

Qwen3-VL-235B-A22B теперь доступна на платформе Novita AI, предоставляя разработчикам самую мощную модель зрения и языка из серии Qwen через нашу оптимизированную инфраструктуру. Это поколение предлагает комплексные улучшения по всем направлениям: превосходное понимание и генерация текста, более глубокое визуальное восприятие и рассуждение, увеличенная длина контекста, улучшенное понимание пространственных отношений и динамики видео, а также более мощные возможности взаимодействия с агентами.
Доступна в двух редакциях: Instruct и Thinking с улучшенными возможностями рассуждения, Qwen3-VL-235B-A22B предлагает гибкое развертывание по запросу для разнообразных приложений. Независимо от того, разрабатываете ли вы приложения визуального ИИ, создаете решения для автоматизации или изучаете продвинутые мультимодальные возможности, Qwen3-VL-235B-A22B на Novita AI предоставляет все необходимые инструменты с удобной для разработчиков интеграцией.
Попробовать демо-версию Qwen3-VL-235B-A22B
Что такое Qwen3-VL-235B-A22B?
Qwen3-VL-235B-A22B на сегодняшний день является самой мощной моделью зрения и языка в серии Qwen. Это поколение предлагает комплексные улучшения по всем направлениям: превосходное понимание и генерация текста, более глубокое визуальное восприятие и рассуждение, увеличенная длина контекста, улучшенное понимание пространственных отношений и динамики видео, а также более мощные возможности взаимодействия с агентами.
Доступна в архитектурах Dense и MoE, которые масштабируются от периферийных устройств до облака, с редакциями Instruct и Thinking с улучшенными возможностями рассуждения для гибкого развертывания по запросу. Модель представляет собой значительный прорыв в возможностях мультимодального ИИ, сочетая продвинутое визуальное понимание с сложными способностями к рассуждению.
Оба варианта используют одну и ту же базовую архитектуру, но оптимизированы для разных сценариев использования: редакция Instruct предназначена для прямого выполнения задач и интерактивных приложений, а редакция Thinking предоставляет улучшенные возможности рассуждения для сложных сценариев решения проблем.
Ключевые улучшения
Визуальный агент: Работает с графическими интерфейсами ПК/мобильных устройств — распознает элементы, понимает их функции, вызывает инструменты, выполняет задачи. Эта прорывная возможность позволяет модели напрямую взаимодействовать с графическими пользовательскими интерфейсами, что делает возможной автоматизацию сложных рабочих процессов и создание сложных ИИ-агентов, способных перемещаться по и управлять программными приложениями.
Улучшение визуального кодирования: Генерирует код Draw.io/HTML/CSS/JS на основе изображений и видео. Модель может анализировать визуальные дизайны и макеты для автоматической генерации соответствующего кода, что значительно ускоряет рабочие процессы разработки и позволяет выполнять кодирование с помощью ИИ на основе визуальных входных данных.
Продвинутое пространственное восприятие: Определяет положение объектов, точки обзора и перекрытия; обеспечивает более надежную привязку к 2D-пространству и позволяет выполнять привязку к 3D-пространству для пространственного рассуждения и воплощенного ИИ. Это улучшение делает модель особенно ценной для робототехники, автономных систем и приложений, требующих сложного пространственного понимания.
Длинный контекст и понимание видео: Нативный контекст 256K, расширяемый до 1M; обрабатывает книги и видео продолжительностью в несколько часов с полным воспроизведением информации и индексацией на уровне секунд. Эта возможность позволяет проводить комплексный анализ больших документов и длинного видеоконтента, сохраняя контекст на протяжении всей последовательности.
Улучшенное мультимодальное рассуждение: Превосходно справляется с задачами в области STEM/математики — причинный анализ и логические, основанные на доказательствах ответы. Модель демонстрирует превосходную производительность в задачах научного и математического рассуждения, предоставляя детальные аналитические ответы на основе визуальной и текстовой информации.
Обновленное визуальное распознавание: Более широкое и качественное предобучение позволяет «распознавать все» — знаменитостей, аниме, товары, достопримечательности, флору/фауну и т.д. Эта всеобъемлющая возможность распознавания обеспечивает стабильную производительность на различных типах визуального контента и в разных доменах.
Расширенный OCR: Поддерживает 32 языка (по сравнению с 19 ранее); устойчив к низкой освещенности, размытию и наклону; лучше работает с редкими/древними символами и профессиональной терминологией; улучшенный парсинг структуры длинных документов. Улучшенные возможности оптического распознавания символов делают модель чрезвычайно эффективной для задач обработки документов и извлечения текста.
Понимание текста на уровне чистых LLM: Бесшовное слияние текста и зрения для безпотерьного, единого понимания. Модель достигает возможностей обработки текста, сопоставимых с специализированными языковыми моделями, сохраняя при этом превосходное мультимодальное понимание.
Обновления архитектуры модели
Interleaved-MRoPE
Interleaved-MRoPE: Полное распределение частот по времени, ширине и высоте с помощью надежных позиционных эмбеддингов, что улучшает рассуждение о длительных видеопоследовательностях. Это архитектурное нововведение значительно повышает способность модели обрабатывать и понимать временные последовательности в видеоконтенте.
DeepStack Feature Fusion
DeepStack: Объединяет многоуровневые признаки ViT для захвата детализированных данных и улучшения выравнивания изображения и текста. Архитектура DeepStack обеспечивает оптимальную интеграцию визуальной и текстовой информации, повышая общую мультимодальную производительность.
Text-Timestamp Alignment
Выравнивание текста и временных меток: Выходит за рамки T‑RoPE, обеспечивая точную локализацию событий, привязанную к временным меткам, для более надежного моделирования временных характеристик видео. Этот продвинутый подход позволяет более точно понимать временные отношения и локализовать события в видеоконтенте.
Доступные варианты моделей
Qwen3-VL-235B-A22B-Instruct
Это репозиторий весов для Qwen3-VL-235B-A22B-Instruct. Вариант Instruct оптимизирован для прямого выполнения задач и интерактивных приложений, предоставляя мгновенные ответы на пользовательские запросы и команды.
Эта модель превосходно справляется в сценариях, требующих быстрых, точных ответов на мультимодальные входные данные.
Qwen3-VL-235B-A22B-Thinking
Это репозиторий весов для Qwen3-VL-235B-A22B-Thinking. Вариант Thinking включает улучшенные возможности рассуждения, что делает его идеальным для сложных задач решения проблем, требующих детального анализа и пошагового рассуждения.
Эта модель особенно ценна для приложений, требующих глубокого аналитического мышления и комплексной оценки.
Бенчмарки производительности
Qwen3-VL-235B-A22B демонстрирует исключительную производительность в нескольких доменах как в варианте Instruct, так и в Thinking, показывая значительные улучшения в понимании зрения и языка и возможностях рассуждения.
Производительность варианта Thinking
Модель Qwen3-VL-235B-A22B-Thinking показывает выдающиеся результаты в бенчмарках зрения и языка:
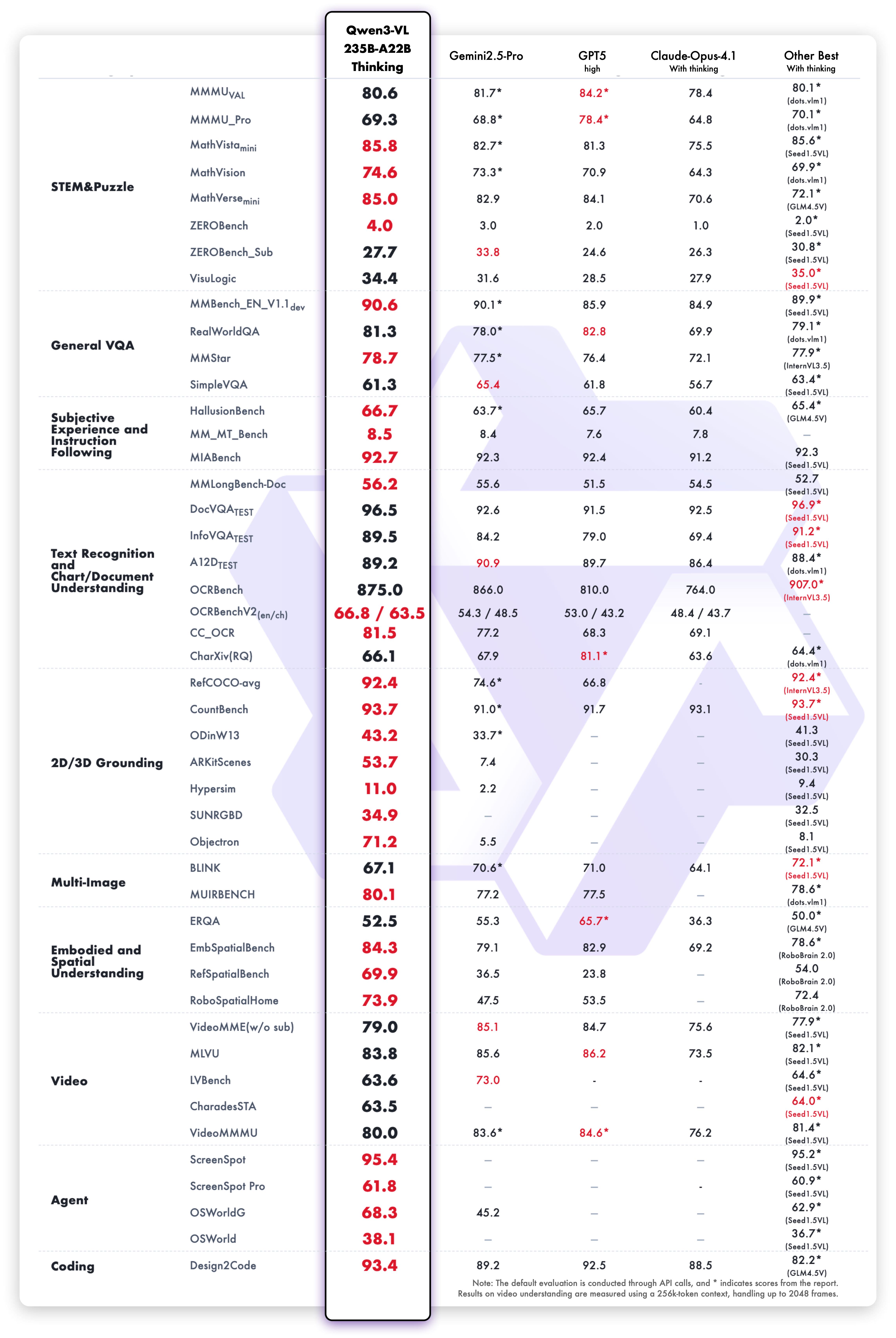
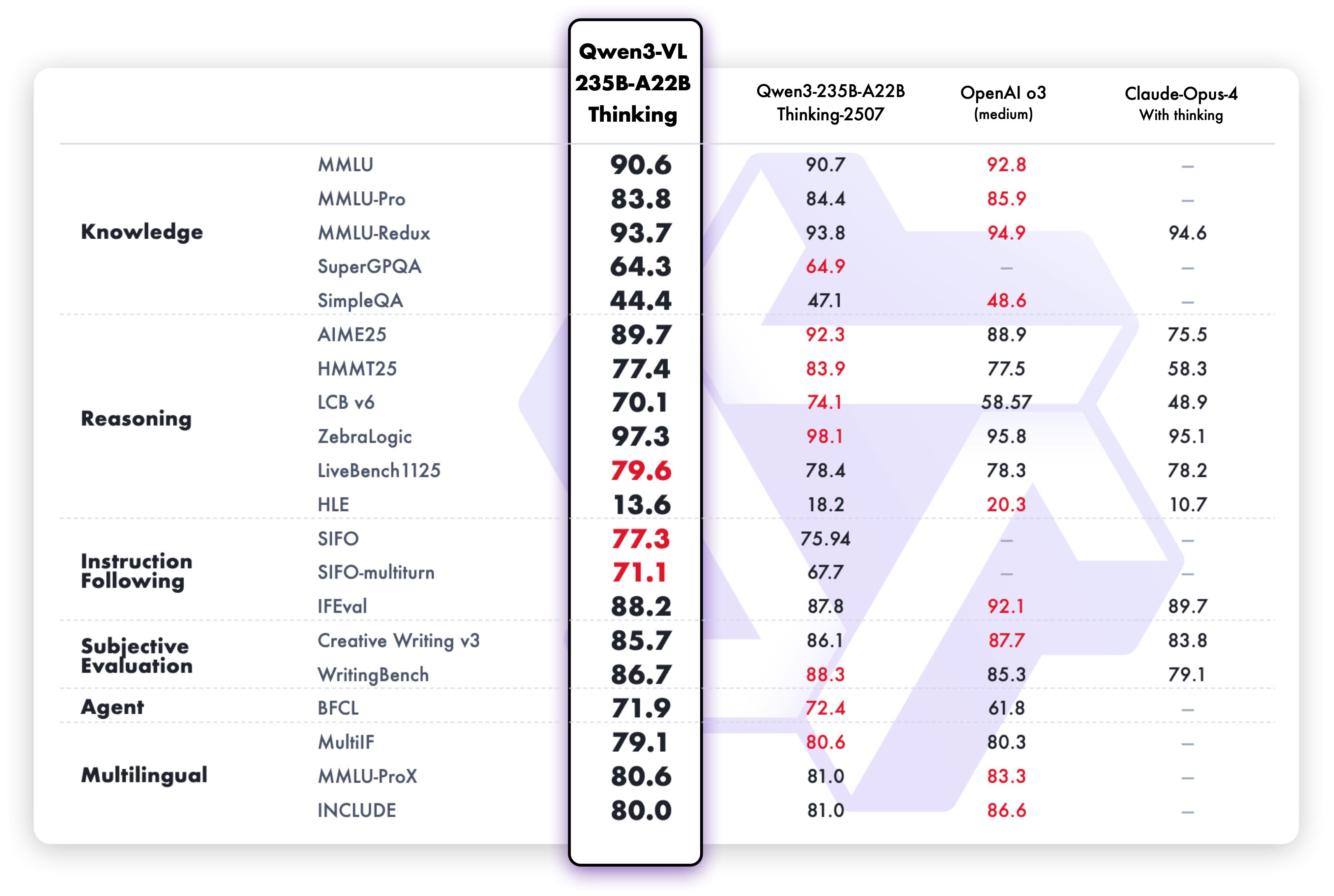
Возможности рассуждения над текстом варианта Thinking демонстрируют превосходную производительность:
Производительность варианта Instruct
Модель Qwen3-VL-235B-A22B-Instruct достигает конкурентоспособных результатов по метрикам оценки зрения и языка:
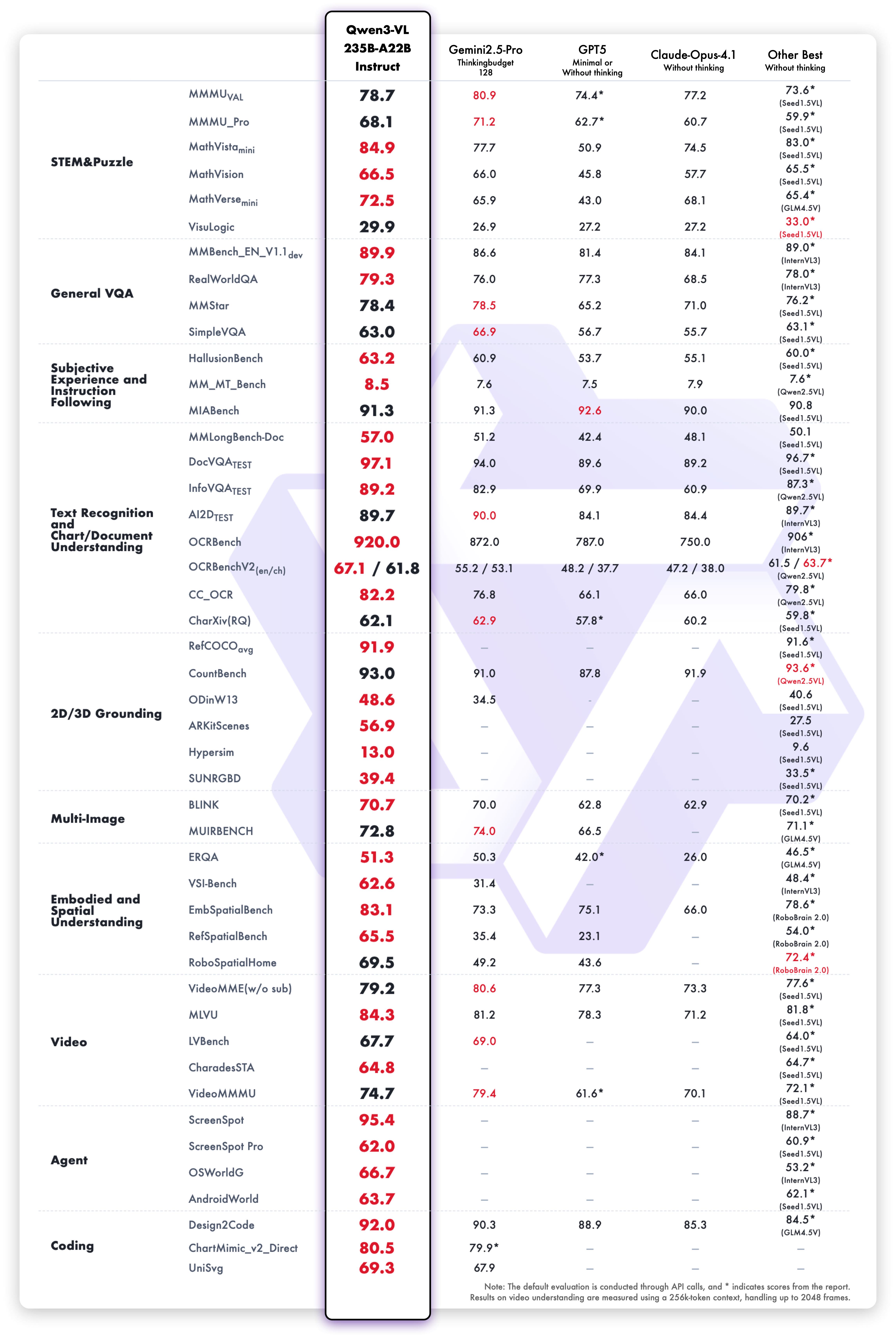
Производительность понимания и генерации текста варианта Instruct:
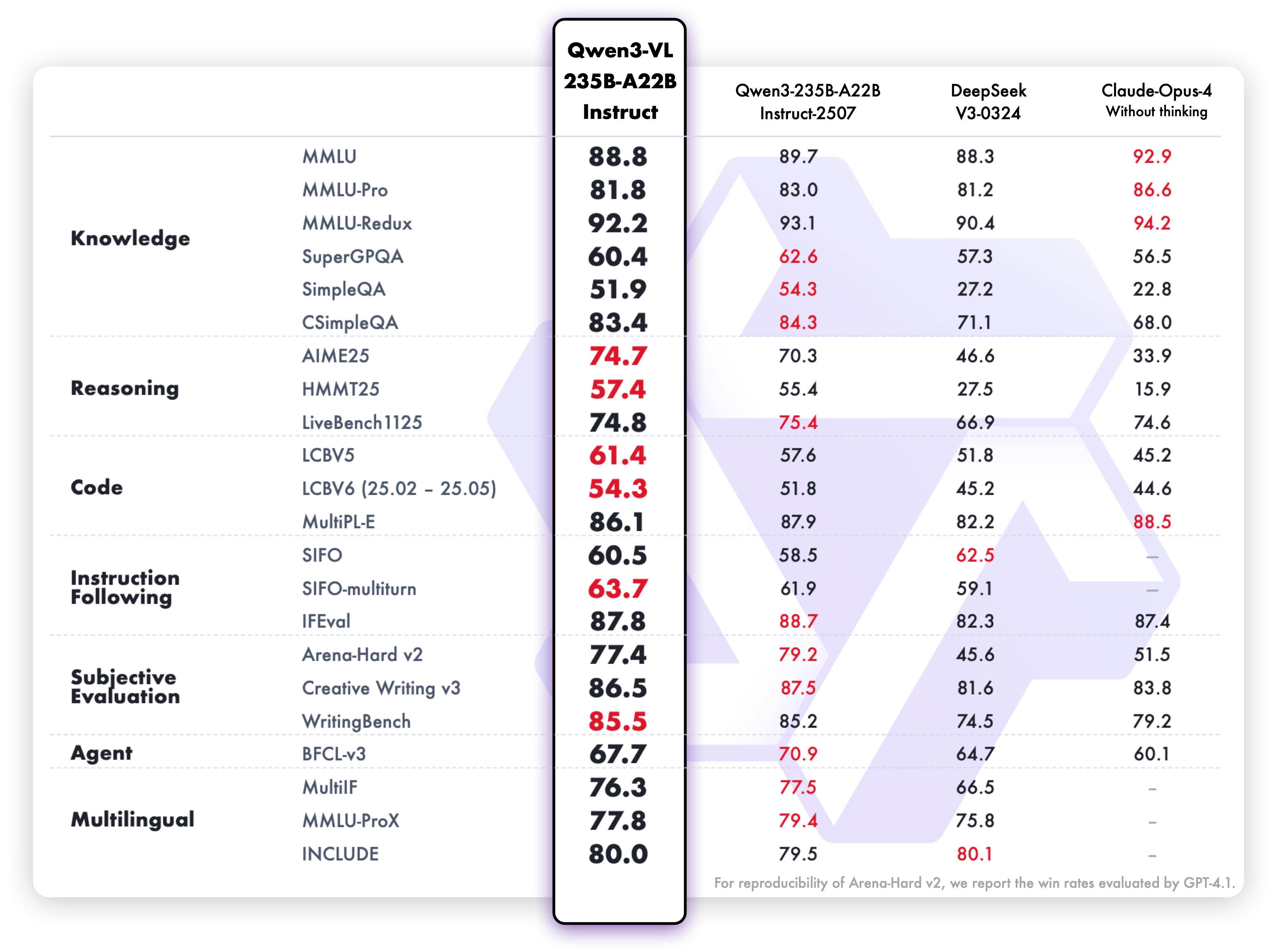
Эти результаты бенчмарков подчеркивают исключительные возможности модели в мультимодальном понимании, рассуждении и генерации текста по разнообразным критериям оценки. Оба варианта демонстрируют высокую производительность в своих соответствующих областях, что делает их чрезвычайно эффективными для предназначенных сценариев использования.
Начало работы с Qwen3-VL-235B-A22B на платформе Novita AI
Доступ к Qwen3-VL-235B-A22B через Novita AI предлагает несколько путей, адаптированных под разные уровни технической экспертизы и сценарии использования. Независимо от того, являетесь ли вы бизнес-пользователем, изучающим возможности ИИ, или разработчиком, создающим производственные приложения, Novita AI предоставляет все необходимые инструменты.
Использование песочницы (Доступно сейчас — не требуется написание кода)
- Мгновенный доступ: Зарегистрируйтесь и начните экспериментировать с моделями Qwen3-VL-235B-A22B за считанные секунды
- Интерактивный интерфейс: Тестируйте запросы и визуализируйте результаты в реальном времени
- Сравнение моделей: Сравнивайте Qwen3-VL-235B-A22B с другими ведущими моделями для вашего конкретного сценария использования
Песочница позволяет тестировать различные запросы и получать немедленные результаты без какой-либо технической настройки. Идеально подходит для прототипирования, тестирования идей и понимания возможностей модели перед полной реализацией.
Интеграция через API (Работает в реальном времени, готово для разработчиков)
Подключите Qwen3-VL-235B-A22B к вашим приложениям с помощью унифицированного REST API Novita AI.
Вариант 1: Прямая интеграция через API (Пример на Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Вариант 2: Мультиагентные рабочие процессы с помощью OpenAI Agents SDK
Создавайте сложные мультиагентные системы, используя продвинутые возможности Qwen3-VL-235B-A22B:
- Интеграция Plug-and-Play: Используйте Qwen3-VL-235B-A22B в любом рабочем процессе OpenAI Agents
- Продвинутые возможности агентов: Поддержка передачи задач, маршрутизации и интеграции инструментов с визуальным пониманием
- Масштабируемая архитектура: Проектируйте агентов, которые используют мультимодальные возможности Qwen3-VL-235B-A22B
Вариант 3: Подключение к сторонним платформам
Инструменты разработки: Бесшовно интегрируйтесь с популярными IDE и средами разработки, такими как Cursor, Trae, Qwen Code и Cline, через совместимые с OpenAI API и совместимые с Anthropic API.
Оркестрационные фреймворки: Подключайтесь к LangChain, Dify, CrewAI, Langflow и другим платформам для оркестрации ИИ с помощью официальных коннекторов.
Интеграция с Hugging Face: Novita AI является официальным провайдером инференса Hugging Face, что обеспечивает широкую совместимость с экосистемой.
Сценарии использования и приложения
Разработка визуальных агентов
Используйте возможности визуальных агентов для создания приложений, которые могут взаимодействовать с графическими интерфейсами, автоматизировать рабочие процессы и выполнять сложные задачи на основе визуального понимания.
Визуальное кодирование и разработка
Используйте улучшение визуального кодирования для генерации HTML, CSS, JavaScript и диаграмм Draw.io на основе визуальных входных данных, ускоряя рабочие процессы разработки.
Анализ документов и видео
Воспользуйтесь длиной контекста 256K и улучшенными возможностями OCR для комплексной обработки документов и анализа видеоконтента.
Приложения в области STEM и образования
Применяйте улучшенное мультимодальное рассуждение для образовательных технологий, научного анализа и приложений для решения математических задач.
Приложения с пространственным рассуждением
Реализуйте продвинутые возможности пространственного восприятия для робототехники, автономных систем и приложений, требующих 3D-понимания.
Заключение
Qwen3-VL-235B-A22B на Novita AI предоставляет самые продвинутые на сегодняшний день возможности зрения и языка, при этом оба варианта — Instruct и Thinking — предлагают гибкие варианты развертывания для разнообразных приложений. Комплексные улучшения в визуальном восприятии, рассуждении и возможностях агентов в сочетании с расширенным контекстом и превосходным мультимодальным пониманием делают эту модель однозначным выбором для передовой разработки ИИ.
Начните изучать революционные возможности Qwen3-VL-235B-A22B на Novita AI уже сегодня и ощутите будущее ИИ зрения и языка с нашей удобной для разработчиков платформой и бесшовными вариантами интеграции.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развертывать модели ИИ с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.



