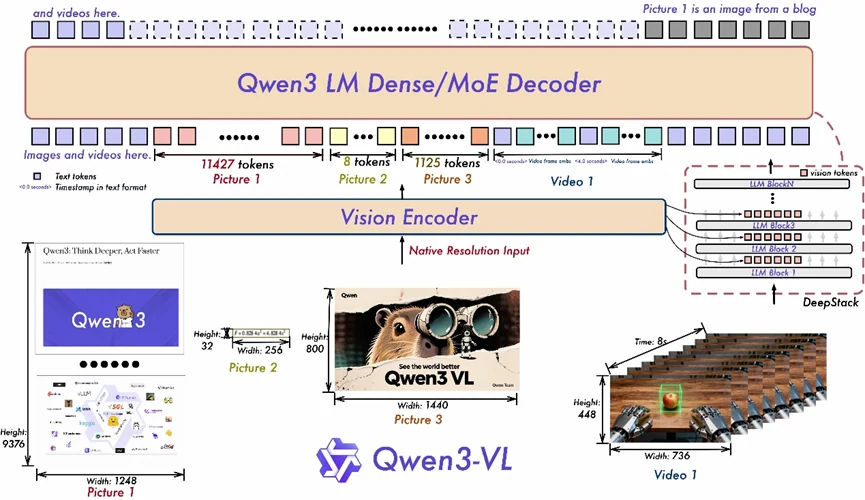
- Interleaved-MRoPE: يستخدم ترميزًا موضعيًا شاملاً عبر الأبعاد الزمانية والمكانية (الوقت، العرض، الارتفاع)، مما يعزز التفكير في الفيديوهات طويلة المدى.
- DeepStack: يدمج تمثيلات متعددة الطبقات من ViT للحفاظ على التفاصيل الدقيقة وتعزيز المحاذاة بين المحتوى البصري والنصوص.
- محاذاة النصوص مع الطوابع الزمنية: يتجاوز تقنية T-RoPE من خلال ربط الأحداث بطوابع زمنية دقيقة، مما يحسن بشكل كبير الفهم الزماني في الفيديوهات.
أداء نموذج Qwen3-VL-8B-Instruct
الأداء متعدد الوسائط
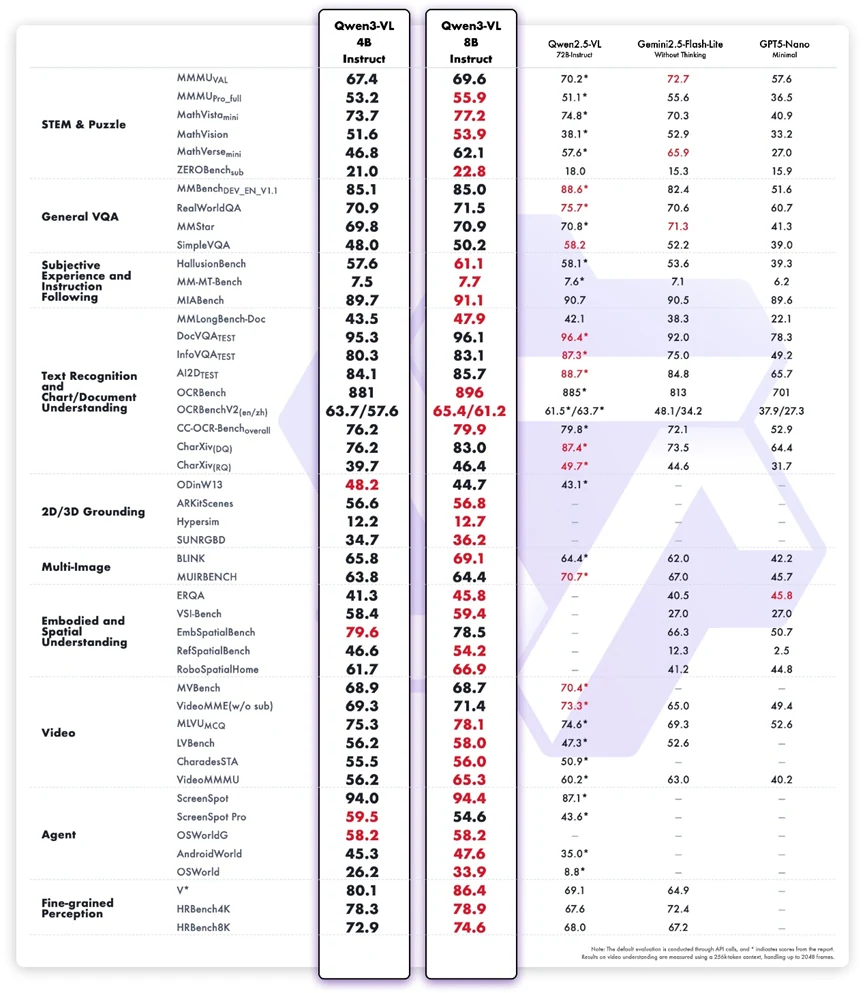
تظهر نتائج الاختبارات المعيارية أن نموذج Qwen3-VL-8B Instruct يقدم أداءً متعدد الوسائط متوازنًا، خاصةً نظرًا لحجمه المدمج. يظهر قوة ملحوظة في تفكير مجالات STEM، وفهم المستندات البصرية، واتباع التعليمات متعددة الوسائط، حيث يتفوق على نسخته ذات 4 مليار معامل بفارق واضح، ويحقق درجات تنافسية مقارنة بالنظم الأكبر أو المغلقة المصدر. تسلط المهام مثل MathVista، واختبار InfoVQA، ومجموعة بيانات A12، و RobospatialHome، و ScreenSpot الضوء على قدرته على الجمع بين التفكير النصي والبصري لسير العمل الواقعية. كما يعكس أدائه القوي في اختبارات الوكلاء قدرة راسخة على ربط الإدراك بالإجراءات.
الأداء في المهام النصية البحتة
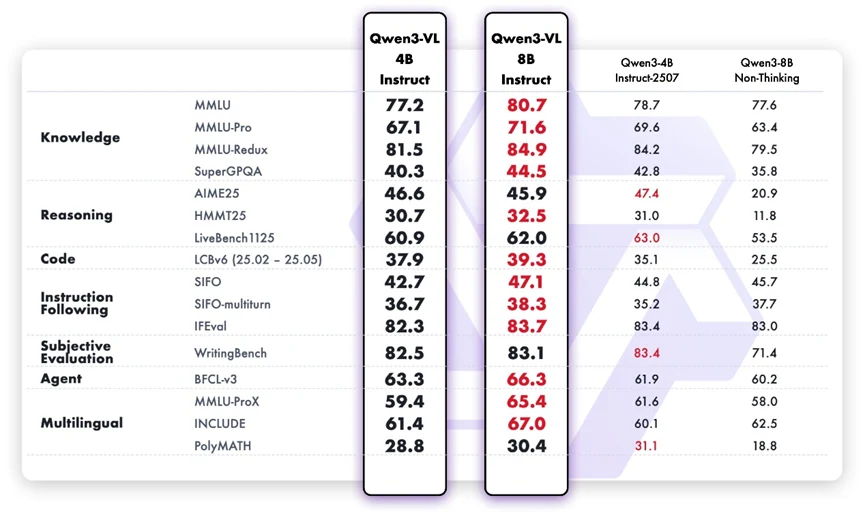
على الرغم من أنه مصمم كنموذج متعدد الوسائط، يظهر نموذج Qwen3-VL-8B Instruct قوة لغوية كبيرة في المهام النصية البحتة. مقارنة بالنسخة ذات 4 مليار معامل، يظهر مكاسب واضحة في المعرفة الواقعية، والتفكير المنطقي، وقدرات البرمجة، ومعالجة المهام متعددة الجولات. يتبع نية المستخدم بدقة أكبر، ويحافظ على التماسك في المحادثات الأطول، ويظهر حكمًا أكثر موثوقية في المهام الذاتية مثل محاذاة التفضيلات. كما يعني تحسينه متعدد اللغات شمولية أفضل لسيناريوهات الاستخدام العالمية.
حالات استخدام نموذج Qwen3-VL-8B-Instruct
مساعد المعرفة للمؤسسات
يساعد الموظفين على استرجاع السياسات، ومواصفات المنتجات، والإجراءات التشغيلية من مستودعات المستندات الكبيرة. يستخرج النقاط الرئيسية تلقائيًا ويولد ملخصات لدعم اتخاذ القرار في أقسام الامتثال، والمالية، والتقنية.
تشغيل التطبيقات تلقائيًا والتنقل عبر واجهة المستخدم
يستخدم الفهم البصري للتفاعل مع واجهات أجهزة الكمبيوتر أو الأجهزة المحمولة—فتح التطبيقات، إرسال النماذج، أو التنقل عبر القوائم. مثالي لاستبدال أو توسيع نطاق أتمتة العمليات الروبوتية (RPA) التقليدية في سير العمل المكتبية أو التشغيلية المتكررة.
مراجعة الفيديوهات واستخراج الأحداث
يحلل التسجيلات الطويلة مثل الاجتماعات، وجلسات الفصول الدراسية، وتسجيلات المراقبة. يكتشف اللحظات الرئيسية، ويضع علامات على المقاطع، ويوفر بحثًا قائمًا على الجدول الزمني لمراجعة المحتوى بكفاءة.
معالجة مستندات الأعمال
يرقمن ويقوم بتهيئة الفواتير، والإيصالات، والعقود، ومستندات اللوجستيات الملتقطة في ظروف واقعية. يستخرج الحقول الأساسية مع وعي بالتخطيط لتبسيط عمليات التدقيق المالي وسير عمل إعداد الموظفين الجدد.
دعم العملاء بمساعدة بصرية
يفهم لقطات الشاشة وصور الأجهزة من المستخدمين لتشخيص مشاكل تسجيل الدخول، وأخطاء التكوين، أو عدم تطابق المنتجات. يقدم إرشادات خطوة بخطوة لتحسين استكشاف الأخطاء عن بعد وكفاءة الخدمة.
الذكاء المكاني للروبوتات وأجهزة الواقع المعزز (AR)
يفهم البيئات ثنائية وثلاثية الأبعاد للتنقل والتفاعل مع الكائنات. قابل للتطبيق على روبوتات المستودعات، ووكلاء الخدمة المنزلية، وإرشادات الواقع المعزز في المساحات المعقدة.
إنتاجية تحويل التصميم إلى كود
يحول لقطات شاشة واجهة المستخدم أو الرسومات التخطيطية إلى نماذج أولية لكود الواجهة الأمامية. يسرع عملية التسليم بين فرق التصميم والهندسة في تطوير المنتجات الرقمية.
كيف يمكنك الوصول إلى نموذج Qwen3-VL-8B-Instruct؟
نموذج Qwen3-VL-8B-Instruct متاح الآن على منصة Novita AI بسعر 0.08 دولار لكل مليون رمز إدخال، و 0.50 دولار لكل مليون رمز إخراج.
استخدم بيئة التجربة التفاعلية (لا تتطلب برمجة)
سجل الآن وابدأ في تجربة نموذج Qwen3-VL-8B-Instruct في ثوانٍ عبر واجهة تفاعلية. اختبر الأوامر، وشاهد المخرجات في الوقت الفعلي مع نافذة السياق الكاملة البالغة 200 ألف رمز، وقارن نموذج GLM-4.6 مع النماذج الرائدة الأخرى. مثالي للنماذج الأولية وفهم إمكانيات النموذج قبل بناء تطبيقات كاملة.
التكامل عبر واجهة برمجة التطبيقات (API) (للمطورين)
اربط نموذج Qwen3-VL-8B-Instruct بتطبيقاتك باستخدام واجهة برمجة التطبيقات REST الموحدة لمنصة Novita AI.
الخيار 1: التكامل المباشر عبر API (مثال بلغة بايثون)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
الخيار 2: سير عمل متعددة الوكلاء باستخدام OpenAI Agents SDK
ابنِ أنظمة متعددة الوكلاء متطورة تستفيد من قدرات تحليل المستندات المتقدمة لنموذج Qwen3-VL-8B-Instruct:
- تكامل يعمل فورًا: استخدم نموذج Qwen3-VL-8B-Instruct في أي سير عمل لوكلاء OpenAI
- قدرات وكيل متقدمة: دعم عمليات التسليم، والتوجيه، وتكامل الأدوات مع فهم المستندات
- بنية قابلة للتوسيع: صمم وكلاء تستفيد من قدرات التعرف الضوئي على الحروف متعدد اللغات وقدرات التعرف على العناصر لنموذج Qwen3-VL-8B-Instruct
الخيار 3: الاتصال بمنصات الطرف الثالث
أدوات التطوير: تكامل سلس مع بيئات التطوير المتكاملة (IDEs) الشائعة وبيئات التطوير مثل Cursor و Trae و Cline عبر واجهات برمجة التطبيقات المتوافقة مع OpenAI وواجهات برمجة التطبيقات المتوافقة مع Anthropic.
أطر تنسيق سير العمل: اتصل بـ LangChain و Dify و CrewAI و Langflow ومنصات تنسيق الذكاء الاصطناعي الأخرى باستخدام موصلات رسمية.
تكامل مع منصة Hugging Face: تعمل منصة Novita AI كمزود استدلال رسمي لمنصة Hugging Face، مما يضمن توافقًا واسعًا مع النظام البيئي.
ما هو نموذج Qwen3-VL-8B؟ نموذج Qwen3-VL-8B هو نموذج متعدد الوسائط مدمج يفهم ويعالج كل من النصوص والمعلومات البصرية، ويدعم التحليل، والتفكير، وتنفيذ المهام التي يقودها الوكلاء.
كيف يتعامل نموذج Qwen3-VL-8B مع المدخلات متعددة الوسائط؟ يمكنه معالجة الصور، ولقطات الشاشة، والفيديوهات، والمستندات مع دمجها مع تعليمات نصية لإنتاج مخرجات متماسكة وقابلة للتنفيذ.
ما الذي يميز نموذج Qwen3-VL-8B عن النماذج اللغوية الكبيرة القياسية (LLMs)؟ لا يفهم المعلومات فقط، بل يمكنه أيضًا التفاعل مع واجهات المستخدم والصور الواقعية، مما يجعله مناسبًا للأتمتة الذكية والذكاء الاصطناعي المادي.
Novita AI هي منصة سحابية شاملة تمكّنك من تحقيق طموحاتك في مجال الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، خدمات بدون خوادم، مثيلات وحدات معالجة الرسوميات (GPU) — هي الأدوات التي تحتاجها بتكلفة فعالة. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في مجال الذكاء الاصطناعي.



