

O Qwen3-VL-235B-A22B já está disponível na plataforma Novita AI, trazendo o modelo de visão e linguagem mais poderoso da série Qwen para desenvolvedores por meio de nossa infraestrutura otimizada. Esta geração oferece atualizações abrangentes em todas as áreas: compreensão e geração de texto superiores, percepção e raciocínio visual mais profundos, comprimento de contexto estendido, compreensão aprimorada de dinâmicas espaciais e de vídeo, e capacidades de interação com agentes mais fortes.
Disponível nas edições Instruct e Thinking, com raciocínio aprimorado, o Qwen3-VL-235B-A22B oferece implantação flexível sob demanda para diversos aplicativos. Se você está desenvolvendo aplicativos de IA visual, criando soluções de automação ou explorando capacidades multimodais avançadas, o Qwen3-VL-235B-A22B na Novita AI fornece as ferramentas que você precisa com integração amigável para desenvolvedores.
Experimentar a demonstração do Qwen3-VL-235B-A22B
O que é o Qwen3-VL-235B-A22B?
O Qwen3-VL-235B-A22B representa o modelo de visão e linguagem mais poderoso da série Qwen até o momento. Esta geração oferece atualizações abrangentes em todas as áreas: compreensão e geração de texto superiores, percepção e raciocínio visual mais profundos, comprimento de contexto estendido, compreensão aprimorada de dinâmicas espaciais e de vídeo, e capacidades de interação com agentes mais fortes.
Disponível nas arquiteturas Dense e MoE que escalam de dispositivos de borda para nuvem, com edições Instruct e Thinking de raciocínio aprimorado para implantação flexível sob demanda. O modelo representa um avanço significativo nas capacidades de IA multimodal, combinando compreensão visual avançada com habilidades de raciocínio sofisticadas.
Ambas as variantes utilizam a mesma arquitetura principal, mas são otimizadas para casos de uso diferentes: a edição Instruct para conclusão direta de tarefas e aplicativos interativos, enquanto a edição Thinking fornece capacidades de raciocínio aprimoradas para cenários de resolução de problemas complexos.
Principais Melhorias
Agente Visual: Opera interfaces gráficas de usuário (GUIs) de PCs e dispositivos móveis — reconhece elementos, entende funções, invoca ferramentas e conclui tarefas. Essa capacidade revolucionária permite que o modelo interaja diretamente com interfaces gráficas, tornando possível automatizar fluxos de trabalho complexos e construir agentes de IA sofisticados que podem navegar e controlar aplicativos de software.
Aumento na Codificação Visual: Gera código Draw.io/HTML/CSS/JS a partir de imagens e vídeos. O modelo pode analisar designs visuais e mockups para gerar automaticamente o código correspondente, acelerando drasticamente os fluxos de trabalho de desenvolvimento e permitindo codificação assistida por IA a partir de entradas visuais.
Percepção Espacial Avançada: Avalia posições de objetos, pontos de vista e oclusões; fornece ancoragem 2D mais forte e permite ancoragem 3D para raciocínio espacial e IA incorporada. Essa melhoria torna o modelo particularmente valioso para robótica, sistemas autônomos e aplicativos que exigem compreensão espacial sofisticada.
Contexto Longo e Compreensão de Vídeo: Contexto nativo de 256K, expansível para 1M; lida com livros e vídeos de várias horas com recuperação completa e indexação em nível de segundo. Essa capacidade permite análise abrangente de documentos extensos e conteúdo de vídeo longo, mantendo o contexto em toda a sequência.
Raciocínio Multimodal Aprimorado: Excel em STEM/Matemática — análise causal e respostas lógicas baseadas em evidências. O modelo demonstra desempenho superior em tarefas de raciocínio científico e matemático, fornecendo respostas analíticas detalhadas com base em informações visuais e textuais.
Reconhecimento Visual Atualizado: O pré-treinamento mais amplo e de maior qualidade é capaz de “reconhecer tudo” — celebridades, animes, produtos, pontos turísticos, flora/fauna, etc. Essa capacidade de reconhecimento abrangente garante desempenho robusto em diversos tipos de conteúdo visual e domínios.
OCR Expandido: Suporta 32 idiomas (aumento de 19); robusto em condições de pouca luz, desfoque e inclinação; melhor desempenho com caracteres raros/antigos e jargões; análise de estrutura de documentos longos aprimorada. As capacidades de reconhecimento óptico de caracteres aprimoradas tornam o modelo altamente eficaz para tarefas de processamento de documentos e extração de texto.
Compreensão de Texto Equivalente a LLMs Puros: Fusão perfeita entre texto e visão para compreensão unificada sem perdas. O modelo alcança capacidades de processamento de texto comparáveis a modelos de linguagem dedicados, mantendo uma compreensão multimodal superior.
Atualizações na Arquitetura do Modelo
Interleaved-MRoPE
Interleaved-MRoPE: Alocação de frequência completa ao longo do tempo, largura e altura por meio de embeddings posicionais robustos, aprimorando o raciocínio em vídeos de longo horizonte. Essa inovação arquitetônica melhora significativamente a capacidade do modelo de processar e entender sequências temporais em conteúdo de vídeo.
DeepStack Feature Fusion
DeepStack: Fundir recursos ViT de múltiplos níveis para capturar detalhes granulares e aprimorar o alinhamento entre imagem e texto. A arquitetura DeepStack garante a integração ideal entre informações visuais e textuais, melhorando o desempenho multimodal geral.
Alinhamento Texto-Timestamp
Alinhamento Texto-Timestamp: Avança além do T‑RoPE para a localização precisa de eventos baseada em carimbos de data/hora, permitindo modelagem temporal de vídeo mais forte. Essa abordagem avançada permite uma compreensão temporal mais precisa e localização de eventos em conteúdo de vídeo.
Variantes de Modelo Disponíveis
Qwen3-VL-235B-A22B-Instruct
Este é o repositório de pesos do Qwen3-VL-235B-A22B-Instruct. A variante Instruct é otimizada para conclusão direta de tarefas e aplicativos interativos, fornecendo respostas imediatas a consultas e comandos de usuários.
Este modelo se destaca em cenários que exigem respostas rápidas e precisas a entradas multimodais.
Qwen3-VL-235B-A22B-Thinking
Este é o repositório de pesos do Qwen3-VL-235B-A22B-Thinking. A variante Thinking incorpora capacidades de raciocínio aprimoradas, sendo ideal para tarefas de resolução de problemas complexos que exigem análise detalhada e raciocínio passo a passo.
Este modelo é particularmente valioso para aplicativos que exigem pensamento analítico profundo e avaliação abrangente.
Benchmark de Desempenho
O Qwen3-VL-235B-A22B demonstra desempenho excepcional em vários domínios, tanto na variante Instruct quanto na Thinking, apresentando melhorias significativas nas capacidades de compreensão e raciocínio de visão e linguagem.
Desempenho da Variante Thinking
O modelo Qwen3-VL-235B-A22B-Thinking apresenta resultados excepcionais nos benchmarks de visão e linguagem:
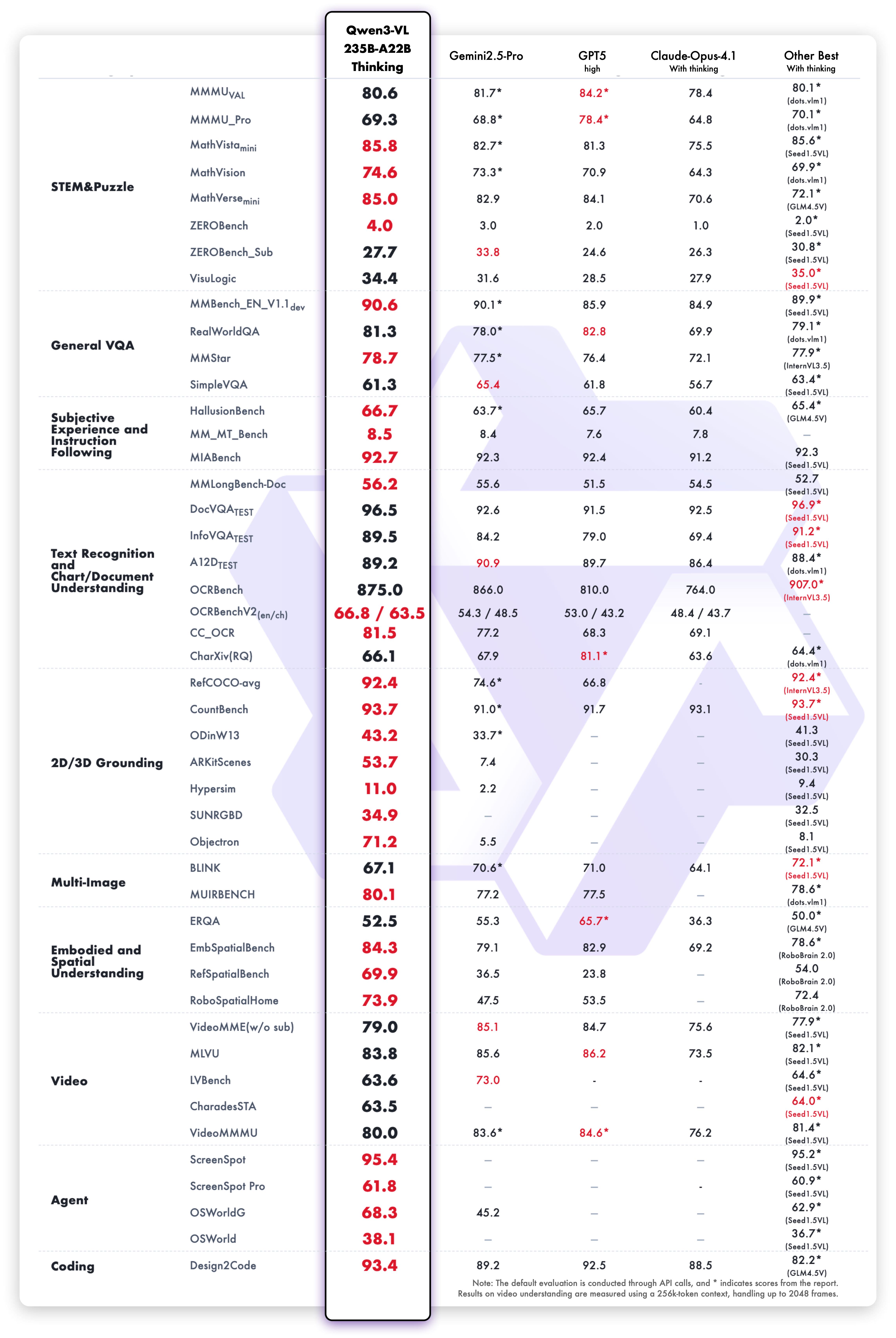
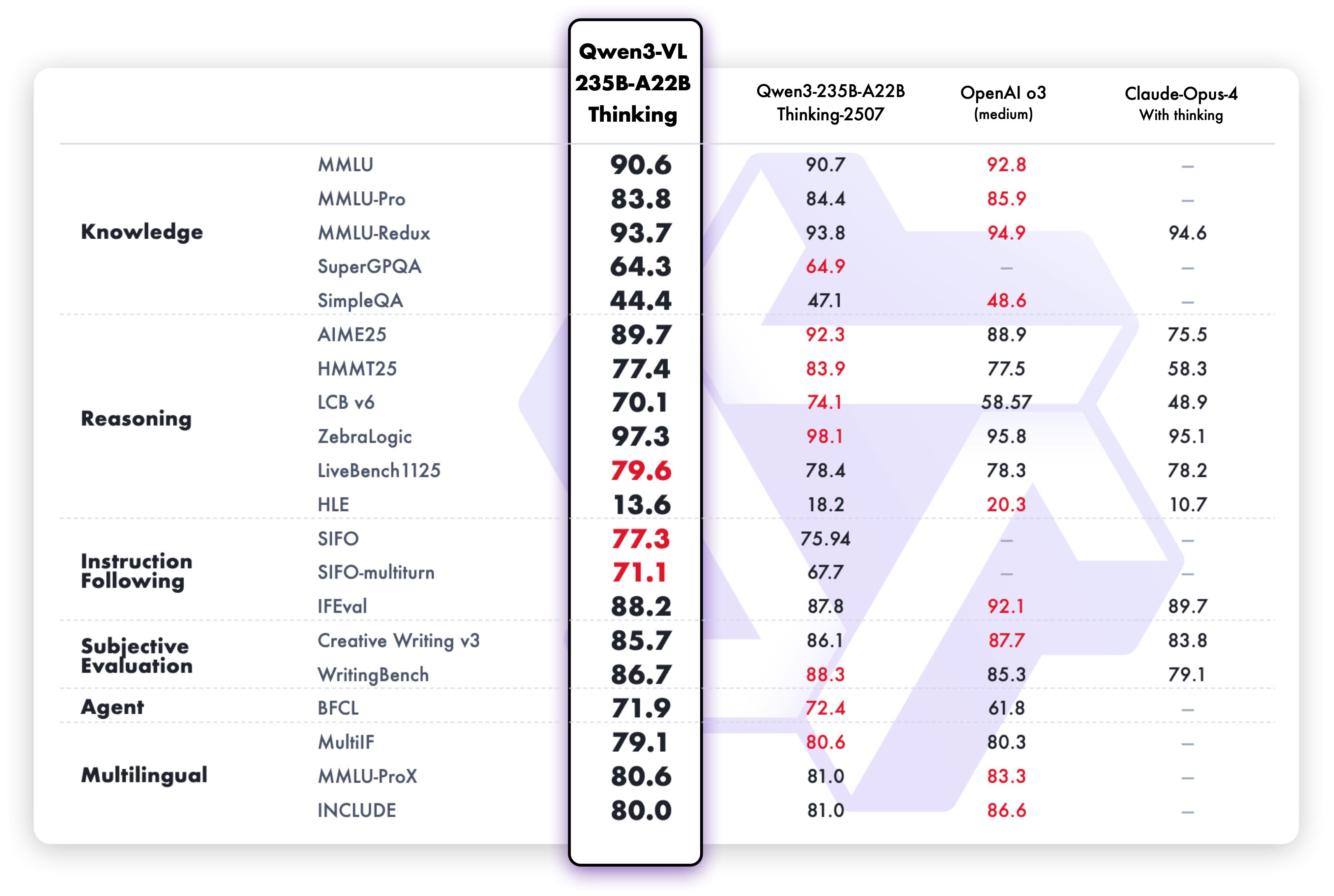
As capacidades de raciocínio textual da variante Thinking demonstram desempenho superior:
Desempenho da Variante Instruct
O modelo Qwen3-VL-235B-A22B-Instruct obtém resultados competitivos nas métricas de avaliação de visão e linguagem:
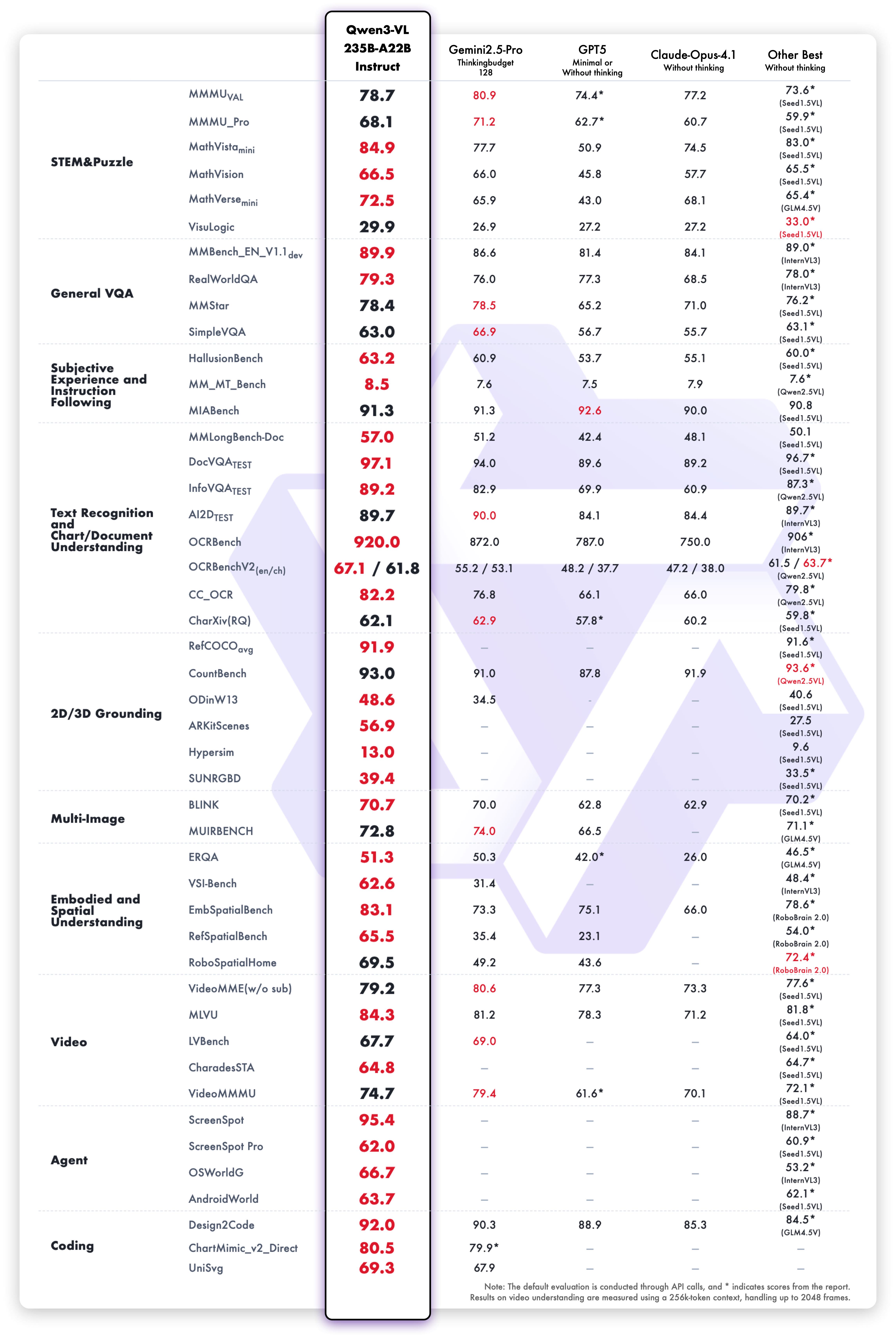
Desempenho de compreensão e geração de texto da variante Instruct:
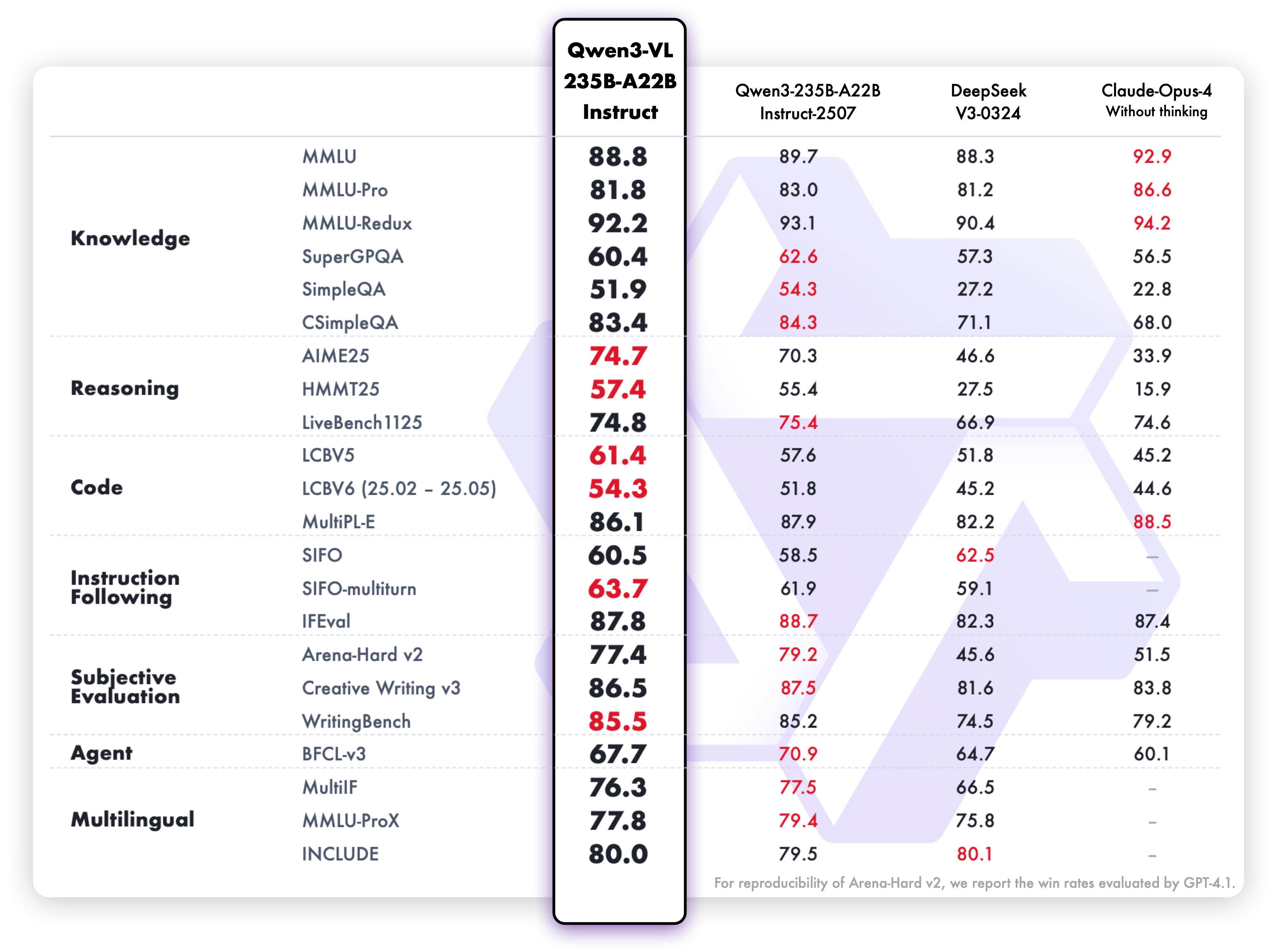
Esses resultados de benchmark destacam as capacidades excepcionais do modelo em compreensão multimodal, raciocínio e geração de texto em diversos critérios de avaliação. Ambas as variantes demonstram desempenho forte em suas respectivas áreas, tornando-as altamente eficazes para os casos de uso pretendidos.
Começando a Usar o Qwen3-VL-235B-A22B na Plataforma Novita AI
Acessar o Qwen3-VL-235B-A22B por meio da Novita AI oferece vários caminhos adaptados a diferentes níveis de conhecimento técnico e casos de uso. Se você é um usuário empresarial explorando capacidades de IA ou um desenvolvedor criando aplicativos de produção, a Novita AI fornece as ferramentas que você precisa.
Use o Playground (Disponível Agora – Sem Necessidade de Código)
- Acesso Imediato: Inscreva-se e comece a experimentar os modelos Qwen3-VL-235B-A22B em segundos
- Interface Interativa: Teste prompts e visualize as saídas em tempo real
- Comparação de Modelos: Compare o Qwen3-VL-235B-A22B com outros modelos líderes para seu caso de uso específico
O playground permite que você teste vários prompts e veja resultados imediatos sem nenhuma configuração técnica. Perfeito para prototipagem, teste de ideias e compreensão das capacidades do modelo antes da implementação completa.
Integre via API (Ao Vivo e Pronto – Para Desenvolvedores)
Conecte o Qwen3-VL-235B-A22B aos seus aplicativos com a API REST unificada da Novita AI.
Opção 1: Integração Direta via API (Exemplo em Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Opção 2: Fluxos de Trabalho Multiagente com o SDK de Agentes da OpenAI
Construa sistemas multiagente sofisticados aproveitando as capacidades avançadas do Qwen3-VL-235B-A22B:
- Integração Plug-and-Play: Use o Qwen3-VL-235B-A22B em qualquer fluxo de trabalho de Agentes da OpenAI
- Capacidades de Agente Avançadas: Suporte a transferências, roteamento e integração de ferramentas com compreensão visual
- Arquitetura Escalável: Projete agentes que aproveitem as capacidades multimodais do Qwen3-VL-235B-A22B
Opção 3: Conecte-se a Plataformas de Terceiros
Ferramentas de Desenvolvimento: Integre-se perfeitamente com IDEs populares e ambientes de desenvolvimento como Cursor, Trae, Qwen Code e Cline por meio de APIs compatíveis com OpenAI e APIs compatíveis com Anthropic.
Frameworks de Orquestração: Conecte-se com LangChain, Dify, CrewAI, Langflow e outras plataformas de orquestração de IA usando conectores oficiais.
Integração com Hugging Face: A Novita AI atua como um provedor de inferência oficial do Hugging Face, garantindo ampla compatibilidade com o ecossistema.
Casos de Uso e Aplicações
Desenvolvimento de Agentes Visuais
Aproveite as capacidades de agente visual para construir aplicativos que podem interagir com GUIs, automatizar fluxos de trabalho e concluir tarefas complexas por meio de compreensão visual.
Codificação e Desenvolvimento Visual
Utilize o aprimoramento de codificação visual para gerar diagramas HTML, CSS, JavaScript e Draw.io a partir de entradas visuais, acelerando os fluxos de trabalho de desenvolvimento.
Análise de Documentos e Vídeos
Aproveite o comprimento de contexto de 256K e as capacidades de OCR aprimoradas para processamento abrangente de documentos e análise de conteúdo de vídeo.
Aplicações em STEM e Educação
Aplique o raciocínio multimodal aprimorado em tecnologia educacional, análise científica e aplicativos de resolução de problemas matemáticos.
Aplicações de Raciocínio Espacial
Implemente as capacidades avançadas de percepção espacial para robótica, sistemas autônomos e aplicativos que exigem compreensão 3D.
Conclusão
O Qwen3-VL-235B-A22B na Novita AI oferece as capacidades de visão e linguagem mais avançadas disponíveis atualmente, com ambas as variantes Instruct e Thinking fornecendo opções de implantação flexíveis para diversos aplicativos. Os aprimoramentos abrangentes em percepção visual, raciocínio e capacidades de agente, combinados com contexto estendido e compreensão multimodal superior, tornam esta a escolha definitiva para desenvolvimento de IA de ponta.
Comece a explorar as capacidades revolucionárias do Qwen3-VL-235B-A22B na Novita AI hoje e experimente o futuro da IA de visão e linguagem com nossa plataforma amigável para desenvolvedores e opções de integração perfeitas.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



