

Qwen3-VL-235B-A22B ist jetzt auf der Novita AI-Plattform verfügbar und bringt das leistungsstärkste Vision-Language-Modell der Qwen-Reihe über unsere optimierte Infrastruktur zu Entwicklern. Diese Generation bietet umfassende Upgrades in allen Bereichen: überlegenes Textverständnis und -generierung, tiefere visuelle Wahrnehmung und Schlussfolgerung, erweiterte Kontextlänge, verbessertes Verständnis von räumlichen und Video-Dynamiken sowie stärkere Agenten-Interaktionsfähigkeiten.
Sowohl in der Instruct- als auch der schlussfolgerungsoptimierten Thinking-Edition verfügbar, bietet Qwen3-VL-235B-A22B flexible, bedarfsgesteuerte Bereitstellung für vielfältige Anwendungen. Egal, ob Sie visuelle KI-Anwendungen entwickeln, Automatisierungslösungen erstellen oder fortschrittliche multimodale Fähigkeiten erkunden – Qwen3-VL-235B-A22B auf Novita AI bietet Ihnen die benötigten Tools mit entwicklerfreundlicher Integration.
Qwen3-VL-235B-A22B Demo testen
Was ist Qwen3-VL-235B-A22B?
Qwen3-VL-235B-A22B ist das bisher leistungsstärkste Vision-Language-Modell der Qwen-Reihe. Diese Generation bietet umfassende Upgrades in allen Bereichen: überlegenes Textverständnis und -generierung, tiefere visuelle Wahrnehmung und Schlussfolgerung, erweiterte Kontextlänge, verbessertes Verständnis von räumlichen und Video-Dynamiken sowie stärkere Agenten-Interaktionsfähigkeiten.
Verfügbar in Dense- und MoE-Architekturen, die vom Edge- bis zum Cloud-Bereich skalieren, mit Instruct- und schlussfolgerungsoptimierten Thinking-Editionen für flexible, bedarfsgesteuerte Bereitstellung. Das Modell stellt einen bedeutenden Fortschritt in den multimodalen KI-Fähigkeiten dar und kombiniert fortschrittliches visuelles Verständnis mit anspruchsvollen Schlussfolgerungsfähigkeiten.
Beide Varianten nutzen die gleiche Kernarchitektur, sind aber für unterschiedliche Anwendungsfälle optimiert – die Instruct-Edition für direkte Aufgabenabwicklung und interaktive Anwendungen, während die Thinking-Edition erweiterte Schlussfolgerungsfähigkeiten für komplexe Problemlösungsszenarien bietet.
Wichtige Verbesserungen
Visueller Agent: Operiert PC/mobile GUIs – erkennt Elemente, versteht Funktionen, ruft Tools auf, schließt Aufgaben ab. Diese bahnbrechende Fähigkeit ermöglicht es dem Modell, direkt mit grafischen Benutzeroberflächen zu interagieren, sodass komplexe Workflows automatisiert und anspruchsvolle KI-Agenten erstellt werden können, die Softwareanwendungen navigieren und steuern.
Visueller Coding-Boost: Generiert Draw.io/HTML/CSS/JS aus Bildern/Videos. Das Modell kann visuelle Designs und Mockups analysieren, um automatisch den entsprechenden Code zu generieren, was Entwicklungs-Workflows drastisch beschleunigt und KI-gestütztes Coding aus visuellen Eingaben ermöglicht.
Fortschrittliche räumliche Wahrnehmung: Beurteilt Objektpositionen, Blickwinkel und Verdeckungen; bietet stärkere 2D-Verankerung und ermöglicht 3D-Verankerung für räumliche Schlussfolgerung und verkörperte KI. Diese Verbesserung macht das Modell besonders wertvoll für Robotik, autonome Systeme und Anwendungen, die anspruchsvolles räumliches Verständnis erfordern.
Langer Kontext & Video-Verständnis: Natives 256K-Kontext, erweiterbar auf 1M; verarbeitet Bücher und stundenlange Videos mit vollständigem Recall und sekundengenauer Indizierung. Diese Fähigkeit ermöglicht eine umfassende Analyse umfangreicher Dokumente und langer Videoinhalte, während der Kontext über die gesamte Sequenz hinweg beibehalten wird.
Erweiterte multimodale Schlussfolgerung: Glänzt in STEM/Math – Kausalanalyse sowie logische, evidenzbasierte Antworten. Das Modell zeigt überlegene Leistung bei wissenschaftlichen und mathematischen Schlussfolgerungsaufgaben und liefert detaillierte analytische Antworten auf Basis visueller und textueller Informationen.
Aufgewertete visuelle Erkennung: Breiteres, hochwertigeres Vortraining ermöglicht es dem Modell, „alles zu erkennen“ – Prominente, Anime, Produkte, Wahrzeichen, Flora/Fauna usw. Diese umfassende Erkennungsfähigkeit gewährleistet robuste Leistung über diverse visuelle Inhaltsarten und Domänen hinweg.
Erweiterte OCR: Unterstützt 32 Sprachen (vorher 19); robust bei schwachem Licht, Unschärfe und Neigung; besser mit seltenen/antiken Schriftzeichen und Fachjargon; verbesserte Parsing von Langdokumentenstrukturen. Die erweiterten optischen Zeichenerkennungsfähigkeiten machen das Modell hochgradig effektiv für Dokumentverarbeitungs- und Textextraktionsaufgaben.
Textverständnis auf dem Niveau reiner LLMs: Nahtlose Text-Visions-Fusion für verlustfreies, einheitliches Verständnis. Das Modell erreicht Textverarbeitungsfähigkeiten, die mit dedizierten Sprachmodellen vergleichbar sind, und behält gleichzeitig überlegenes multimodales Verständnis bei.
Modellarchitektur-Updates
Interleaved-MRoPE
Interleaved-MRoPE: Vollständige Frequenzzuweisung über Zeit, Breite und Höhe durch robuste Positions-Einbettungen, die die Schlussfolgerung über lange Videozeiträume verbessern. Diese architektonische Innovation verbessert die Fähigkeit des Modells, zeitliche Sequenzen in Videoinhalten zu verarbeiten und zu verstehen, erheblich.
DeepStack Feature Fusion
DeepStack: Führt mehrstufige ViT-Funktionen zusammen, um feinkörnige Details zu erfassen und die Bild-Text-Ausrichtung zu schärfen. Die DeepStack-Architektur gewährleistet eine optimale Integration zwischen visuellen und textuellen Informationen und verbessert die gesamte multimodale Leistung.
Text-Timestamp Alignment
Text–Zeitstempel-Ausrichtung: Geht über T‑RoPE hinaus und ermöglicht präzise, zeitstempelverankerte Ereignislokalisierung für stärkere Video-Zeitmodellierung. Dieser fortschrittliche Ansatz ermöglicht ein genaueres zeitliches Verständnis und eine genauere Ereignislokalisierung in Videoinhalten.
Verfügbare Modellvarianten
Qwen3-VL-235B-A22B-Instruct
Dies ist das Gewichts-Repository für Qwen3-VL-235B-A22B-Instruct. Die Instruct-Variante ist für direkte Aufgabenabwicklung und interaktive Anwendungen optimiert und liefert sofortige Antworten auf Benutzeranfragen und -befehle.
Dieses Modell zeichnet sich in Szenarien aus, die schnelle, genaue Antworten auf multimodale Eingaben erfordern.
Qwen3-VL-235B-A22B-Thinking
Dies ist das Gewichts-Repository für Qwen3-VL-235B-A22B-Thinking. Die Thinking-Variante verfügt über erweiterte Schlussfolgerungsfähigkeiten und ist ideal für komplexe Problemlösungsaufgaben, die detaillierte Analysen und schrittweise Schlussfolgerungen erfordern.
Dieses Modell ist besonders wertvoll für Anwendungen, die tiefgehendes analytisches Denken und umfassende Bewertungen erfordern.
Leistungs-Benchmarks
Qwen3-VL-235B-A22B zeigt in beiden Instruct- und Thinking-Varianten außergewöhnliche Leistung in mehreren Domänen und demonstriert signifikante Verbesserungen in den Vision-Language-Verständnis- und Schlussfolgerungsfähigkeiten.
Thinking-Variantenleistung
Das Qwen3-VL-235B-A22B-Thinking-Modell zeigt hervorragende Ergebnisse in allen Vision-Language-Benchmarks:
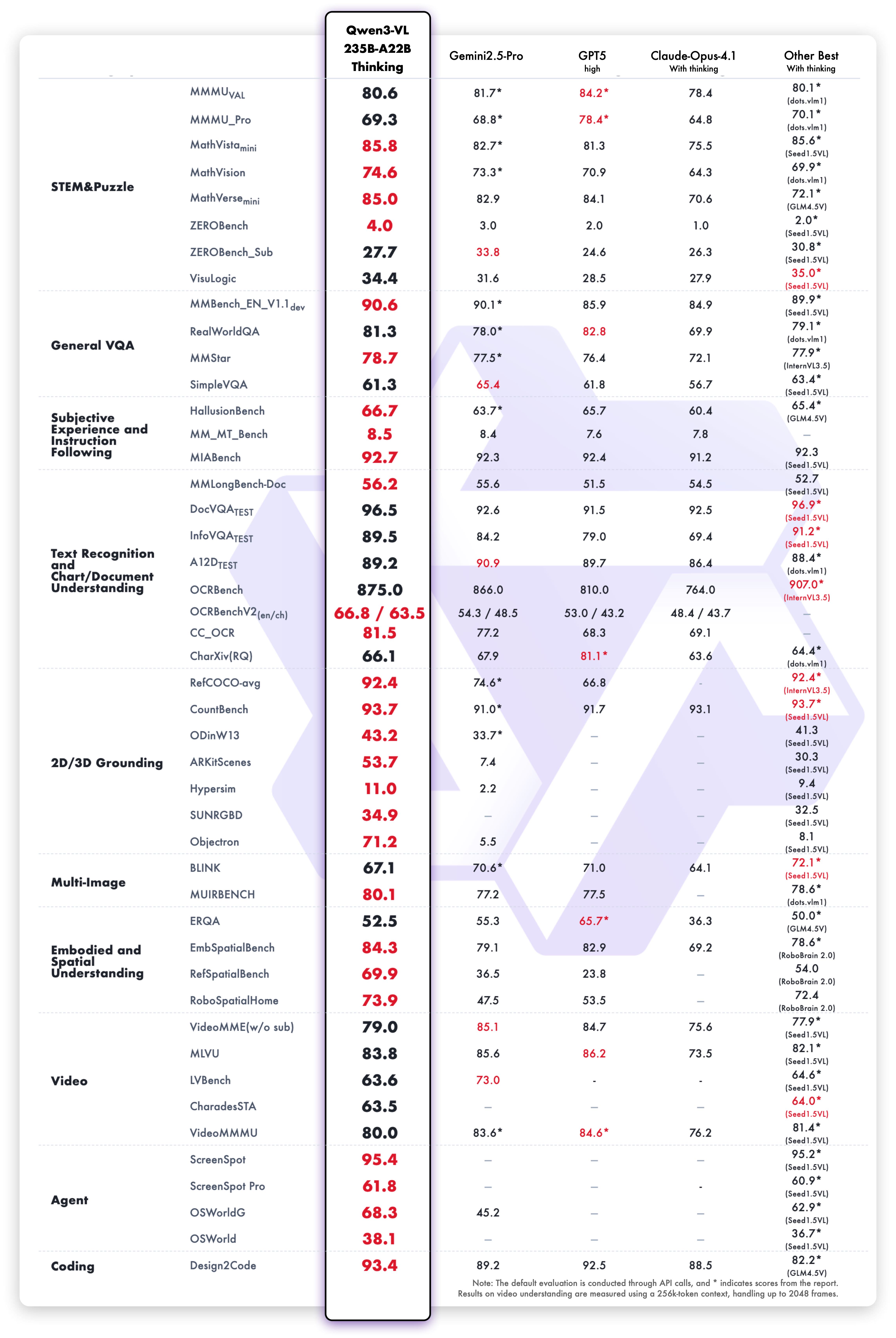
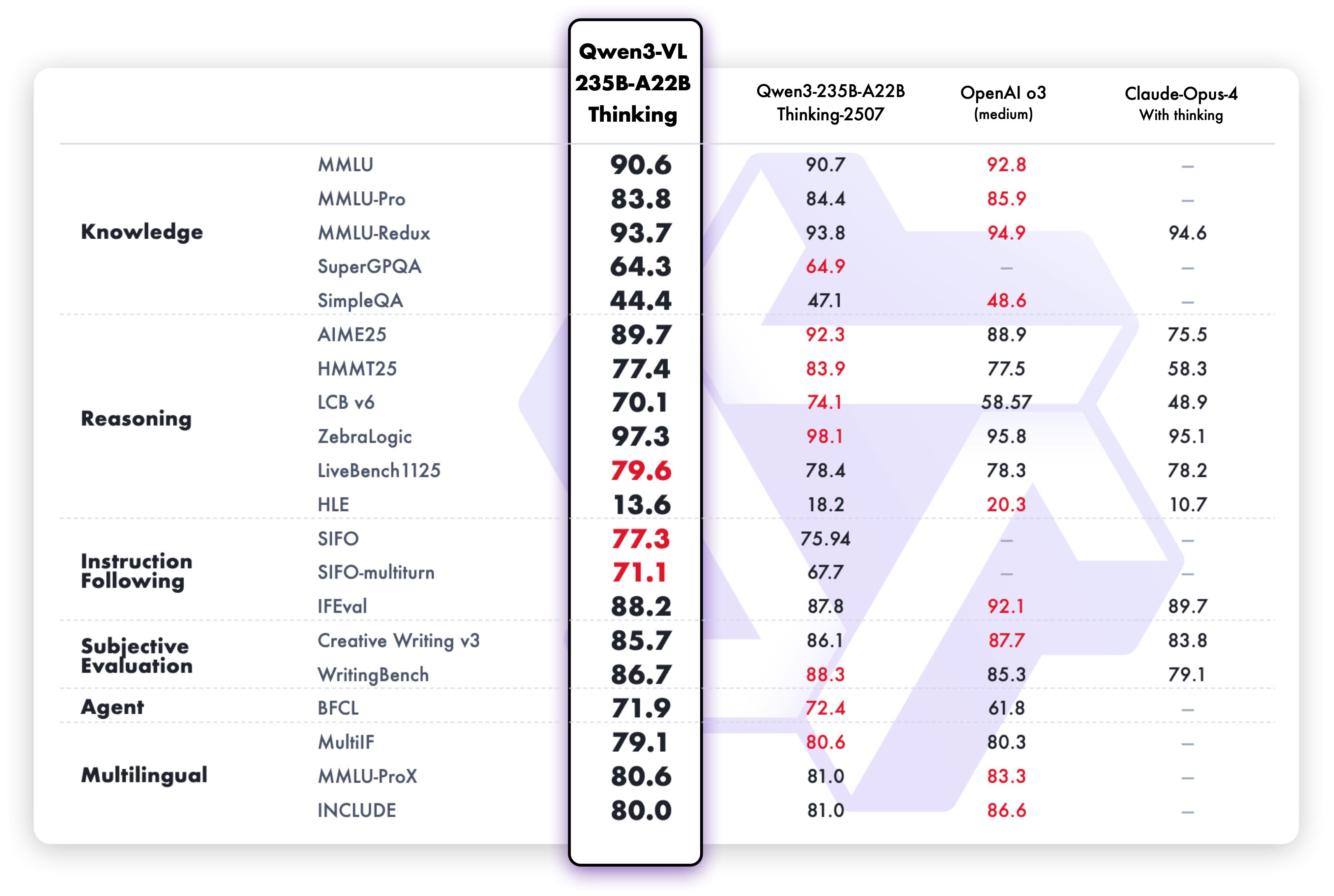
Die Text-Schlussfolgerungsfähigkeiten der Thinking-Variante zeigen überlegene Leistung:
Instruct-Variantenleistung
Das Qwen3-VL-235B-A22B-Instruct-Modell erreicht wettbewerbsfähige Ergebnisse in allen Vision-Language-Bewertungsmetriken:
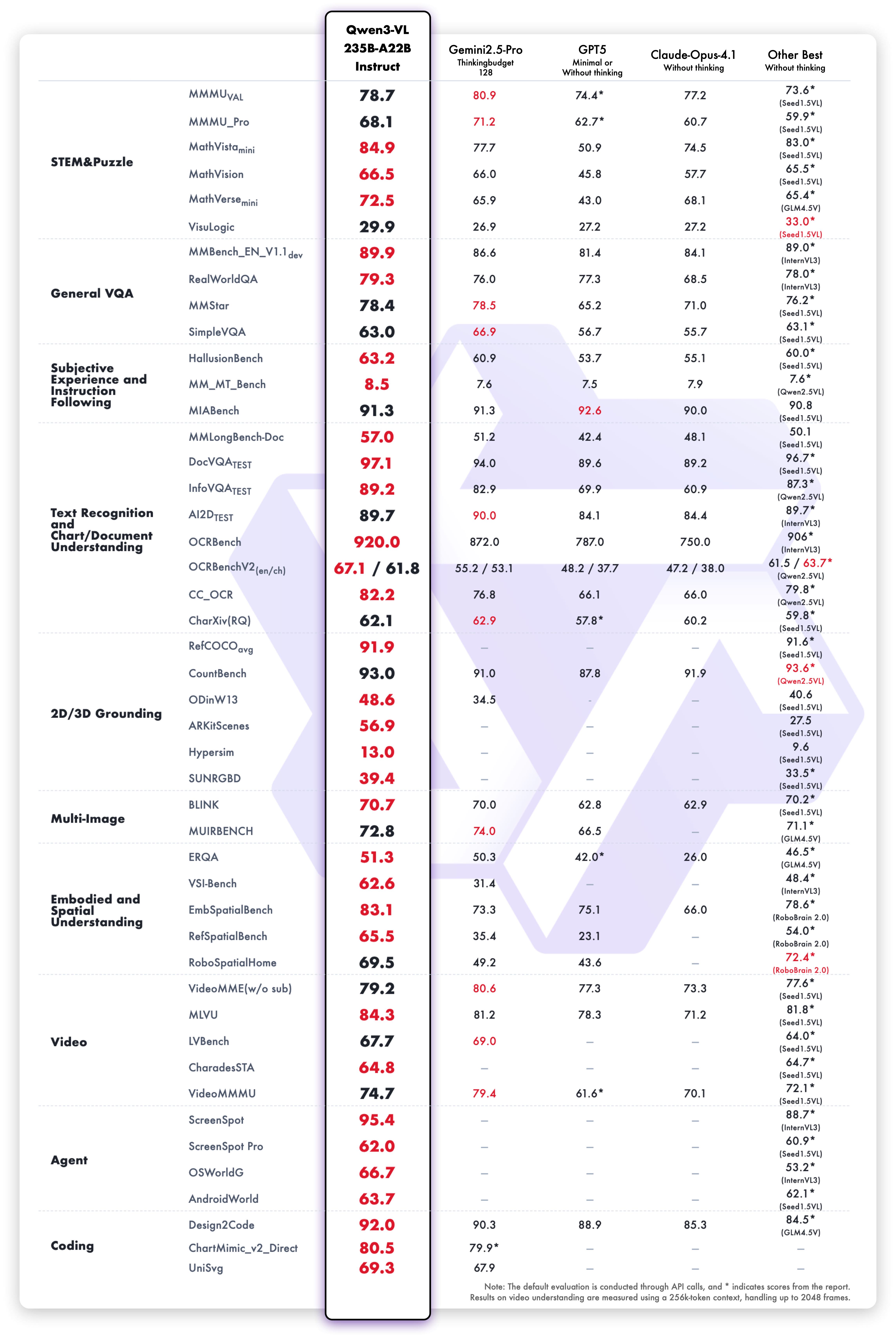
Textverständnis und Generierungsleistung der Instruct-Variante:
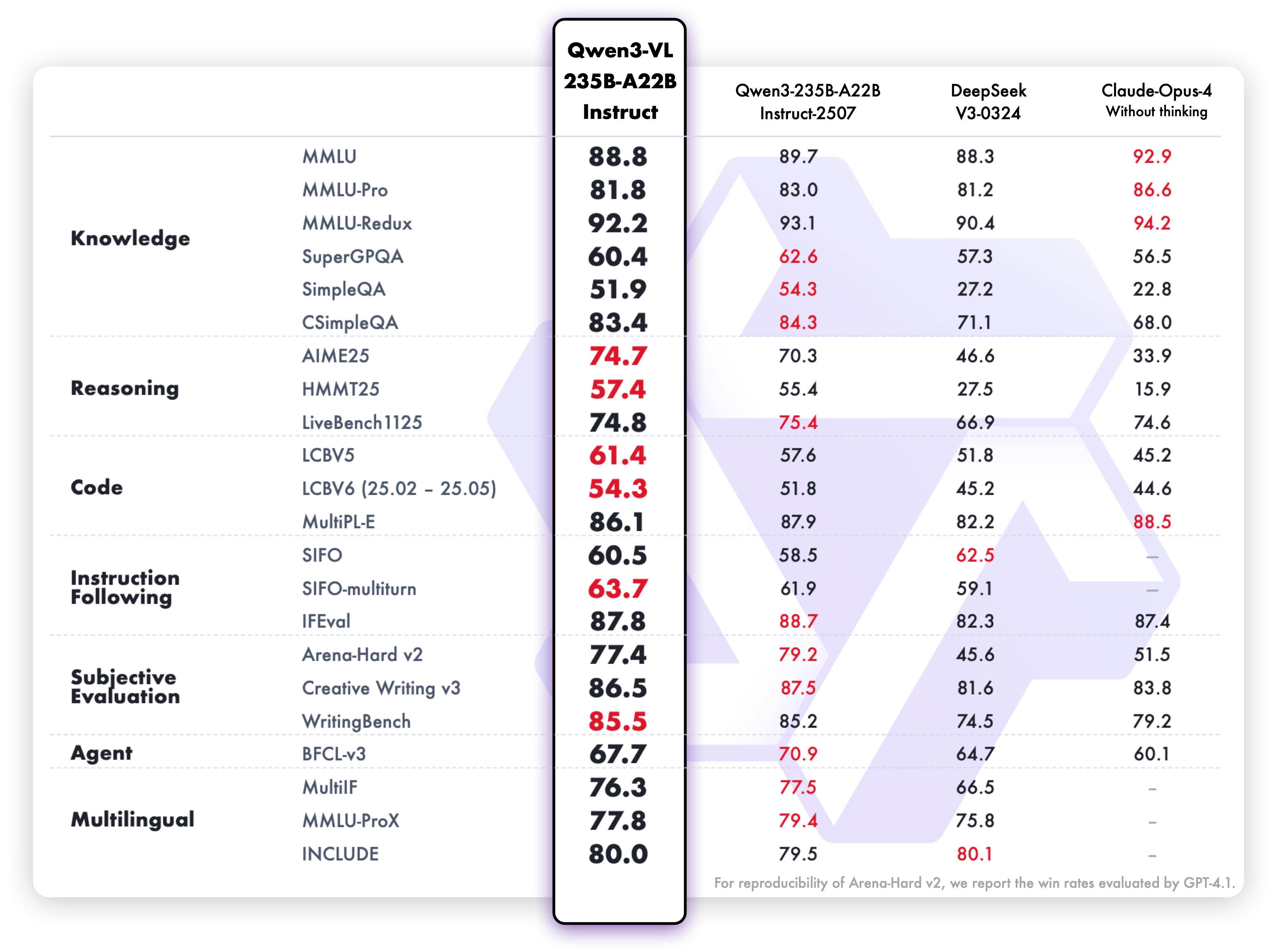
Diese Benchmark-Ergebnisse heben die außergewöhnlichen Fähigkeiten des Modells in multimodalen Verständnis, Schlussfolgerung und Textgenerierung über diverse Bewertungskriterien hinweg hervor. Beide Varianten zeigen starke Leistung in ihren jeweiligen Einsatzbereichen, was sie hochgradig effektiv für die vorgesehenen Anwendungsfälle macht.
Erste Schritte mit Qwen3-VL-235B-A22B auf der Novita AI-Plattform
Der Zugriff auf Qwen3-VL-235B-A22B über Novita AI bietet mehrere Wege, die auf unterschiedliche technische Kenntnisstände und Anwendungsfälle zugeschnitten sind. Egal, ob Sie als Geschäftsanwender KI-Fähigkeiten erkunden oder als Entwickler Produktionsanwendungen erstellen – Novita AI bietet Ihnen die benötigten Tools.
Playground verwenden (Jetzt verfügbar – Kein Coding erforderlich)
- Sofortiger Zugriff: Registrieren Sie sich und beginnen Sie sofort mit dem Experimentieren mit Qwen3-VL-235B-A22B-Modellen in Sekunden
- Interaktive Oberfläche: Testen Sie Prompts und visualisieren Sie Ausgaben in Echtzeit
- Modellvergleich: Vergleichen Sie Qwen3-VL-235B-A22B mit anderen führenden Modellen für Ihren spezifischen Anwendungsfall
Der Playground ermöglicht es Ihnen, verschiedene Prompts zu testen und sofortige Ergebnisse ohne technische Einrichtung zu sehen. Perfekt für Prototyping, das Testen von Ideen und das Verständnis der Modellfähigkeiten vor der vollständigen Implementierung.
Integration über API (Live und verfügbar – Für Entwickler)
Verbinden Sie Qwen3-VL-235B-A22B mit Ihren Anwendungen über Novita AIs einheitliche REST-API.
Option 1: Direkte API-Integration (Python-Beispiel)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2: Multi-Agent-Workflows mit OpenAI Agents SDK
Erstellen Sie anspruchsvolle Multi-Agent-Systeme unter Nutzung der fortschrittlichen Fähigkeiten von Qwen3-VL-235B-A22B:
- Plug-and-Play-Integration: Verwenden Sie Qwen3-VL-235B-A22B in jedem OpenAI Agents-Workflow
- Erweiterte Agenten-Fähigkeiten: Unterstützung für Übergaben, Routing und Tool-Integration mit visuellem Verständnis
- Skalierbare Architektur: Entwerfen Sie Agenten, die die multimodalen Fähigkeiten von Qwen3-VL-235B-A22B nutzen
Option 3: Verbindung mit Drittanbieter-Plattformen
Entwicklungstools: Nahtlose Integration mit beliebten IDEs und Entwicklungsumgebungen wie Cursor, Trae, Qwen Code und Cline über OpenAI-kompatible APIs und Anthropic-kompatible APIs.
Orchestrierungs-Frameworks: Verbinden Sie sich mit LangChain, Dify, CrewAI, Langflow und anderen KI-Orchestrierungsplattformen über offizielle Konnektoren.
Hugging Face Integration: Novita AI ist offizieller Inferenzanbieter von Hugging Face und gewährleistet breite Ökosystemkompatibilität.
Anwendungsfälle und Anwendungen
Entwicklung visueller Agenten
Nutzen Sie die Fähigkeiten visueller Agenten, um Anwendungen zu erstellen, die mit GUIs interagieren, Workflows automatisieren und komplexe Aufgaben durch visuelles Verständnis abschließen können.
Visuelles Coding und Entwicklung
Nutzen Sie die visuelle Coding-Verbesserung, um HTML, CSS, JavaScript und Draw.io-Diagramme aus visuellen Eingaben zu generieren, was Entwicklungs-Workflows beschleunigt.
Dokument- und Videoanalyse
Nutzen Sie die 256K-Kontextlänge und erweiterten OCR-Fähigkeiten für umfassende Dokumentverarbeitung und Videoinhaltsanalyse.
STEM- und Bildungsanwendungen
Wenden Sie die erweiterte multimodale Schlussfolgerung für Bildungstechnologie, wissenschaftliche Analyse und mathematische Problemlösungsanwendungen an.
Räumliche Schlussfolgerungsanwendungen
Implementieren Sie die fortschrittlichen räumlichen Wahrnehmungsfähigkeiten für Robotik, autonome Systeme und Anwendungen, die 3D-Verständnis erfordern.
Fazit
Qwen3-VL-235B-A22B auf Novita AI bietet die heute verfügbaren fortschrittlichsten Vision-Language-Fähigkeiten, wobei sowohl Instruct- als auch Thinking-Varianten flexible Bereitstellungsoptionen für vielfältige Anwendungen bieten. Die umfassenden Verbesserungen in visueller Wahrnehmung, Schlussfolgerung und Agenten-Fähigkeiten, kombiniert mit erweitertem Kontext und überlegenem multimodalem Verständnis, machen dies zur definitiven Wahl für modernste KI-Entwicklung.
Beginnen Sie noch heute mit der Erkundung der revolutionären Fähigkeiten von Qwen3-VL-235B-A22B auf Novita AI und erleben Sie die Zukunft der Vision-Language-KI mit unserer entwicklerfreundlichen Plattform und nahtlosen Integrationsoptionen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Erstellung und Skalierung bereitstellt.



