

O Qwen3-VL-8B-Instruct já está disponível na Novita AI, oferecendo as capacidades de visão e linguagem mais avançadas já lançadas na linha Qwen. Esta nova versão traz melhorias significativas em todas as dimensões: desde compreensão e geração de texto mais precisas, raciocínio visual mais rico, manipulação de contexto expandida, melhor compreensão espacial e de vídeo, até interações de nível de agente mais capazes. Oferecido nas variantes Dense e MoE, que escalam de dispositivos de borda a ambientes de nuvem, além das edições Instruct e Thinking focada em raciocínio, para implantação adaptável e sob demanda. Ele supera alternativas mainstream, compete de igual para igual com os principais VLMs e mantém um desempenho de inferência rápido adequado para aplicações do mundo real.
Experimentar a Demonstração do Qwen3-VL-8B-Instruct
O que é o Qwen3-VL-8B-Instruct?
O Qwen3-VL-8B-Instruct é um modelo de visão e linguagem de ponta, projetado para compreender imagens e texto de forma holística. Construído na mais recente arquitetura Qwen3, ele oferece raciocínio multimodal robusto, fundamentação visual precisa e geração de linguagem natural em um formato leve de 8 bilhões de parâmetros. Comparado com iterações anteriores, a variante Instruct foi otimizada para usabilidade no mundo real: oferece seguimento de instruções mais preciso, compreensão contextual aprimorada e inferência mais rápida em diversos ambientes de implantação. Essas atualizações o tornam adequado para aplicações que vão desde compreensão de imagens e análise de documentos até agentes multimodais e sistemas de IA interativos.
Principais Aprimoramentos
- Capacidades de Agente Visual: Interage com interfaces de PC e dispositivos móveis: identifica componentes de interface, interpreta suas funções, aciona ferramentas e executa tarefas de ponta a ponta.
- Aceleração de Visual para Código: Converte imagens ou quadros de vídeo em diagramas Draw.io, HTML, CSS ou JavaScript.
- Inteligência Espacial Superior: Avalia relações entre objetos, pontos de vista e oclusões; oferece fundamentação 2D mais forte e suporte a compreensão 3D para raciocínio espacial e IA incorporada.
- Contexto Estendido e Compreensão de Vídeo: Contexto nativo de 256K expansível para 1M, permitindo processamento de documentos de comprimento total e análise de vídeos de várias horas com navegação temporal precisa.
- Raciocínio Multimodal Avançado: Particularmente forte em STEM e matemática: oferece suporte a interpretação causal e respostas logicamente fundamentadas e baseadas em evidências.
- Reconhecimento Visual Aprimorado: O treinamento expandido e de maior qualidade permite reconhecimento amplo: de celebridades e anime a bens de consumo, pontos turísticos, plantas e animais.
- OCR Mais Capaz: Agora oferece suporte a 32 idiomas (de 19); tem bom desempenho com texto borrado, pouca luz ou inclinado; lida melhor com scripts raros/antigos, termos de domínio e estrutura de documentos longos.
- Compreensão de Texto Comparável a LLMs Puros: Alcança integração perfeita entre texto e visão para compreensão totalmente unificada sem perda de informação.
Arquitetura do Modelo
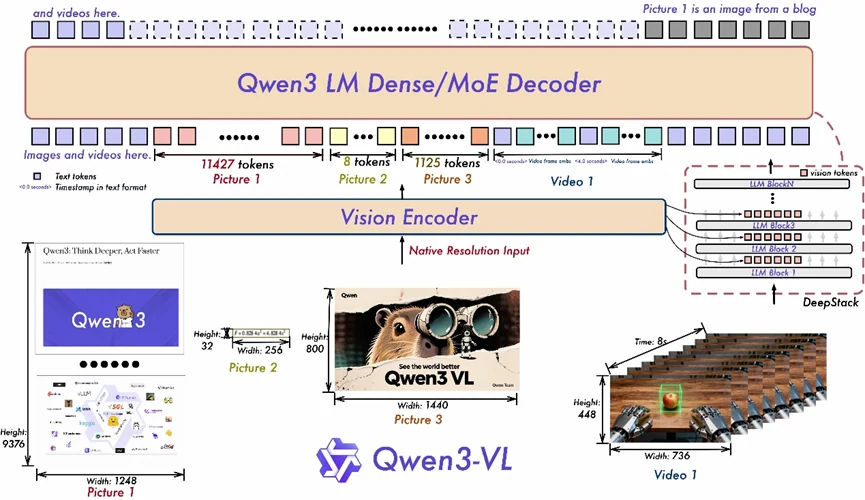
- Interleaved-MRoPE: Utiliza codificação posicional abrangente nas dimensões temporal e espacial (tempo, largura, altura), aumentando o raciocínio de vídeo de longo alcance.
- DeepStack: Integra representações ViT de múltiplas camadas para preservar detalhes finos e fortalecer o alinhamento entre conteúdo visual e texto.
- Alinhamento Texto–Timestamp: Avança além do T-RoPE ao fundamentar eventos em carimbos de data/hora precisos, melhorando significativamente a compreensão temporal em vídeos.
Qwen3-VL-8B-Instruct: Desempenho do Modelo
Desempenho Multimodal
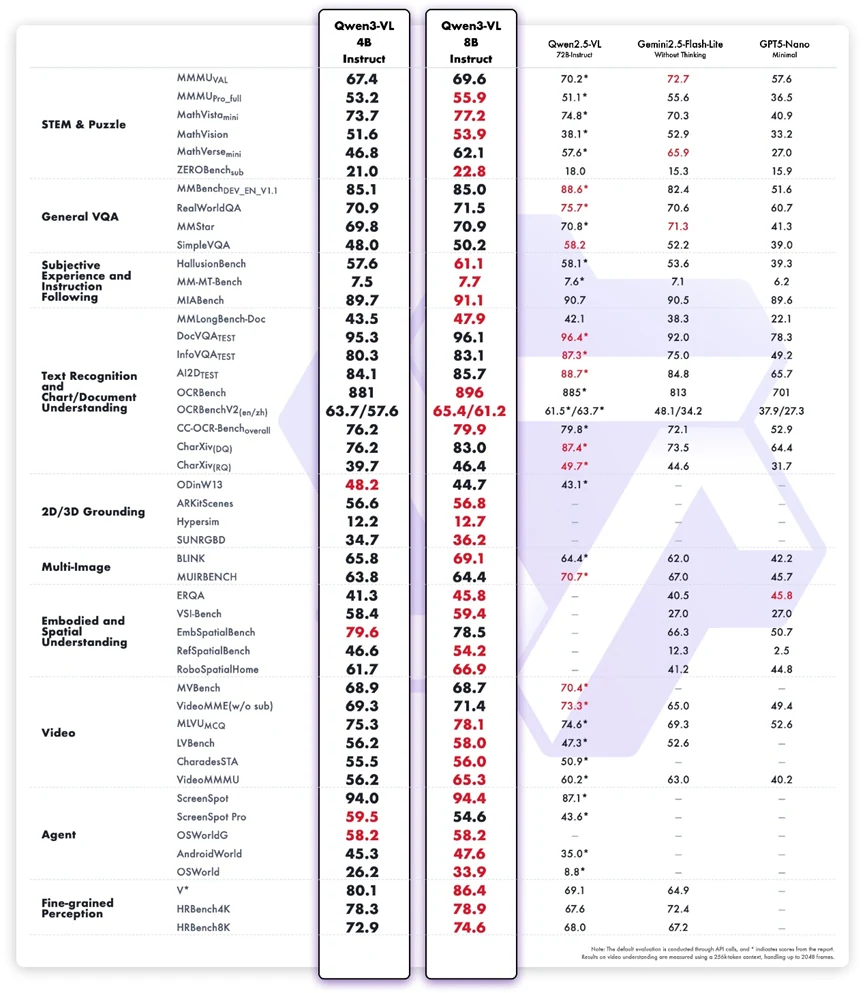
Os resultados de benchmark mostram que o Qwen3-VL-8B Instruct oferece um desempenho multimodal equilibrado, especialmente considerando seu tamanho compacto. Ele demonstra forças notáveis em raciocínio STEM, compreensão de documentos visuais e seguimento de instruções multimodais, superando sua versão de 4B por uma margem clara e atingindo pontuações competitivas em comparação com sistemas maiores ou de código fechado. Tarefas como MathVista, InfoVQA Test, A12Dataset, RobospatialHome e ScreenSpot destacam sua capacidade de combinar raciocínio textual e visual para fluxos de trabalho práticos. Seu bom desempenho em benchmarks relacionados a agentes também reflete uma fundamentação sólida de percepção para ação.
Desempenho em Texto Puro
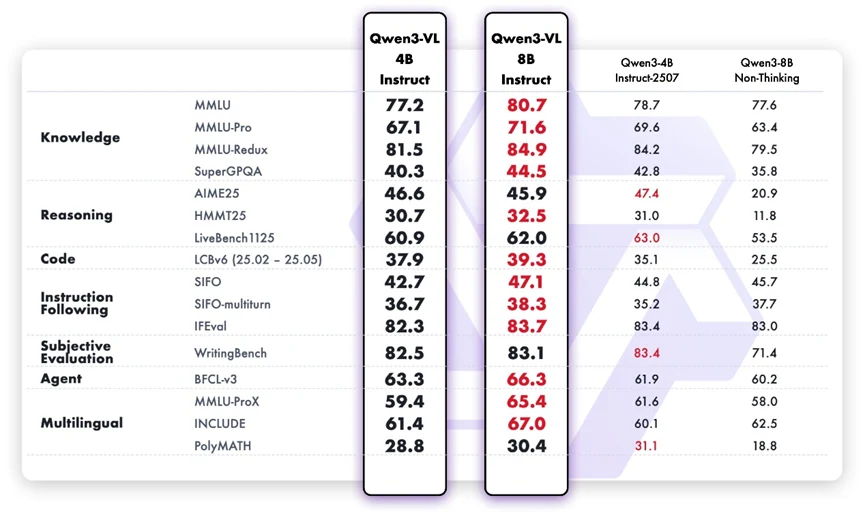
Embora projetado como um modelo multimodal, o Qwen3-VL-8B Instruct demonstra forte capacidade linguística em tarefas de texto puro. Comparado com a versão de 4B, apresenta ganhos claros em conhecimento factual, raciocínio lógico, capacidade de programação e manipulação de tarefas multirrôlidas. Ele segue a intenção do usuário com mais precisão, mantém a coerência em conversas mais longas e demonstra julgamento mais confiável em tarefas subjetivas, como alinhamento de preferências. Sua melhoria multilíngue também significa maior inclusividade para cenários de uso globais.
Qwen3-VL-8B-Instruct: Casos de Uso
Copilot de Conhecimento Empresarial
Ajude os funcionários a recuperar políticas, especificações de produtos e procedimentos operacionais de grandes repositórios de documentos. Extraia automaticamente pontos-chave e gere resumos para apoiar a tomada de decisão nos departamentos de conformidade, finanças e técnico.
Operação Automatizada de Aplicativos e Navegação de Interface
Use a compreensão visual para interagir com interfaces de PC ou dispositivos móveis: abrir aplicativos, enviar formulários ou navegar por menus. Ideal para substituir ou estender o RPA tradicional em fluxos de trabalho de escritório ou operacionais repetitivos.
Revisão de Vídeo e Extração de Eventos
Analise gravações longas, como reuniões, sessões de sala de aula e fluxos de vigilância. Detecte momentos-chave, marque segmentos e forneça pesquisa baseada em linha do tempo para revisão eficiente de conteúdo.
Processamento de Documentos Empresariais
Digitalize e estruture faturas, recibos, contratos e documentos de logística capturados em condições do mundo real. Extraia campos essenciais com consciência de layout para agilizar fluxos de trabalho de auditoria financeira e integração de novos colaboradores.
Suporte ao Cliente com Assistência Visual
Compreenda capturas de tela e fotos de dispositivos enviadas por usuários para diagnosticar problemas de login, erros de configuração ou incompatibilidades de produtos. Forneça orientação passo a passo para melhorar o suporte remoto e a eficiência do serviço.
IA Espacial para Robótica e Dispositivos de AR
Interprete ambientes 2D e 3D para navegação e interação com objetos. Aplicável a robôs de armazém, agentes de serviço doméstico e orientação de realidade aumentada em espaços complexos.
Produtividade de Design para Código
Converta capturas de tela de interface ou esboços em protótipos de código front-end. Acelere a transferência de trabalho entre equipes de design e engenharia no desenvolvimento de produtos digitais.
Como Acessar o Qwen3-VL-8B-Instruct?
O Qwen3-VL-8B-Instruct já está disponível na Novita AI pelo preço de $0,08 por 1M de tokens de entrada e $0,50 por 1M de tokens de saída.
Use o Playground (Não é Necessário Código)
Cadastre-se e comece a experimentar o Qwen3-VL-8B-Instruct em segundos por meio de uma interface interativa. Teste prompts, veja saídas em tempo real com a janela de contexto completa de 200K e compare o GLM-4.6 com outros modelos líderes. Perfeito para prototipagem e para entender o que o modelo pode fazer antes de construir implementações completas.
Integre via API (Para Desenvolvedores)
Conecte o Qwen3-VL-8B-Instruct aos seus aplicativos usando a API REST unificada da Novita AI.
Opção 1: Integração Direta via API (Exemplo em Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Opção 2: Fluxos de Trabalho Multiagente com o OpenAI Agents SDK
Construa sistemas multiagente sofisticados aproveitando as capacidades avançadas de análise de documentos do Qwen3-VL-8B-Instruct:
- Integração Plug-and-Play: Use o Qwen3-VL-8B-Instruct em qualquer fluxo de trabalho do OpenAI Agents
- Capacidades de Agente Avançadas: Suporte a transferências, roteamento e integração de ferramentas com compreensão de documentos
- Arquitetura Escalável: Projete agentes que aproveitem as capacidades de OCR multilíngue e reconhecimento de elementos do Qwen3-VL-8B-Instruct
Opção 3: Conecte com Plataformas de Terceiros
Ferramentas de Desenvolvimento: Integre-se perfeitamente com IDEs populares e ambientes de desenvolvimento como Cursor, Trae e Cline por meio de APIs compatíveis com OpenAI e APIs compatíveis com Anthropic.
Frameworks de Orquestração: Conecte-se com LangChain, Dify, CrewAI, Langflow e outras plataformas de orquestração de IA usando conectores oficiais.
Integração com Hugging Face: A Novita AI atua como um provedor de inferência oficial do Hugging Face, garantindo ampla compatibilidade com o ecossistema.
O que é o Qwen3-VL-8B?
O Qwen3-VL-8B é um modelo multimodal compacto que compreende e processa informações textuais e visuais, oferecendo suporte a análise, raciocínio e execução de tarefas orientadas por agentes.
Como o Qwen3-VL-8B lida com entradas multimodais?
Ele pode processar imagens, capturas de tela, vídeos e documentos, combinando-os com instruções de texto para produzir saídas coerentes e acionáveis.
O que torna o Qwen3-VL-8B diferente dos LLMs padrão?
Ele não apenas compreende informações, mas também pode interagir com interfaces de usuário e visuais do mundo real, tornando-o adequado para automação inteligente e IA incorporada.
Novita AI é a plataforma de nuvem tudo-em-um que potencializa suas ambições de IA. APIs integradas, serverless, Instâncias de GPU — as ferramentas econômicas que você precisa. Elimine infraestrutura, comece gratuitamente e torne sua visão de IA uma realidade.



