

Qwen3-VL-8B-Instruct теперь доступен на Novita AI, предлагая самые передовые возможности визуально-языкового взаимодействия на сегодняшний день в линейке Qwen. Этот новый релиз приносит значительные улучшения по всем направлениям: от более точного понимания и генерации текста до более глубокого визуального рассуждения, расширенной обработки контекста, улучшенного пространственного интеллекта и понимания видео, а также более эффективных взаимодействий на уровне агентов. Доступен в вариантах Dense и MoE, которые масштабируются от периферийных устройств до облачных сред, а также в редакциях Instruct и ориентированной на рассуждение Thinking для адаптивного развертывания по требованию.
Он превосходит распространенные альтернативы, достойно конкурирует с ведущими VLM и сохраняет высокую скорость инференса, подходящую для реальных приложений.
Попробовать демо Qwen3-VL-8B-Instruct
Что такое Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct — это передовая визуально-языковая модель, designed для целостного понимания изображений и текста. Построенная на новейшей архитектуре Qwen3, она обеспечивает мощное мультимодальное рассуждение, точную визуальную привязку и генерацию естественного языка в легком форм-факторе с 8 млрд параметров. По сравнению с предыдущими версиями, вариант Instruct был оптимизирован для удобства использования в реальных условиях: поддерживает более точное выполнение инструкций, улучшенное понимание контекста и более быстрый инференс в разнообразных средах развертывания. Эти обновления делают модель хорошо подходящей для приложений ranging от понимания изображений и парсинга документов до мультимодальных агентов и интерактивных ИИ-систем.
Ключевые улучшения
- Возможности визуального агента: Взаимодействует с интерфейсами ПК и мобильных устройств — определяет компоненты UI, интерпретирует их функции, запускает инструменты и выполняет задачи от начала до конца.
- Ускорение преобразования визуальных данных в код: Преобразует изображения или кадры видео в диаграммы Draw.io, HTML, CSS или JavaScript.
- Превосходный пространственный интеллект: Оценивает отношения между объектами, точки обзора и окклюзии; обеспечивает более надежную 2D-привязку и поддерживает 3D-понимание для пространственного рассуждения и воплощенного ИИ.
- Расширенный контекст и понимание видео: Нативный контекст 256K, расширяемый до 1M, что позволяет обрабатывать документы полной длины и анализировать видео длительностью в несколько часов с точной навигацией по временной шкале.
- Продвинутое мультимодальное рассуждение: Особенно сильное в STEM и математике — поддерживает причинно-следственную интерпретацию и логически обоснованные, основанные на доказательствах ответы.
- Улучшенное визуальное распознавание: Расширенное обучение более высокого качества позволяет широкое распознавание — от знаменитостей и аниме до потребительских товаров, достопримечательностей, растений и животных.
- Более мощный OCR: Теперь поддерживает 32 языка (ранее 19); хорошо работает при размытии, низком освещении или наклонном тексте; лучше обрабатывает редкие/древние шрифты, предметные термины и структуру длинных документов.
- Понимание текста на уровне чистых LLM: Обеспечивает бесшовную интеграцию текста и визуальных данных для полностью унифицированного понимания без потери информации.
Архитектура модели
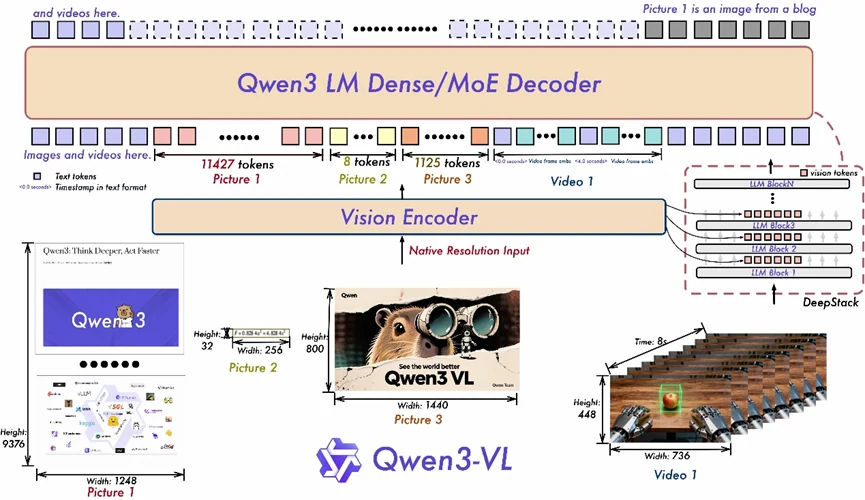
- Interleaved-MRoPE: Использует комплексное позиционное кодирование по временным и пространственным измерениям (время, ширина, высота), улучшая рассуждение на длинных видео.
- DeepStack: Интегрирует представления многослойного ViT для сохранения мелких деталей и усиления соответствия между визуальным контентом и текстом.
- Выравнивание текст–временная метка: Превышает возможности T-RoPE за счет привязки событий к точным временным меткам, значительно улучшая временное понимание в видео.
Производительность модели Qwen3-VL-8B-Instruct
Мультимодальная производительность
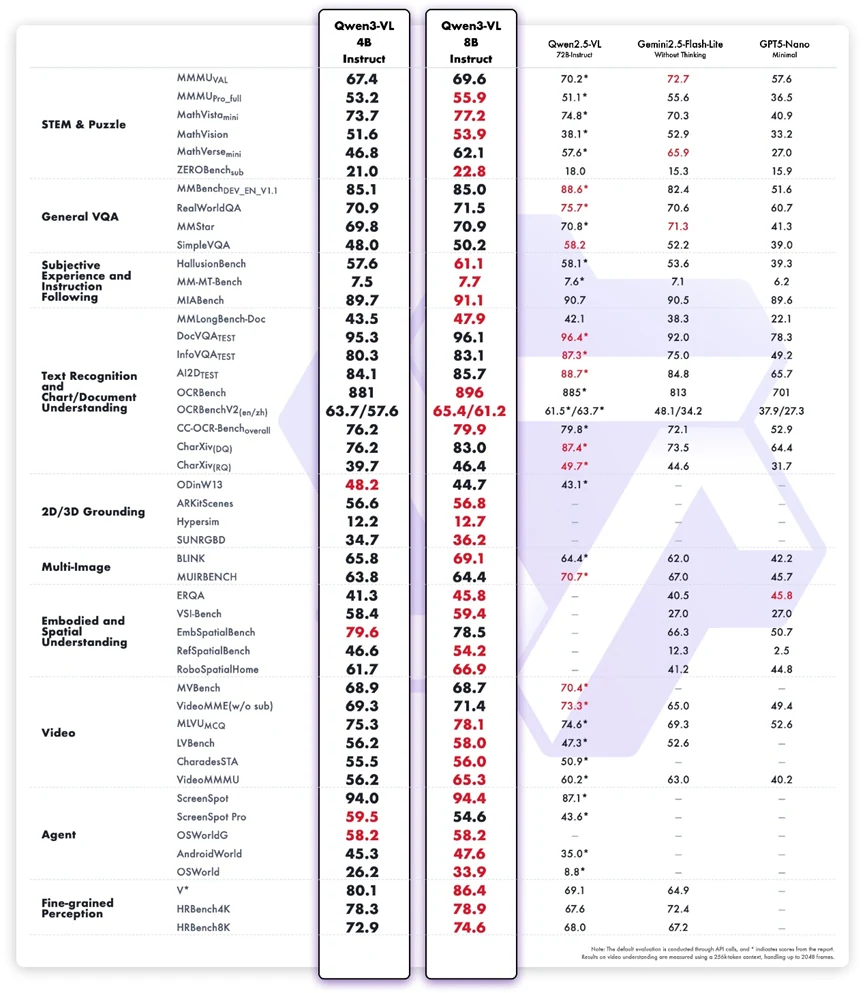
Результаты бенчмарков показывают, что Qwen3-VL-8B-Instruct обеспечивает всестороннюю мультимодальную производительность, особенно учитывая его компактный размер. Модель демонстрирует заметные преимущества в рассуждении в области STEM, понимании визуальных документов и выполнении мультимодальных инструкций, значительно превосходя свою 4B-версию и достигая конкурентоспособных показателей по сравнению с более крупными или закрытыми системами. Задачи такие как MathVista, InfoVQA Test, A12Dataset, RobospatialHome и ScreenSpot подчеркивают способность модели сочетать текстовое и визуальное рассуждение для практических рабочих процессов. Ее сильные результаты в бенчмарках, связанных с агентами, также отражают надежную привязку от восприятия к действию.
Производительность на чистом тексте
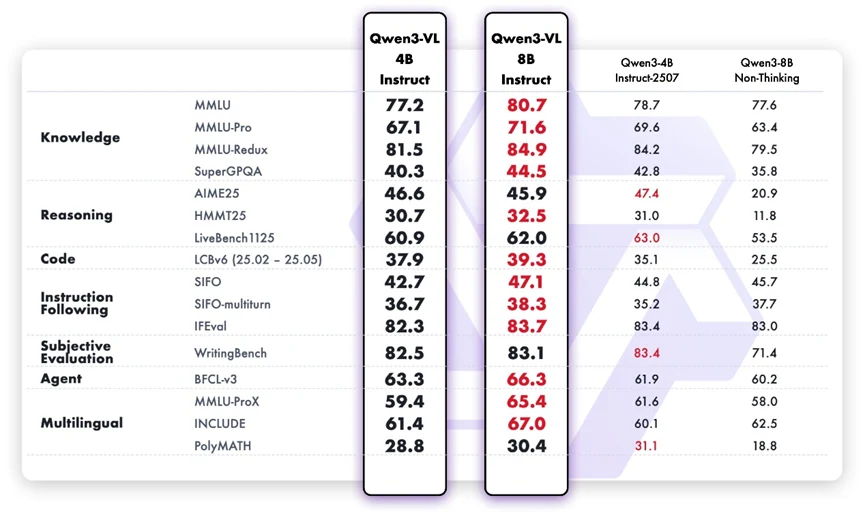
Хотя Qwen3-VL-8B-Instruct разработан как мультимодальная модель, он демонстрирует высокую лингвистическую производительность на задачах с чистым текстом. По сравнению с 4B-версией, у него есть явные улучшения в фактических знаниях, логическом рассуждении, способностях к программированию и обработке многоходовых задач. Он точнее следует намерениям пользователя, сохраняет связность в более длинных диалогах и демонстрирует более надежное суждение в субъективных задачах, таких как выравнивание предпочтений. Его многоязычные улучшения также означают лучшую инклюзивность для глобальных сценариев использования.
Сценарии использования Qwen3-VL-8B-Instruct
Корпоративный копилот для управления знаниями
Помогает сотрудникам извлекать политики, спецификации продуктов и операционные процедуры из больших репозиториев документов. Автоматически извлекает ключевые моменты и генерирует резюме для поддержки принятия решений в отделах compliance, финансов и технических подразделениях.
Автоматизированная работа с приложениями и навигация по интерфейсу
Использует визуальное понимание для взаимодействия с интерфейсами ПК или мобильных устройств — открытия приложений, отправки форм или навигации по меню. Идеально подходит для замены или расширения традиционных RPA в повторяющихся офисных или операционных рабочих процессах.
Просмотр видео и извлечение событий
Анализирует длинные записи, такие как совещания, учебные занятия и потоки видеонаблюдения. Обнаруживает ключевые моменты, помечает сегменты и предоставляет поиск по временной шкале для эффективного просмотра контента.
Обработка бизнес-документов
Оцифровывает и структурирует счета, квитанции, контракты и логистические документы, полученные в реальных условиях. Извлекает обязательные поля с учетом макета документа для оптимизации процессов финансового аудита и онбординга.
Поддержка клиентов с визуальной помощью
Понимает скриншоты и фотографии устройств от пользователей для диагностики проблем с входом в систему, ошибок конфигурации или несоответствий продуктов. Предоставляет пошаговые инструкции для улучшения удаленного устранения неполадок и эффективности обслуживания.
Пространственный ИИ для робототехники и AR-устройств
Интерпретирует 2D и 3D среды для навигации и взаимодействия с объектами. Применимо к складским роботам, домашним сервисным агентам и навигации с помощью дополненной реальности в сложных пространствах.
Производительность при преобразовании дизайна в код
Преобразует скриншоты пользовательских интерфейсов или эскизы в прототипы фронтенд-кода. Ускоряет передачу работ между дизайнерскими и инженерными командами при разработке цифровых продуктов.
Как получить доступ к Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct теперь доступен на Novita AI по цене $0.08 за 1M входных токенов и $0.50 за 1M выходных токенов.
Используйте песочницу (не требуется написание кода)
Зарегистрируйтесь и начните экспериментировать с Qwen3-VL-8B-Instruct за несколько секунд через интерактивный интерфейс. Тестируйте промпты, просматривайте выводы в реальном времени с полным контекстным окном 200K и сравнивайте GLM-4.6 с другими ведущими моделями. Идеально подходит для прототипирования и понимания возможностей модели перед созданием полноценных реализаций.
Интеграция через API (для разработчиков)
Подключите Qwen3-VL-8B-Instruct к вашим приложениям с помощью унифицированного REST API Novita AI.
Вариант 1: Прямая интеграция через API (пример на Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Вариант 2: Многоагентные рабочие процессы с OpenAI Agents SDK
Создавайте сложные многоагентные системы, используя продвинутые возможности парсинга документов Qwen3-VL-8B-Instruct:
- Интеграция из коробки: Используйте Qwen3-VL-8B-Instruct в любом рабочем процессе OpenAI Agents
- Продвинутые возможности агентов: Поддержка передачи задач, маршрутизации и интеграции инструментов с возможностью понимания документов
- Масштабируемая архитектура: Проектируйте агентов, которые используют многоязычные возможности OCR и распознавания элементов Qwen3-VL-8B-Instruct
Вариант 3: Подключение к сторонним платформам
Инструменты для разработки: Бесшовно интегрируйтесь с популярными IDE и средами разработки, такими как Cursor, Trae и Cline, через API, совместимые с OpenAI, и API, совместимые с Anthropic.
Оркестрационные фреймворки: Подключайтесь к LangChain, Dify, CrewAI, Langflow и другим платформам для оркестрации ИИ с помощью официальных коннекторов.
Интеграция с Hugging Face: Novita AI является официальным провайдером инференса Hugging Face, что обеспечивает широкую совместимость с экосистемой.
Что такое Qwen3-VL-8B?
Qwen3-VL-8B — это компактная мультимодальная модель, которая понимает и обрабатывает как текстовую, так и визуальную информацию, поддерживая анализ, рассуждение и выполнение задач, управляемое агентом.
Как Qwen3-VL-8B обрабатывает мультимодальные входные данные?
Она может обрабатывать изображения, скриншоты, видео и документы, сочетая их с текстовыми инструкциями для получения связных и применимых на практике выводов.
Что отличает Qwen3-VL-8B от стандартных LLM?
Она не только понимает информацию, но и может взаимодействовать с пользовательскими интерфейсами и визуальными данными реального мира, что делает ее подходящей для интеллектуальной автоматизации и воплощенного ИИ.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, бессерверные вычисления, GPU-инстансы — доступные инструменты, которые вам нужны. Избавьтесь от необходимости управления инфраструктурой, начните бесплатно и воплотите ваше видение ИИ в реальность.



