

يتوفر نموذج Qwen3-VL-235B-A22B الآن على منصة نوفيتا AI، مما يجعل أقوى نموذج رؤية-لغة في سلسلة Qwen متاحًا للمطورين من خلال بنيتنا التحتية المحسنة. يقدم هذا الجيل ترقيات شاملة في جميع المجالات: فهم وتوليد نص متفوق، إدراك واستدلال بصري أعمق، طول سياق ممتد، فهم محسّن للديناميكيات المكانية والفيديو، وقدرات تفاعل أقوى مع الوكلاء.
متوفر في كلا إصداري Instruct و Thinking المحسّن بالاستدلال، يقدم نموذج Qwen3-VL-235B-A22B نشرًا مرنًا عند الطلب لتطبيقات متنوعة. سواء كنت تقوم بتطوير تطبيقات ذكاء اصطناعي بصري، أو بناء حلول أتمتة، أو استكشاف قدرات متعددة الوسائط متقدمة، فإن نموذج Qwen3-VL-235B-A22B على نوفيتا AI يوفر الأدوات التي تحتاجها مع تكامل صديق للمطورين.
تجربة عرض توضيحي لنموذج Qwen3-VL-235B-A22B
ما هو نموذج Qwen3-VL-235B-A22B؟
يمثل نموذج Qwen3-VL-235B-A22B أقوى نموذج رؤية-لغة في سلسلة Qwen حتى الآن. يقدم هذا الجيل ترقيات شاملة في جميع المجالات: فهم وتوليد نص متفوق، إدراك واستدلال بصري أعمق، طول سياق ممتد، فهم محسّن للديناميكيات المكانية والفيديو، وقدرات تفاعل أقوى مع الوكلاء.
متوفر في بنيات Dense و MoE التي تتوسع من الحافة إلى السحابة، مع إصدارات Instruct و Thinking المحسّنة بالاستدلال لنشر مرن عند الطلب. يمثل النموذج تقدمًا كبيرًا في قدرات الذكاء الاصطناعي متعدد الوسائط، حيث يجمع بين فهم بصري متقدم وقدرات استدلال متطورة.
يستفيد كلا الإصدارين من نفس البنية الأساسية ولكن تم تحسينهما لحالات استخدام مختلفة - إصدار Instruct لإكمال المهام مباشرة والتطبيقات التفاعلية، بينما يوفر إصدار Thinking قدرات استدلال محسّنة لسيناريوهات حل المشكلات المعقدة.
التحسينات الرئيسية
الوكيل البصري: يعمل على واجهات المستخدم الرسومية لأجهزة الكمبيوتر/الهواتف المحمولة - يتعرف على العناصر، يفهم الوظائف، يستدعي الأدوات، يكمل المهام. تتيح هذه القدرة الرائدة للنموذج التفاعل مباشرة مع واجهات المستخدم الرسومية، مما يجعل من الممكن أتمتة سير العمل المعقد وبناء وكلاء ذكاء اصطناعي متطورين يمكنهم التنقل والتحكم في تطبيقات البرامج.
تعزيز البرمجة البصرية: يولّد كود Draw.io/HTML/CSS/JS من الصور/الفيديوهات. يمكن للنموذج تحليل التصاميم والنماذج الأولية البصرية لتوليد الكود المقابل تلقائيًا، مما يسرع بشكل كبير سير عمل التطوير ويمكن البرمجة بمساعدة الذكاء الاصطناعي من المدخلات البصرية.
الإدراك المكاني المتقدم: يحدد مواقع الأشياء، وجهات النظر، والعمليات الحجب؛ يوفر ربطًا أقوى بالثنائي الأبعاد ويمكن الربط بالثلاثي الأبعاد للاستدلال المكاني والذكاء الاصطناعي الجسدي. تجعل هذه التحسينات النموذج ذا قيمة خاصة للروبوتات، والأنظمة المستقلة، والتطبيقات التي تتطلب فهمًا مكانيًا متطورًا.
سياق طويل وفهم الفيديو: سياق أصلي 256K، قابل للتوسيع إلى 1M؛ يعالج الكتب والفيديوهات التي تصل ساعات مع استدعاء كامل وفهرسة على مستوى الثانية. تتيح هذه القدرة تحليلًا شاملاً للمستندات الواسعة ومحتوى الفيديو الطويل مع الحفاظ على السياق طوال التسلسل بالكامل.
استدلال متعدد الوسائط محسّن: يتفوق في مجالات العلوم والتكنولوجيا والهندسة والرياضيات - التحليل السببي وإجابات منطقية قائمة على الأدلة. يظهر النموذج أداءً متفوقًا في مهام الاستدلال العلمي والرياضي، ويقدم استجابات تحليلية مفصلة بناءً على المعلومات البصرية والنصية.
تعرف بصري محسّن: التدريب المسبق الأوسع والأعلى جودة قادر على “التعرف على كل شيء” - المشاهير، الأنيمي، المنتجات، المعالم، النباتات/الحيوانات، إلخ. تضمن هذه القدرة الشاملة للتعرف أداءً قويًا عبر أنواع ومجالات محتوى بصري متنوعة.
التعرف الضوئي على الحروف (OCR) الموسع: يدعم 32 لغة (ارتفاعًا من 19)؛ متين في الإضاءة المنخفضة، والضبابية، والانحراف؛ أفضل مع الأحرف النادرة/القديمة والمصطلحات المتخصصة؛ تحليل محسّن لهيكل المستندات الطويلة. تجعل قدرات التعرف الضوئي على الحروف المحسّنة النموذج فعالًا للغاية في مهام معالجة المستندات واستخراج النصوص.
فهم النص على قدم المساواة مع نماذج اللغة الكبيرة النقية: دمج سلس بين النص والرؤية لفهم موحد بدون فقدان. يحقق النموذج قدرات معالجة نصية قابلة للمقارنة مع نماذج اللغة المخصصة مع الحفاظ على فهم متعدد الوسائط متفوق.
تحديثات بنية النموذج
Interleaved-MRoPE
Interleaved-MRoPE: توزيع كامل الترددات عبر الزمن والعرض والارتفاع عبر تضمينات موضعية قوية، مما يعزز الاستدلال على الفيديو على المدى الطويل. تزيد هذه الابتكار المعماري بشكل كبير من قدرة النموذج على معالجة وفهم التسلسلات الزمنية في محتوى الفيديو.
DeepStack Feature Fusion
DeepStack: يدمج ميزات ViT متعددة المستويات لالتقاط التفاصيل الدقيقة وتحسين محاذاة الصورة-النص. تضمن بنية DeepStack التكامل الأمثل بين المعلومات البصرية والنصية، مما يحسن الأداء متعدد الوسائط العام.
Text-Timestamp Alignment
Text-Timestamp Alignment: يتجاوز T-RoPE إلى تحديد موقع الأحداث بدقة مرتبط بالطابع الزمني لنمذجة زمنية أقوى للفيديو. تتيح هذه النهج المتقدم فهمًا زمنيًا أكثر دقة وتحديد موقع للأحداث في محتوى الفيديو.
متغيرات النموذج المتاحة
Qwen3-VL-235B-A22B-Instruct
هذا هو مستودع الأوزان لنموذج Qwen3-VL-235B-A22B-Instruct. تم تحسين إصدار Instruct لإكمال المهام مباشرة والتطبيقات التفاعلية، ويقدم استجابات فورية لاستعلامات وأوامر المستخدم.
يتفوق هذا النموذج في السيناريوهات التي تتطلب استجابات سريعة ودقيقة للمدخلات متعددة الوسائط.
Qwen3-VL-235B-A22B-Thinking
هذا هو مستودع الأوزان لنموذج Qwen3-VL-235B-A22B-Thinking. يدمج إصدار Thinking قدرات استدلال محسّنة، مما يجعله مثالياً لمهام حل المشكلات المعقدة التي تتطلب تحليلاً مفصلاً واستدلالًا خطوة بخطوة.
هذا النموذج ذو قيمة خاصة للتطبيقات التي تتطلب تفكيرًا تحليليًا عميقًا وتقييمًا شاملاً.
معايير الأداء
يظهر نموذج Qwen3-VL-235B-A22B أداءً استثنائيًا عبر مجالات متعددة في كلا إصداري Instruct و Thinking، مما يسلط الضوء على تحسينات كبيرة في فهم الرؤية-اللغة وقدرات الاستدلال.
أداء إصدار Thinking
يظهر نموذج Qwen3-VL-235B-A22B-Thinking نتائج متميزة عبر معايير الرؤية-اللغة:
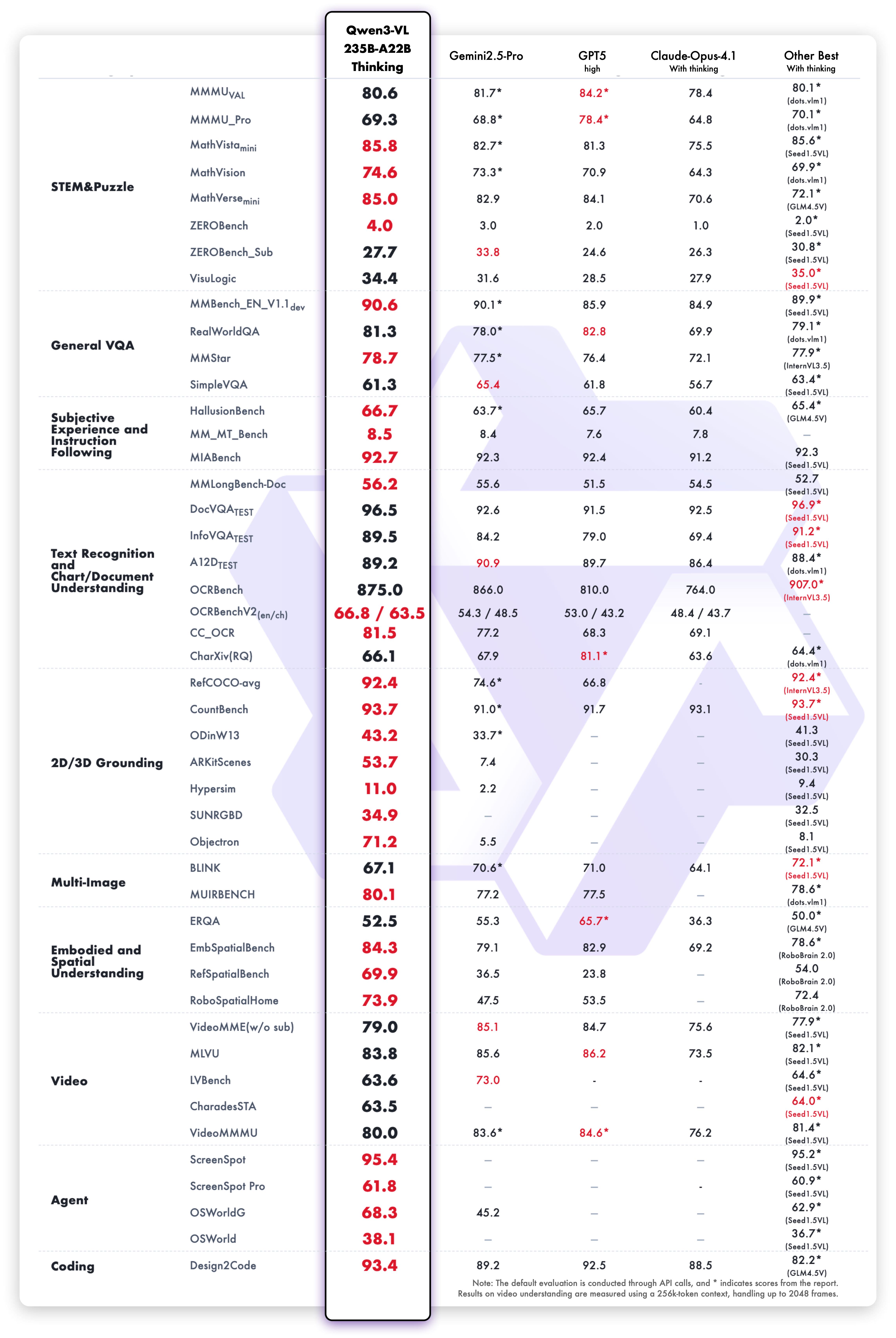
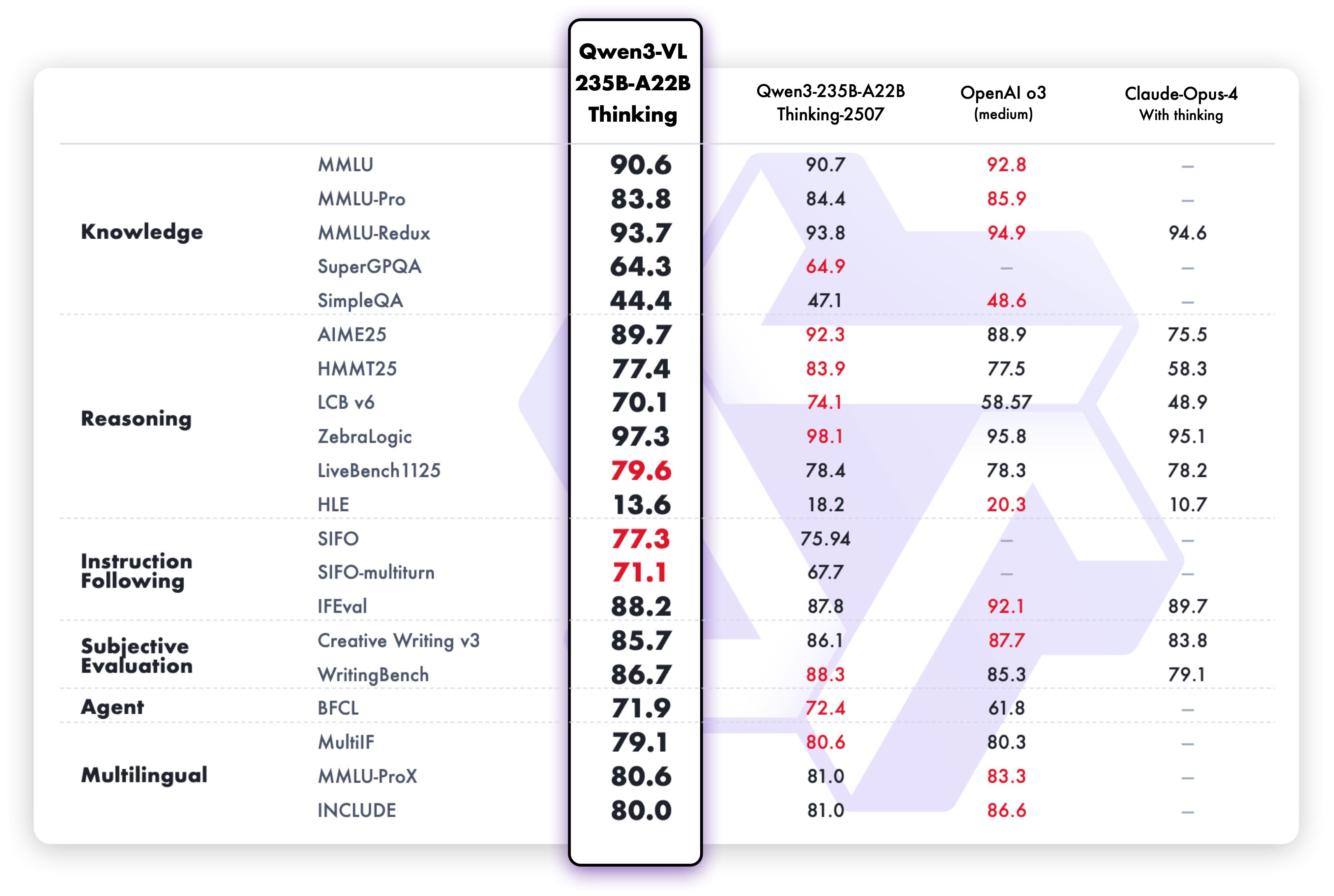
تظهر قدرات الاستدلال النصي لإصدار Thinking أداءً متفوقًا:
أداء إصدار Instruct
يحقق نموذج Qwen3-VL-235B-A22B-Instruct نتائج تنافسية عبر مقاييس تقييم الرؤية-اللغة:
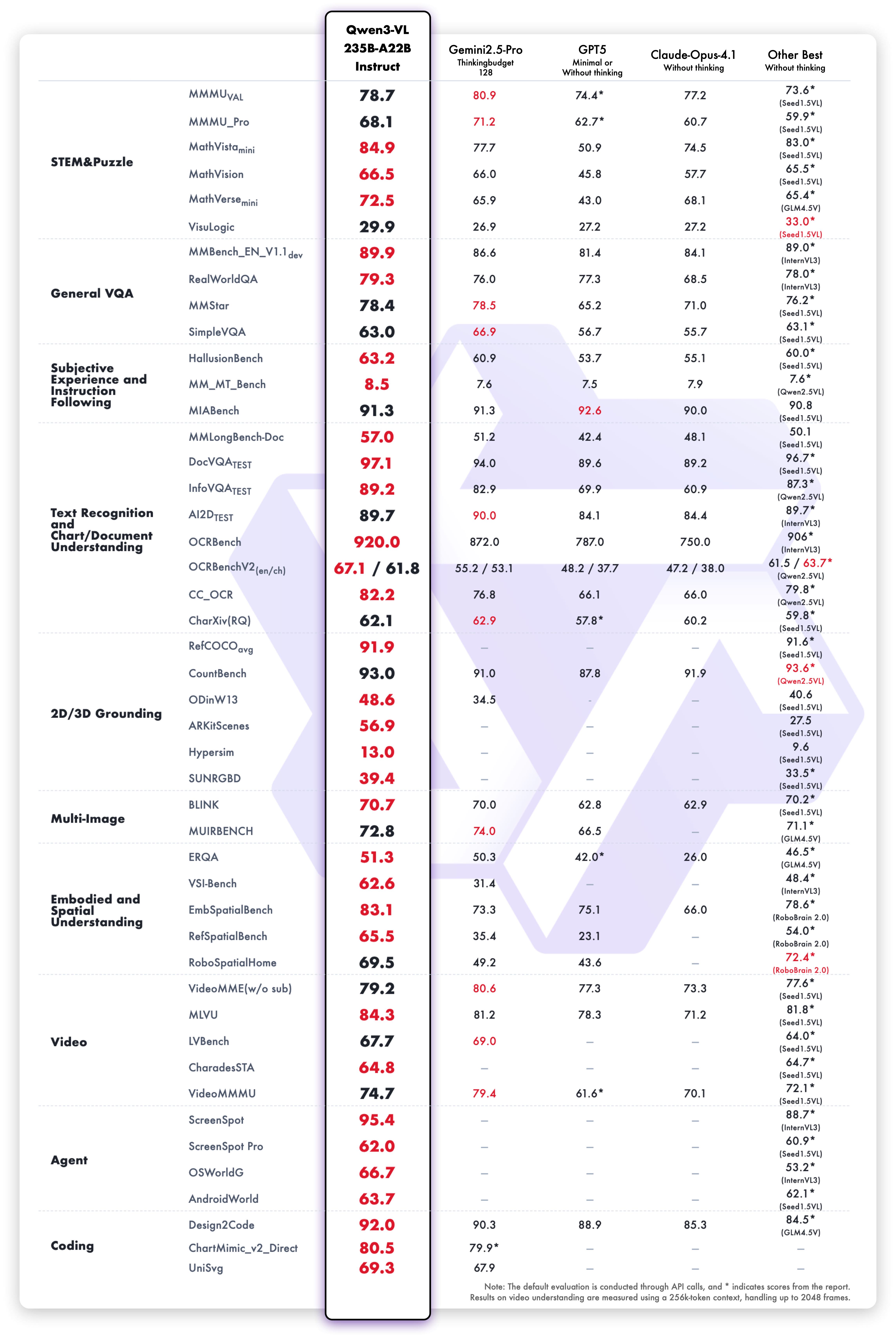
أداء فهم وتوليد النص لإصدار Instruct:
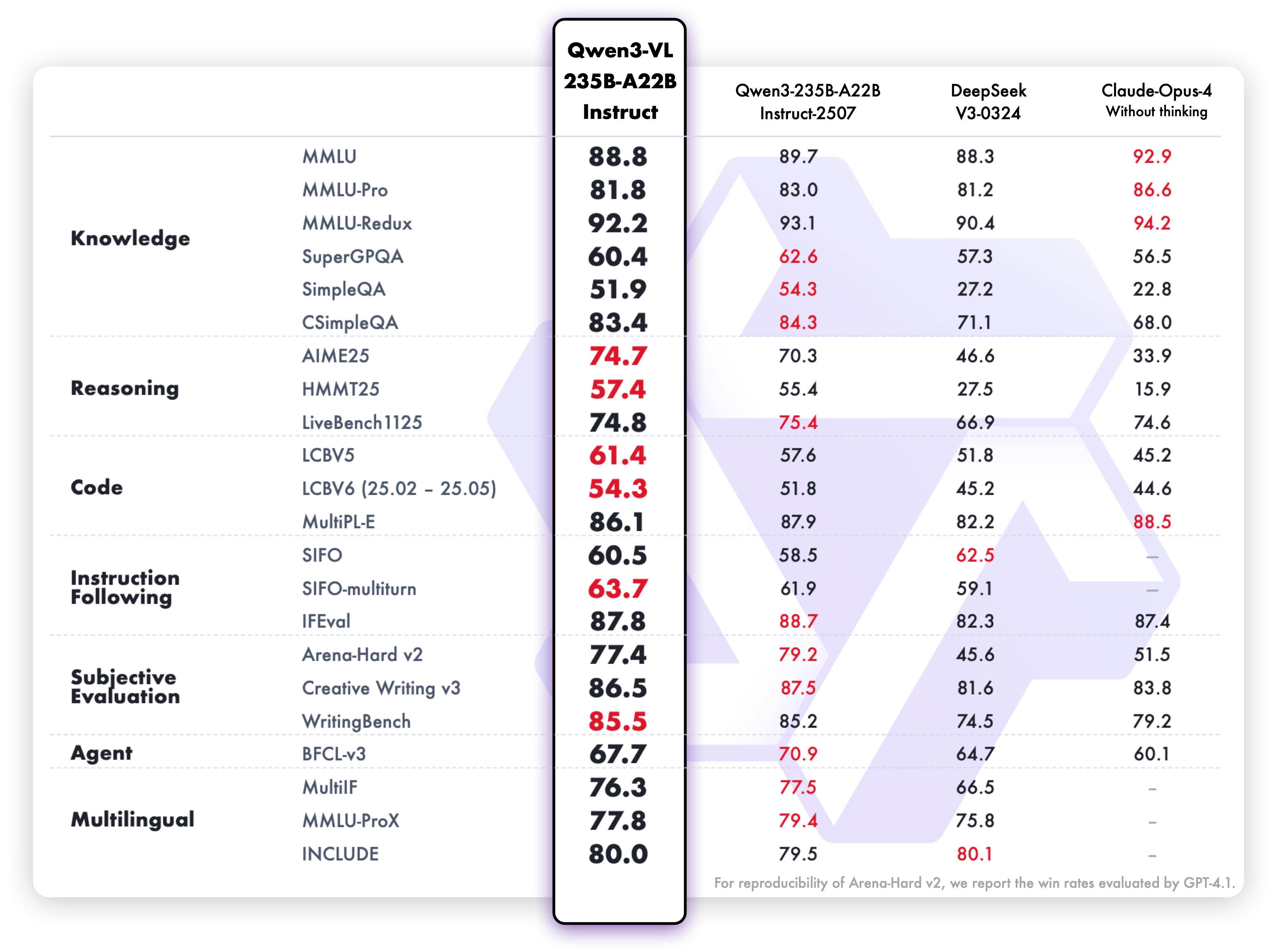
تسلط نتائج هذه المعايير الضوء على القدرات الاستثنائية للنموذج في الفهم متعدد الوسائط، والاستدلال، وتوليد النص عبر معايير تقييم متنوعة. يظهر كلا الإصدارين أداءً قويًا في مجالاتهما الخاصة، مما يجعلهما فعالين للغاية لحالات الاستخدام المخصصة لهما.
الشروع في استخدام نموذج Qwen3-VL-235B-A22B على منصة نوفيتا AI
يوفر الوصول إلى نموذج Qwen3-VL-235B-A22B عبر نوفيتا AI مسارات متعددة مصممة لمستويات خبرة تقنية مختلفة وحالات استخدام متنوعة. سواء كنت مستخدمًا تجاريًا يستكشف قدرات الذكاء الاصطناعي أو مطورًا يبني تطبيقات إنتاجية، فإن نوفيتا AI توفر الأدوات التي تحتاجها.
استخدام مساحة التجربة (متاح الآن - لا يتطلب برمجة)
- وصول فوري: سجّل وابدأ في تجربة نماذج Qwen3-VL-235B-A22B في ثوانٍ
- واجهة تفاعلية: اختبر الأوامر وراجع المخرجات في الوقت الفعلي
- مقارنة النماذج: قارن نموذج Qwen3-VL-235B-A22B مع النماذج الرائدة الأخرى لحالة الاستخدام الخاصة بك
تتيح لك مساحة التجربة اختبار أوامر مختلفة ورؤية نتائج فورية دون أي إعداد تقني. مثالية للنماذج الأولية، واختبار الأفكار، وفهم قدرات النموذج قبل التنفيذ الكامل.
التكامل عبر واجهة برمجة التطبيقات (API) (مباشر وجاهز - للمطورين)
اربط نموذج Qwen3-VL-235B-A22B بتطبيقاتك باستخدام واجهة برمجة التطبيقات REST الموحدة من نوفيتا AI.
الخيار 1: تكامل API مباشر (مثال بلغة بايثون)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
الخيار 2: سير عمل متعدد الوكلاء باستخدام حزمة OpenAI Agents SDK
ابنِ أنظمة متعددة الوكلاء متطورة تستفيد من القدرات المتقدمة لنموذج Qwen3-VL-235B-A22B:
- تكامل Plug-and-Play: استخدم نموذج Qwen3-VL-235B-A22B في أي سير عمل لوكلاء OpenAI
- قدرات وكيل متقدمة: دعم التسليمات، والتوجيه، وتكامل الأدوات مع الفهم البصري
- بنية قابلة للتطوير: صمم وكلاء تستفيد من القدرات متعددة الوسائط لنموذج Qwen3-VL-235B-A22B
الخيار 3: الاتصال بالمنصات الخارجية
أدوات التطوير: تكامل سلس مع بيئات التطوير المتكاملة (IDEs) الشائعة مثل Cursor و Trae و Qwen Code و Cline عبر واجهات برمجة التطبيقات المتوافقة مع OpenAI و Anthropic.
أطر التنسيق: اتصل بـ LangChain و Dify و CrewAI و Langflow ومنصات تنسيق الذكاء الاصطناعي الأخرى باستخدام موصلات رسمية.
تكامل مع Hugging Face: تعمل نوفيتا AI كمزود استدلال رسمي لـ Hugging Face، مما يضمن توافقًا واسعًا مع النظام البيئي.
حالات الاستخدام والتطبيقات
تطوير الوكلاء البصريين
استفد من قدرات الوكيل البصري لبناء تطبيقات يمكنها التفاعل مع واجهات المستخدم الرسومية، وأتمتة سير العمل، وإكمال المهام المعقدة من خلال الفهم البصري.
البرمجة والتطوير البصري
استفد من تحسين البرمجة البصرية لتوليد أكواد HTML و CSS و JavaScript ومخططات Draw.io من المدخلات البصرية، مما يسرع سير عمل التطوير.
تحليل المستندات والفيديو
استفد من طول السياق 256K وقدرات التعرف الضوئي على الحروف (OCR) المحسّنة لمعالجة المستندات الشاملة وتحليل محتوى الفيديو.
تطبيقات العلوم والتكنولوجيا والهندسة والرياضيات والتعليم
طبق الاستدلال متعدد الوسائط المحسّن لتطبيقات التكنولوجيا التعليمية، والتحليل العلمي، وحل المشكلات الرياضية.
تطبيقات الاستدلال المكاني
طبق قدرات الإدراك المكاني المتقدمة للروبوتات، والأنظمة المستقلة، والتطبيقات التي تتطلب فهمًا ثلاثي الأبعاد.
الخلاصة
يقدم نموذج Qwen3-VL-235B-A22B على نوفيتا AI أقوى قدرات رؤية-لغة متاحة اليوم، مع توفير كلا إصداري Instruct و Thinking خيارات نشر مرنة لتطبيقات متنوعة. تجعل التحسينات الشاملة في الإدراك البصري، والاستدلال، وقدرات الوكلاء، جنبًا إلى جنب مع السياق الممتد والفهم متعدد الوسائط المتفوق، هذا النموذج الخيار الأمثل لتطوير الذكاء الاصطناعي المتقدم.
ابدأ في استكشاف القدرات الثورية لنموذج Qwen3-VL-235B-A22B على نوفيتا AI اليوم واختبر مستقبل ذكاء الرؤية-اللغة الاصطناعي مع منصتنا الصديقة للمطورين وخيارات التكامل السلسة.
نوفيتا AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.



