

Qwen3-VL-235B-A22B ya está disponible en la plataforma Novita AI, llevando a los desarrolladores el modelo de visión y lenguaje más potente de la serie Qwen a través de nuestra infraestructura optimizada. Esta generación incluye mejoras integrales en todos los aspectos: comprensión y generación de texto superiores, percepción y razonamiento visual más profundos, longitud de contexto ampliada, comprensión mejorada de dinámicas espaciales y de video, y capacidades de interacción con agentes más potentes.
Disponible en las ediciones Instruct y Thinking, esta última con capacidades de razonamiento mejoradas, Qwen3-VL-235B-A22B ofrece despliegue flexible bajo demanda para aplicaciones diversas. Tanto si estás desarrollando aplicaciones de IA visual, creando soluciones de automatización o explorando capacidades multimodales avanzadas, Qwen3-VL-235B-A22B en Novita AI te proporciona las herramientas que necesitas con una integración amigable para desarrolladores.
Prueba la demo de Qwen3-VL-235B-A22B
¿Qué es Qwen3-VL-235B-A22B?
Qwen3-VL-235B-A22B es el modelo de visión y lenguaje más potente de la serie Qwen hasta la fecha. Esta generación incluye mejoras integrales en todos los aspectos: comprensión y generación de texto superiores, percepción y razonamiento visual más profundos, longitud de contexto ampliada, comprensión mejorada de dinámicas espaciales y de video, y capacidades de interacción con agentes más potentes.
Disponible en arquitecturas Dense y MoE que escalan desde el borde hasta la nube, con ediciones Instruct y Thinking de razonamiento mejorado para un despliegue flexible bajo demanda. Este modelo supone un avance significativo en las capacidades de IA multimodal, combinando una comprensión visual avanzada con sofisticadas capacidades de razonamiento.
Ambas variantes comparten la misma arquitectura central, pero están optimizadas para casos de uso diferentes: la edición Instruct para la finalización directa de tareas y aplicaciones interactivas, mientras que la edición Thinking proporciona capacidades de razonamiento mejoradas para escenarios de resolución de problemas complejos.
Mejoras clave
Agente visual: Opera interfaces gráficas de usuario (GUI) de PC y móviles: reconoce elementos, comprende sus funciones, invoca herramientas y completa tareas. Esta capacidad innovadora permite al modelo interactuar directamente con interfaces gráficas, haciendo posible automatizar flujos de trabajo complejos y construir agentes de IA sofisticados capaces de navegar y controlar aplicaciones de software.
Aumento de codificación visual: Genera código Draw.io/HTML/CSS/JS a partir de imágenes y videos. El modelo puede analizar diseños y maquetas visuales para generar automáticamente el código correspondiente, acelerando drásticamente los flujos de trabajo de desarrollo y permitiendo la codificación asistida por IA a partir de entradas visuales.
Percepción espacial avanzada: Evalúa posiciones de objetos, puntos de vista y oclusiones; proporciona un anclaje 2D más sólido y permite el anclaje 3D para razonamiento espacial e IA encarnada. Esta mejora hace que el modelo sea especialmente valioso para la robótica, los sistemas autónomos y las aplicaciones que requieren una comprensión espacial sofisticada.
Contexto largo y comprensión de video: Contexto nativo de 256K, ampliable a 1M; procesa libros y videos de varias horas con recuperación completa e indexación a nivel de segundo. Esta capacidad permite el análisis integral de documentos extensos y contenido de video largo, manteniendo el contexto en toda la secuencia.
Razonamiento multimodal mejorado: Destaca en STEM y matemáticas: análisis causal y respuestas lógicas basadas en evidencia. El modelo demuestra un rendimiento superior en tareas de razonamiento científico y matemático, proporcionando respuestas analíticas detalladas basadas en información visual y textual.
Reconocimiento visual mejorado: El preentrenamiento más amplio y de mayor calidad permite “reconocer cualquier cosa”: celebridades, anime, productos, lugares emblemáticos, flora y fauna, etc. Esta capacidad de reconocimiento integral garantiza un rendimiento robusto en diferentes tipos de contenido visual y dominios.
OCR ampliado: Soporta 32 idiomas (frente a los 19 anteriores); es robusto en condiciones de poca luz, desenfoque e inclinación; funciona mejor con caracteres raros o antiguos y jerga especializada; mejora en el análisis de estructura de documentos largos. Las capacidades mejoradas de reconocimiento óptico de caracteres hacen que el modelo sea muy eficaz para tareas de procesamiento de documentos y extracción de texto.
Comprensión de texto equiparable a la de los LLM puros: Fusión perfecta entre texto y visión para una comprensión unificada sin pérdidas. El modelo alcanza capacidades de procesamiento de texto comparables a las de los modelos de lenguaje dedicados, manteniendo al mismo tiempo una comprensión multimodal superior.
Actualizaciones de la arquitectura del modelo
Interleaved-MRoPE
Interleaved-MRoPE: Asignación de frecuencia completa en el tiempo, el ancho y la altura mediante incrustaciones posicionales robustas, mejorando el razonamiento en video de largo horizonte. Esta innovación arquitectónica mejora significativamente la capacidad del modelo para procesar y comprender secuencias temporales en contenido de video.
Fusión de características DeepStack
DeepStack: Fusiona características ViT de múltiples niveles para capturar detalles finos y afinar la alineación entre imagen y texto. La arquitectura DeepStack garantiza una integración óptima entre la información visual y textual, mejorando el rendimiento multimodal general.
Alineación texto-marca de tiempo
Alineación texto-marca de tiempo: Supera la técnica T‑RoPE para lograr una localización de eventos precisa basada en marcas de tiempo, permitiendo un modelado temporal de video más robusto. Este enfoque avanzado permite una comprensión temporal más precisa y la localización de eventos en contenido de video.
Variantes de modelo disponibles
Qwen3-VL-235B-A22B-Instruct
Este es el repositorio de pesos de Qwen3-VL-235B-A22B-Instruct. La variante Instruct está optimizada para la finalización directa de tareas y aplicaciones interactivas, proporcionando respuestas inmediatas a consultas y comandos de los usuarios.
Este modelo destaca en escenarios que requieren respuestas rápidas y precisas a entradas multimodales.
Qwen3-VL-235B-A22B-Thinking
Este es el repositorio de pesos de Qwen3-VL-235B-A22B-Thinking. La variante Thinking incorpora capacidades de razonamiento mejoradas, lo que la hace ideal para tareas de resolución de problemas complejos que requieren análisis detallado y razonamiento paso a paso.
Este modelo es especialmente valioso para aplicaciones que requieren pensamiento analítico profundo y evaluación exhaustiva.
Resultados de rendimiento en pruebas comparativas
Qwen3-VL-235B-A22B demuestra un rendimiento excepcional en múltiples dominios tanto en la variante Instruct como en la Thinking, mostrando mejoras significativas en la comprensión de visión y lenguaje y en las capacidades de razonamiento.
Rendimiento de la variante Thinking
El modelo Qwen3-VL-235B-A22B-Thinking muestra resultados excepcionales en las pruebas comparativas de visión y lenguaje:
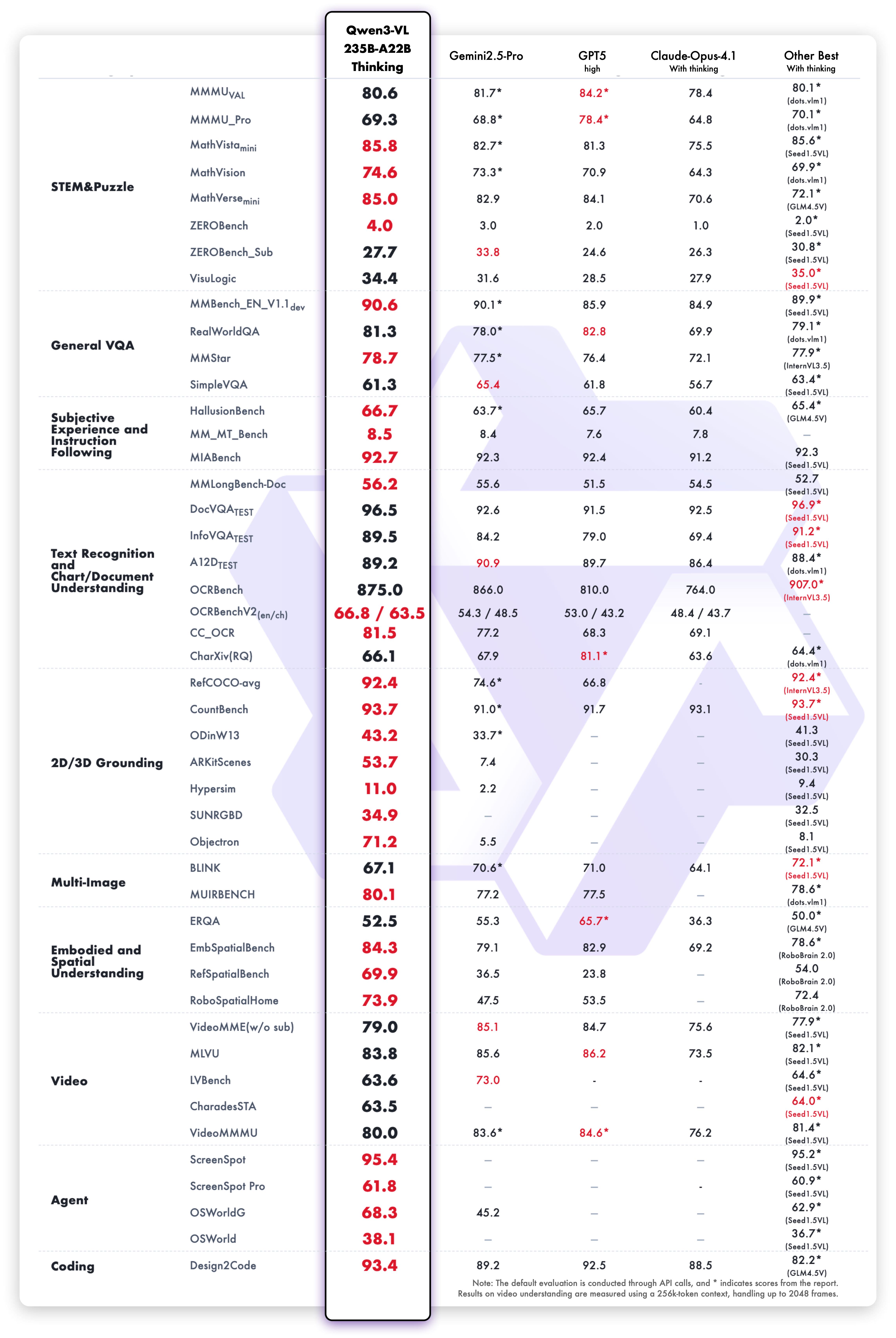
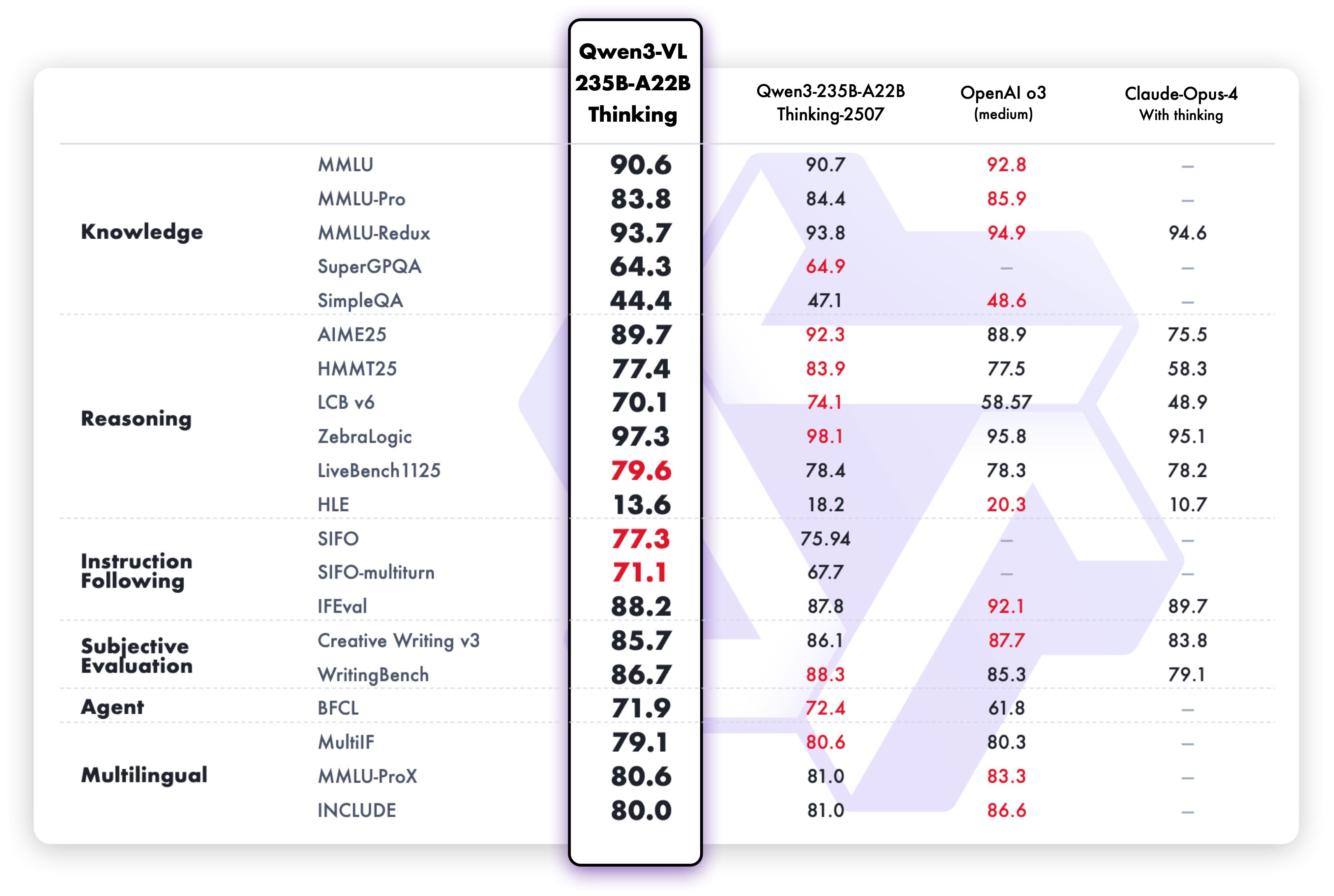
Las capacidades de razonamiento de texto de la variante Thinking demuestran un rendimiento superior:
Rendimiento de la variante Instruct
El modelo Qwen3-VL-235B-A22B-Instruct obtiene resultados competitivos en las métricas de evaluación de visión y lenguaje:
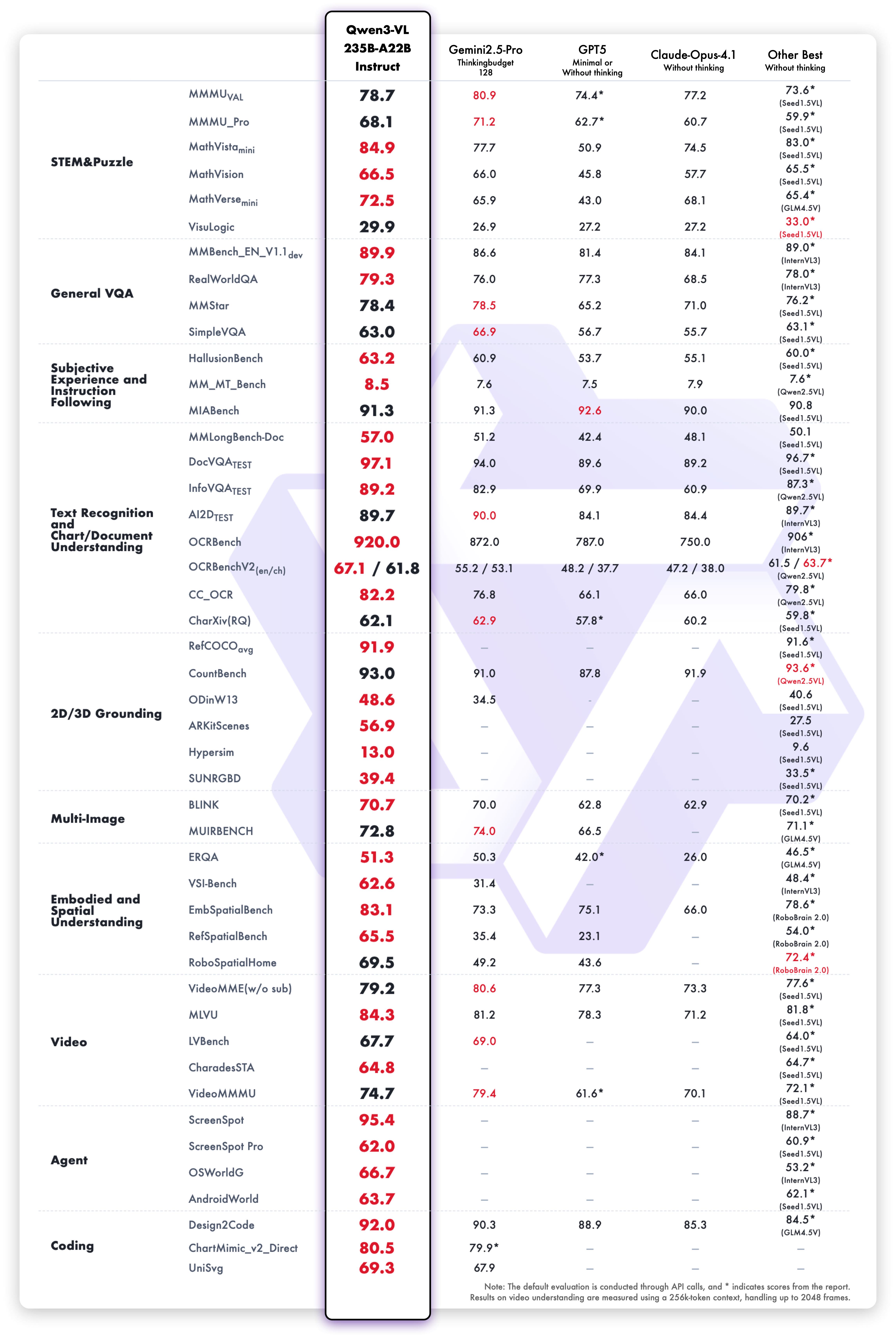
Rendimiento de comprensión y generación de texto de la variante Instruct:
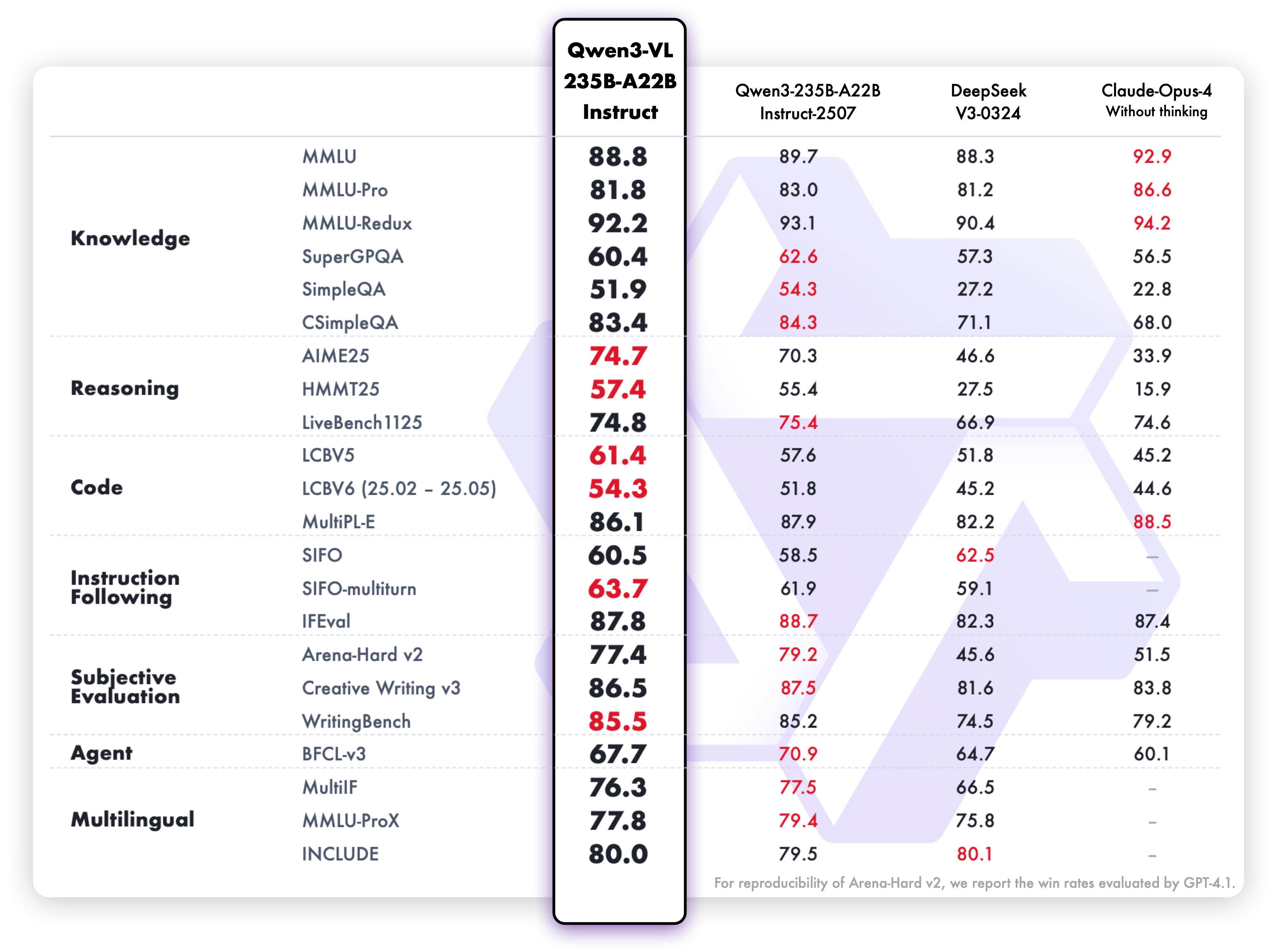
Estos resultados de pruebas comparativas ponen de relieve las capacidades excepcionales del modelo en comprensión multimodal, razonamiento y generación de texto en diferentes criterios de evaluación. Ambas variantes demuestran un rendimiento sólido en sus respectivas áreas, lo que las hace muy eficaces para los casos de uso previstos.
Primeros pasos con Qwen3-VL-235B-A22B en la plataforma Novita AI
Acceder a Qwen3-VL-235B-A22B a través de Novita AI ofrece múltiples vías adaptadas a diferentes niveles de experiencia técnica y casos de uso. Tanto si eres un usuario empresarial que explora las capacidades de la IA como un desarrollador que crea aplicaciones de producción, Novita AI te proporciona las herramientas que necesitas.
Usa el patio de juegos (disponible ahora, no requiere programación)
- Acceso instantáneo: Regístrate y empieza a experimentar con los modelos Qwen3-VL-235B-A22B en segundos
- Interfaz interactiva: Prueba indicaciones y visualiza los resultados en tiempo real
- Comparación de modelos: Compara Qwen3-VL-235B-A22B con otros modelos líderes para tu caso de uso específico
El patio de juegos te permite probar diferentes indicaciones y ver resultados inmediatos sin necesidad de ninguna configuración técnica. Es perfecto para crear prototipos, probar ideas y comprender las capacidades del modelo antes de su implementación completa.
Integración mediante API (disponible y lista para desarrolladores)
Conecta Qwen3-VL-235B-A22B a tus aplicaciones con la API REST unificada de Novita AI.
Opción 1: Integración directa por API (ejemplo en Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Opción 2: Flujos de trabajo multiagente con el SDK de OpenAI Agents
Construye sistemas multiagente sofisticados aprovechando las capacidades avanzadas de Qwen3-VL-235B-A22B:
- Integración conectar y usar: Utiliza Qwen3-VL-235B-A22B en cualquier flujo de trabajo de OpenAI Agents
- Capacidades avanzadas de agentes: Soporte para transferencias, enrutamiento e integración de herramientas con comprensión visual
- Arquitectura escalable: Diseña agentes que aprovechen las capacidades multimodales de Qwen3-VL-235B-A22B
Opción 3: Conéctate con plataformas de terceros
Herramientas de desarrollo: Integra sin problemas con IDE y entornos de desarrollo populares como Cursor, Trae, Qwen Code y Cline mediante APIs compatibles con OpenAI y APIs compatibles con Anthropic.
Frameworks de orquestación: Conéctate con LangChain, Dify, CrewAI, Langflow y otras plataformas de orquestación de IA mediante conectores oficiales.
Integración con Hugging Face: Novita AI actúa como proveedor oficial de inferencia de Hugging Face, garantizando una amplia compatibilidad con el ecosistema.
Casos de uso y aplicaciones
Desarrollo de agentes visuales
Aprovecha las capacidades del agente visual para construir aplicaciones que puedan interactuar con interfaces gráficas, automatizar flujos de trabajo y completar tareas complejas mediante comprensión visual.
Codificación y desarrollo visual
Aprovecha la mejora de codificación visual para generar código HTML, CSS, JavaScript y diagramas de Draw.io a partir de entradas visuales, acelerando los flujos de trabajo de desarrollo.
Análisis de documentos y videos
Aprovecha la longitud de contexto de 256K y las capacidades de OCR mejoradas para un procesamiento integral de documentos y análisis de contenido de video.
Aplicaciones STEM y educativas
Aplica el razonamiento multimodal mejorado para aplicaciones de tecnología educativa, análisis científico y resolución de problemas matemáticos.
Aplicaciones de razonamiento espacial
Implementa las capacidades avanzadas de percepción espacial para la robótica, los sistemas autónomos y las aplicaciones que requieren comprensión 3D.
Conclusión
Qwen3-VL-235B-A22B en Novita AI ofrece las capacidades de visión y lenguaje más avanzadas disponibles en la actualidad, con ambas variantes, Instruct y Thinking, proporcionando opciones de despliegue flexibles para aplicaciones diversas. Las mejoras integrales en percepción visual, razonamiento y capacidades de agente, combinadas con un contexto ampliado y una comprensión multimodal superior, convierten a este modelo en la opción definitiva para el desarrollo de IA de vanguardia.
Empieza a explorar hoy las capacidades revolucionarias de Qwen3-VL-235B-A22B en Novita AI y experimenta el futuro de la IA de visión y lenguaje con nuestra plataforma amigable para desarrolladores y opciones de integración perfectas.
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, además de proporcionar una nube de GPU asequible y fiable para construir y escalar.



