

Qwen3-VL-8B-Instruct est désormais disponible sur Novita AI, proposant les capacités vision-langage les plus avancées de la gamme Qwen à ce jour. Cette nouvelle version apporte des améliorations majeures sur tous les plans : compréhension et génération de texte plus précises, raisonnement visuel plus riche, gestion de contexte étendue, meilleure compréhension spatiale et vidéo, et interactions de niveau agent plus performantes. Disponible en variantes Dense et MoE pouvant passer des appareils edge aux environnements cloud, ainsi qu’en éditions Instruct et Thinking axées sur le raisonnement pour un déploiement adaptable à la demande.
Il surpasse les alternatives grand public, rivalise avec les meilleurs modèles VLM et conserve des performances d’inférence rapides adaptées aux applications concrètes.
Essayer la démo de Qwen3-VL-8B-Instruct
Qu’est-ce que Qwen3-VL-8B-Instruct ?
Qwen3-VL-8B-Instruct est un modèle vision-langage de pointe conçu pour comprendre les images et le texte de manière holistique. Basé sur la dernière architecture Qwen3, il offre un raisonnement multimodale performant, un ancrage visuel précis et une génération de langage naturel dans un format léger de 8 milliards de paramètres. Par rapport aux versions précédentes, la variante Instruct a été optimisée pour l’utilisation concrète : elle prend en charge un suivi des instructions plus précis, une meilleure compréhension contextuelle et une inférence plus rapide dans des environnements de déploiement variés. Ces améliorations le rendent parfaitement adapté à des applications allant de la compréhension d’images et de l’analyse de documents aux agents multimodaux et aux systèmes d’IA interactifs.
Améliorations clés
- Capacités d’agent visuel : Interagit avec les interfaces PC et mobiles : identifie les composants d’interface, interprète leurs fonctions, déclenche des outils et exécute des tâches de bout en bout.
- Accélération visuelle-vers-code : Convertit des images ou des images vidéo en diagrammes Draw.io, HTML, CSS ou JavaScript.
- Intelligence spatiale supérieure : Évalue les relations entre objets, les points de vue et les occlusions ; offre un ancrage 2D plus solide et prend en charge la compréhension 3D pour le raisonnement spatial et l’IA incarnée.
- Contexte étendu et compréhension vidéo : Contexte natif de 256K extensible à 1M, permettant le traitement de documents complets et l’analyse de vidéos de plusieurs heures avec une navigation temporelle précise.
- Raisonnement multimodale avancé : Particulièrement performant dans les domaines STEM et mathématiques : prend en charge l’interprétation causale et des réponses logiquement fondées sur des preuves.
- Reconnaissance visuelle améliorée : Un entraînement étendu et de meilleure qualité permet une reconnaissance large : des célébrités et de l’anime aux produits de grande consommation, en passant par les monuments, les plantes et les animaux.
- OCR plus performant : Prend désormais en charge 32 langues (contre 19 auparavant) ; fonctionne bien même avec du texte flou, en faible luminosité ou incliné ; gère mieux les écritures rares/anciennes, les termes spécialisés et la structure des documents longs.
- Compréhension de texte comparable à celle des LLM purs : Permet une intégration transparente du texte et de la vision pour une compréhension totalement unifiée sans perte d’information.
Architecture du modèle
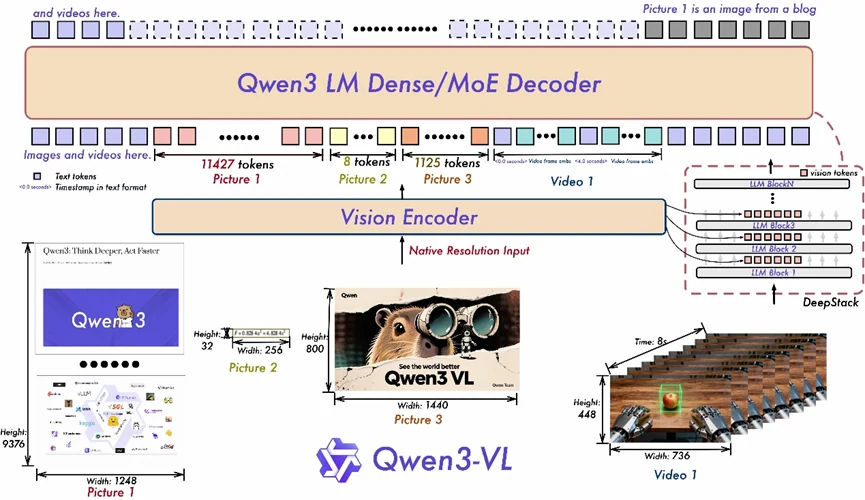
- Interleaved-MRoPE : Utilise un encodage positionnel complet sur les dimensions temporelles et spatiales (temps, largeur, hauteur), améliorant le raisonnement vidéo à longue portée.
- DeepStack : Intègre des représentations ViT multicouches pour préserver les détails fins et renforcer l’alignement entre le contenu visuel et le texte.
- Alignement texte-horodatage : Va au-delà de T-RoPE en ancrant les événements à des horodatages précis, améliorant considérablement la compréhension temporelle dans les vidéos.
Performances du modèle Qwen3-VL-8B-Instruct
Performances multimodales
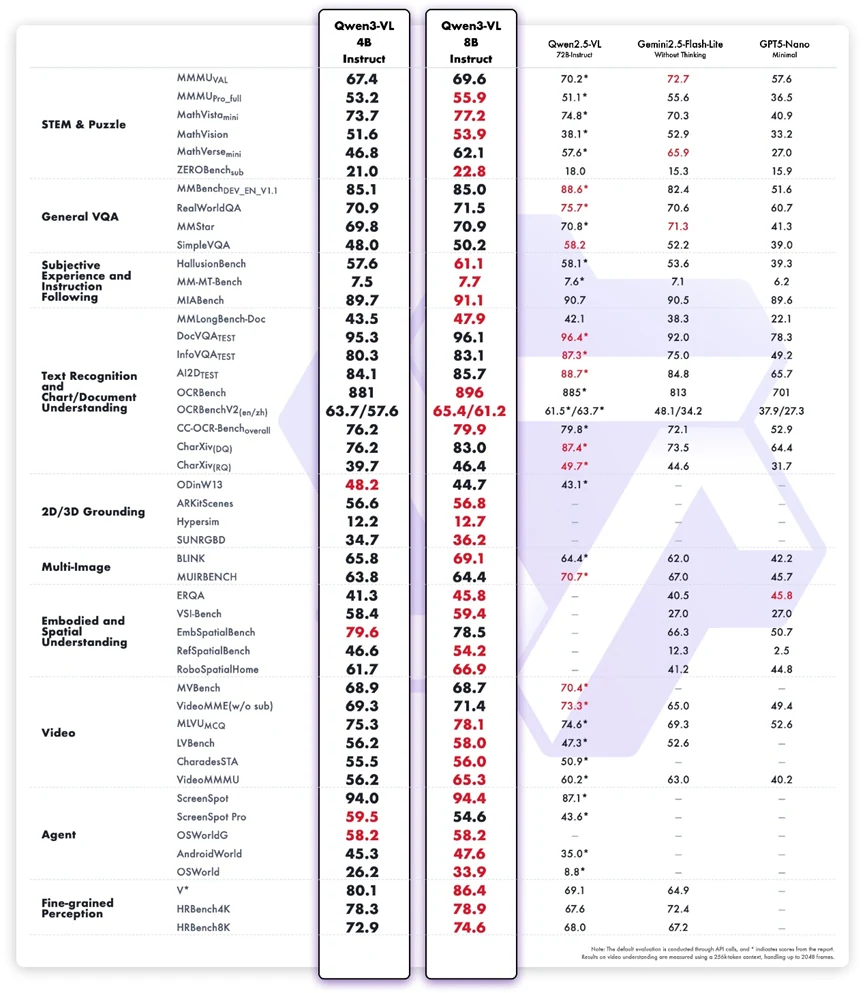
Les résultats des benchmarks montrent que Qwen3-VL-8B-Instruct offre des performances multimodales équilibrées, d’autant plus compte tenu de sa taille compacte. Il présente des forces notables dans le raisonnement STEM, la compréhension de documents visuels et le suivi d’instructions multimodales, surpassant clairement sa version 4B et obtenant des scores compétitifs par rapport à des systèmes plus grands ou propriétaires. Des tâches telles que MathVista, InfoVQA Test, A12Dataset, RobospatialHome et ScreenSpot mettent en évidence sa capacité à combiner le raisonnement textuel et visuel pour des flux de travail concrets. Ses bons résultats sur les benchmarks liés aux agents reflètent également un ancrage solide entre perception et action.
Performances sur texte pur
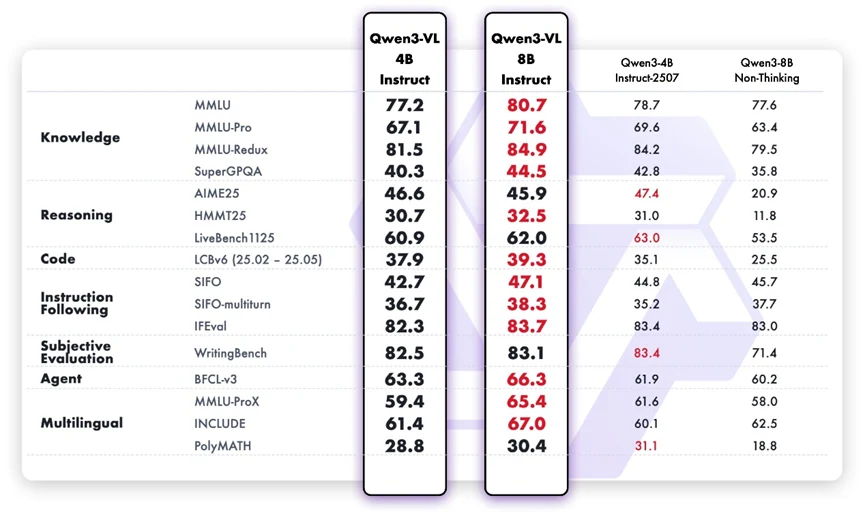
Bien qu’il soit conçu comme un modèle multimodal, Qwen3-VL-8B-Instruct fait preuve de solides compétences linguistiques sur des tâches de texte pur. Par rapport à la version 4B, il présente des gains clairs en connaissances factuelles, raisonnement logique, capacité de codage et gestion de tâches multi-tours. Il suit les intentions des utilisateurs plus précisément, maintient la cohérence dans des conversations plus longues et fait preuve d’un jugement plus fiable sur des tâches subjectives telles que l’alignement des préférences. Son amélioration multilingue signifie également une meilleure inclusivité pour des scénarios d’utilisation mondiaux.
Cas d’usage de Qwen3-VL-8B-Instruct
Copilote de connaissances d’entreprise
Aide les employés à retrouver des politiques, des spécifications de produits et des procédures opérationnelles dans de grands référentiels de documents. Extrait automatiquement les points clés et génère des résumés pour soutenir la prise de décision dans les services de conformité, financiers et techniques.
Opération automatisée d’applications et navigation dans l’interface utilisateur
Utilise la compréhension visuelle pour interagir avec des interfaces PC ou mobiles : ouvrir des applications, soumettre des formulaires ou naviguer dans les menus. Idéal pour remplacer ou étendre les RPA traditionnels dans les flux de travail bureautiques ou opérationnels répétitifs.
Révision de vidéos et extraction d’événements
Analyse des enregistrements longs tels que des réunions, des sessions de classe ou des flux de surveillance. Détecte les moments clés, étiquette les segments et propose une recherche basée sur la chronologie pour une révision efficace du contenu.
Traitement de documents d’entreprise
Numérise et structure des factures, des reçus, des contrats et des documents logistiques capturés dans des conditions réelles. Extrait les champs essentiels avec une conscience de la mise en page pour rationaliser les flux d’audit financier et d’intégration.
Assistance client avec aide visuelle
Comprend les captures d’écran et les photos d’appareils envoyées par les utilisateurs pour diagnostiquer des problèmes de connexion, des erreurs de configuration ou des incompatibilités de produits. Fournit des instructions étape par étape pour améliorer le dépannage à distance et l’efficacité du service.
IA spatiale pour la robotique et les appareils AR
Interprète des environnements 2D et 3D pour la navigation et l’interaction avec des objets. Applicable aux robots d’entrepôt, aux agents de service à domicile et aux guidages en réalité augmentée dans des espaces complexes.
Productivité de la conception au code
Convertit des captures d’écran d’interface ou des croquis en prototypes de code front-end. Accélère le transfert entre les équipes de design et d’ingénierie dans le développement de produits numériques.
Comment accéder à Qwen3-VL-8B-Instruct ?
Qwen3-VL-8B-Instruct est désormais disponible sur Novita AI au prix de 0,08 $ par million de tokens d’entrée et 0,50 $ par million de tokens de sortie.
Utiliser le playground (aucun code requis)
Inscrivez-vous et commencez à expérimenter avec Qwen3-VL-8B-Instruct en quelques secondes via une interface interactive. Testez des prompts, visualisez les résultats en temps réel avec la fenêtre de contexte complète de 200K et comparez GLM-4.6 avec d’autres modèles de pointe. Parfait pour le prototypage et la compréhension des capacités du modèle avant de construire des implémentations complètes.
Intégration via l’API (pour les développeurs)
Connectez Qwen3-VL-8B-Instruct à vos applications en utilisant l’API REST unifiée de Novita AI.
Option 1 : Intégration API directe (exemple Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2 : Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents sophistiqués en tirant parti des capacités avancées d’analyse de documents de Qwen3-VL-8B-Instruct :
- Intégration plug-and-play : Utilisez Qwen3-VL-8B-Instruct dans tout flux de travail OpenAI Agents
- Capacités d’agent avancées : Prise en charge des transferts, du routage et de l’intégration d’outils avec compréhension de documents
- Architecture évolutive : Concevez des agents qui tirent parti des capacités OCR multilingue et de reconnaissance d’éléments de Qwen3-VL-8B-Instruct
Option 3 : Connexion avec des plateformes tierces
Outils de développement : Intégrez-vous de manière transparente avec des IDE et environnements de développement populaires comme Cursor, Trae et Cline via des API compatibles OpenAI et des API compatibles Anthropic.
Frameworks d’orchestration : Connectez-vous avec LangChain, Dify, CrewAI, Langflow et d’autres plateformes d’orchestration d’IA en utilisant des connecteurs officiels.
Intégration Hugging Face : Novita AI est un fournisseur d’inférence officiel de Hugging Face, garantissant une compatibilité large avec l’écosystème.
Qu’est-ce que Qwen3-VL-8B ?
Qwen3-VL-8B est un modèle multimodal compact qui comprend et traite à la fois des informations textuelles et visuelles, prenant en charge l’analyse, le raisonnement et l’exécution de tâches pilotées par des agents.
Comment Qwen3-VL-8B gère-t-il les entrées multimodales ?
Il peut traiter des images, des captures d’écran, des vidéos et des documents tout en les combinant avec des instructions textuelles pour produire des résultats cohérents et exploitables.
Qu’est-ce qui distingue Qwen3-VL-8B des LLM standards ?
Il ne se contente pas de comprendre les informations, mais peut également interagir avec les interfaces utilisateur et les visuels du monde réel, ce qui le rend adapté à l’automatisation intelligente et à l’IA incarnée.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en IA. API intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez les problèmes d’infrastructure, commencez gratuitement et concrétisez votre vision de l’IA.



