

Qwen3-VL-235B-A22B est désormais disponible sur la plateforme Novita AI, apportant aux développeurs le modèle vision-langage le plus puissant de la série Qwen via notre infrastructure optimisée. Cette génération propose des améliorations complètes sur tous les aspects : compréhension et génération de texte supérieures, perception visuelle et raisonnement plus approfondis, longueur de contexte étendue, meilleure compréhension des dynamiques spatiales et vidéo, et capacités d’interaction avec des agents renforcées.
Disponible dans les éditions Instruct et Thinking à raisonnement amélioré, Qwen3-VL-235B-A22B propose un déploiement flexible à la demande pour des applications variées. Que vous développiez des applications IA visuelles, construisiez des solutions d’automatisation ou que vous exploriez des capacités multimodales avancées, Qwen3-VL-235B-A22B sur Novita AI vous fournit les outils dont vous avez besoin avec une intégration adaptée aux développeurs.
Essayer la démo de Qwen3-VL-235B-A22B
Qu’est-ce que Qwen3-VL-235B-A22B ?
Qwen3-VL-235B-A22B représente le modèle vision-langage le plus puissant de la série Qwen à ce jour. Cette génération propose des améliorations complètes sur tous les aspects : compréhension et génération de texte supérieures, perception visuelle et raisonnement plus approfondis, longueur de contexte étendue, meilleure compréhension des dynamiques spatiales et vidéo, et capacités d’interaction avec des agents renforcées.
Disponible dans des architectures Dense et MoE qui s’adaptent des périphériques edge au cloud, avec les éditions Instruct et Thinking à raisonnement amélioré pour un déploiement flexible à la demande. Ce modèle représente une avancée significative des capacités de l’IA multimodale, combinant une compréhension visuelle avancée à des capacités de raisonnement sophistiquées.
Les deux variantes s’appuient sur la même architecture de base mais sont optimisées pour des cas d’usage différents : l’édition Instruct pour l’exécution directe de tâches et les applications interactives, tandis que l’édition Thinking propose des capacités de raisonnement améliorées pour des scénarios de résolution de problèmes complexes.
Améliorations clés
Agent visuel : Opère sur les interfaces graphiques PC/mobile : reconnaît les éléments, comprend leurs fonctions, invoque des outils, accomplit des tâches. Cette capacité révolutionnaire permet au modèle d’interagir directement avec les interfaces graphiques utilisateur, rendant possible l’automatisation de flux de travail complexes et la construction d’agents IA sophistiqués capables de naviguer et de contrôler des applications logicielles.
Amélioration du codage visuel : Génère du code Draw.io/HTML/CSS/JS à partir d’images/vidéos. Le modèle peut analyser des designs visuels et des maquettes pour générer automatiquement le code correspondant, accélérant considérablement les flux de travail de développement et permettant un codage assisté par IA à partir d’entrées visuelles.
Perception spatiale avancée : Évalue les positions d’objets, les points de vue et les occultations ; offre un ancrage 2D plus solide et permet un ancrage 3D pour le raisonnement spatial et l’IA incarnée. Cette amélioration rend le modèle particulièrement précieux pour la robotique, les systèmes autonomes et les applications nécessitant une compréhension spatiale sophistiquée.
Long contexte et compréhension vidéo : Contexte natif de 256K tokens, extensible à 1M ; traite des livres et des vidéos de plusieurs heures avec un rappel complet et une indexation au niveau de la seconde. Cette capacité permet une analyse complète de documents étendus et de contenu vidéo long tout en maintenant le contexte sur l’ensemble de la séquence.
Raisonnement multimodal amélioré : Excelle dans les domaines STIM/Mathématiques : analyse causale et réponses logiques fondées sur des preuves. Le modèle démontre des performances supérieures dans les tâches de raisonnement scientifique et mathématique, fournissant des réponses analytiques détaillées basées sur des informations visuelles et textuelles.
Reconnaissance visuelle améliorée : Un pré-entraînement plus large et de meilleure qualité permet de « reconnaître tout » : célébrités, anime, produits, monuments, flore/faune, etc. Cette capacité de reconnaissance complète garantit des performances robustes sur des types et des domaines de contenu visuel variés.
OCR étendu : Prend en charge 32 langues (contre 19 auparavant) ; robuste en faible luminosité, avec du flou et des inclinaisons ; meilleure performance sur les caractères rares/anciens et le jargon ; analyse améliorée de la structure des documents longs. Les capacités de reconnaissance optique de caractères améliorées rendent le modèle très efficace pour les tâches de traitement de documents et d’extraction de texte.
Compréhension de texte équivalente aux LLM purs : Fusion transparente texte-vision pour une compréhension unifiée sans perte. Le modèle atteint des capacités de traitement de texte comparables à celles des modèles de langage dédiés, tout en maintenant une compréhension multimodale supérieure.
Mises à jour de l’architecture du modèle
Interleaved-MRoPE
Interleaved-MRoPE : allocation complète des fréquences sur le temps, la largeur et la hauteur via des embeddings positionnels robustes, améliorant le raisonnement sur des séquences vidéo longues. Cette innovation architecturale améliore considérablement la capacité du modèle à traiter et à comprendre les séquences temporelles dans le contenu vidéo.
Fusion de caractéristiques DeepStack
DeepStack : fusionne les caractéristiques ViT multi-niveaux pour capturer des détails fins et affiner l’alignement image-texte. L’architecture DeepStack assure une intégration optimale entre les informations visuelles et textuelles, améliorant les performances multimodales globales.
Alignement texte-horodatage
Alignement texte-horodatage : va au-delà du T-RoPE pour une localisation précise des événements basée sur l’horodatage, pour une modélisation temporelle vidéo plus robuste. Cette approche avancée permet une compréhension temporelle plus précise et une localisation des événements dans le contenu vidéo.
Variantes de modèle disponibles
Qwen3-VL-235B-A22B-Instruct
Ceci est le dépôt de poids pour Qwen3-VL-235B-A22B-Instruct. La variante Instruct est optimisée pour l’exécution directe de tâches et les applications interactives, fournissant des réponses immédiates aux requêtes et commandes des utilisateurs.
Ce modèle excelle dans les scénarios nécessitant des réponses rapides et précises à des entrées multimodales.
Qwen3-VL-235B-A22B-Thinking
Ceci est le dépôt de poids pour Qwen3-VL-235B-A22B-Thinking. La variante Thinking intègre des capacités de raisonnement améliorées, ce qui la rend idéale pour des tâches de résolution de problèmes complexes nécessitant une analyse détaillée et un raisonnement étape par étape.
Ce modèle est particulièrement précieux pour les applications nécessitant une réflexion analytique approfondie et une évaluation complète.
Benchmarks de performance
Qwen3-VL-235B-A22B démontre des performances exceptionnelles dans de multiples domaines, tant dans la variante Instruct que Thinking, mettant en évidence des améliorations significatives en compréhension vision-langage et en capacités de raisonnement.
Performances de la variante Thinking
Le modèle Qwen3-VL-235B-A22B-Thinking obtient des résultats exceptionnels sur les benchmarks vision-langage :
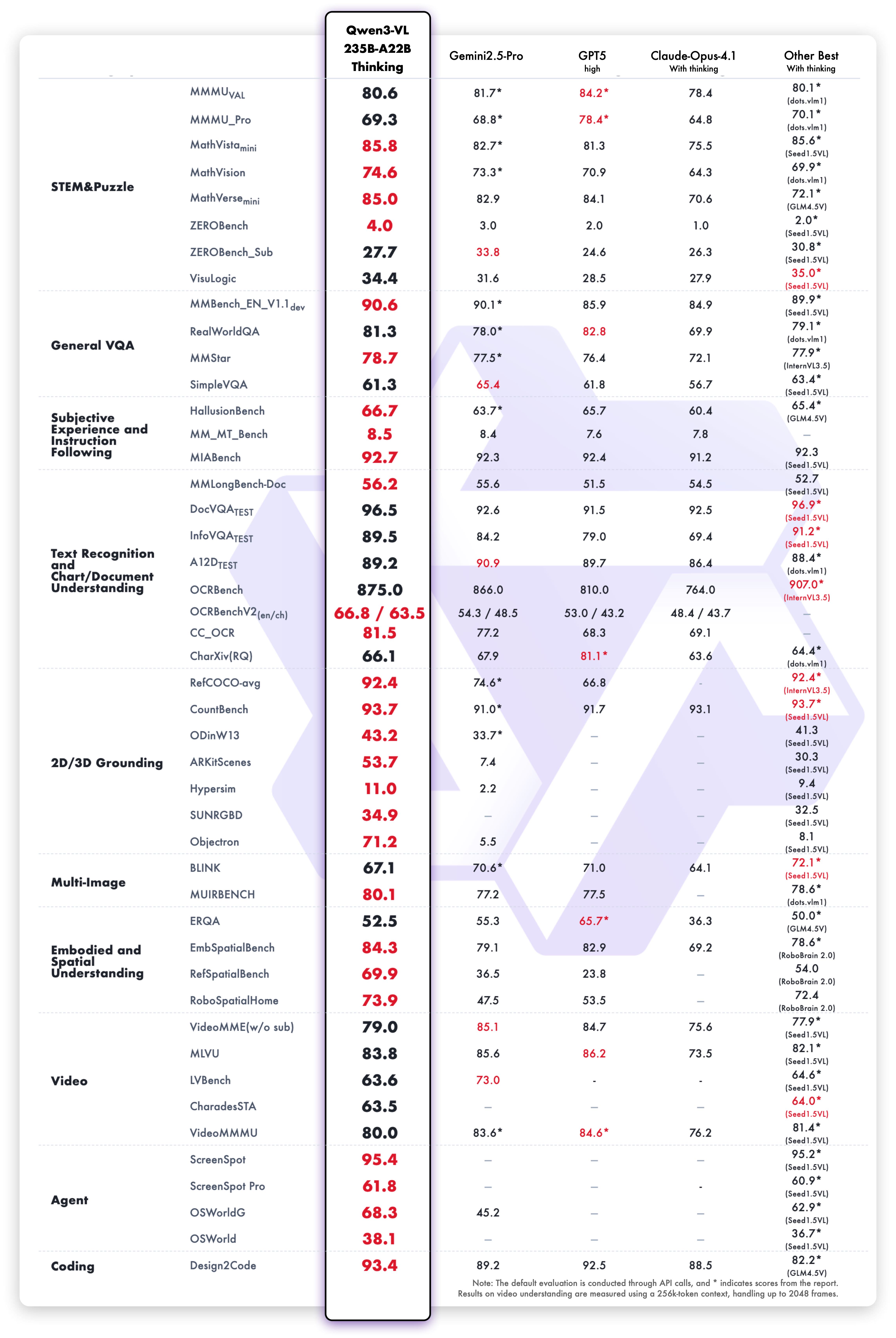
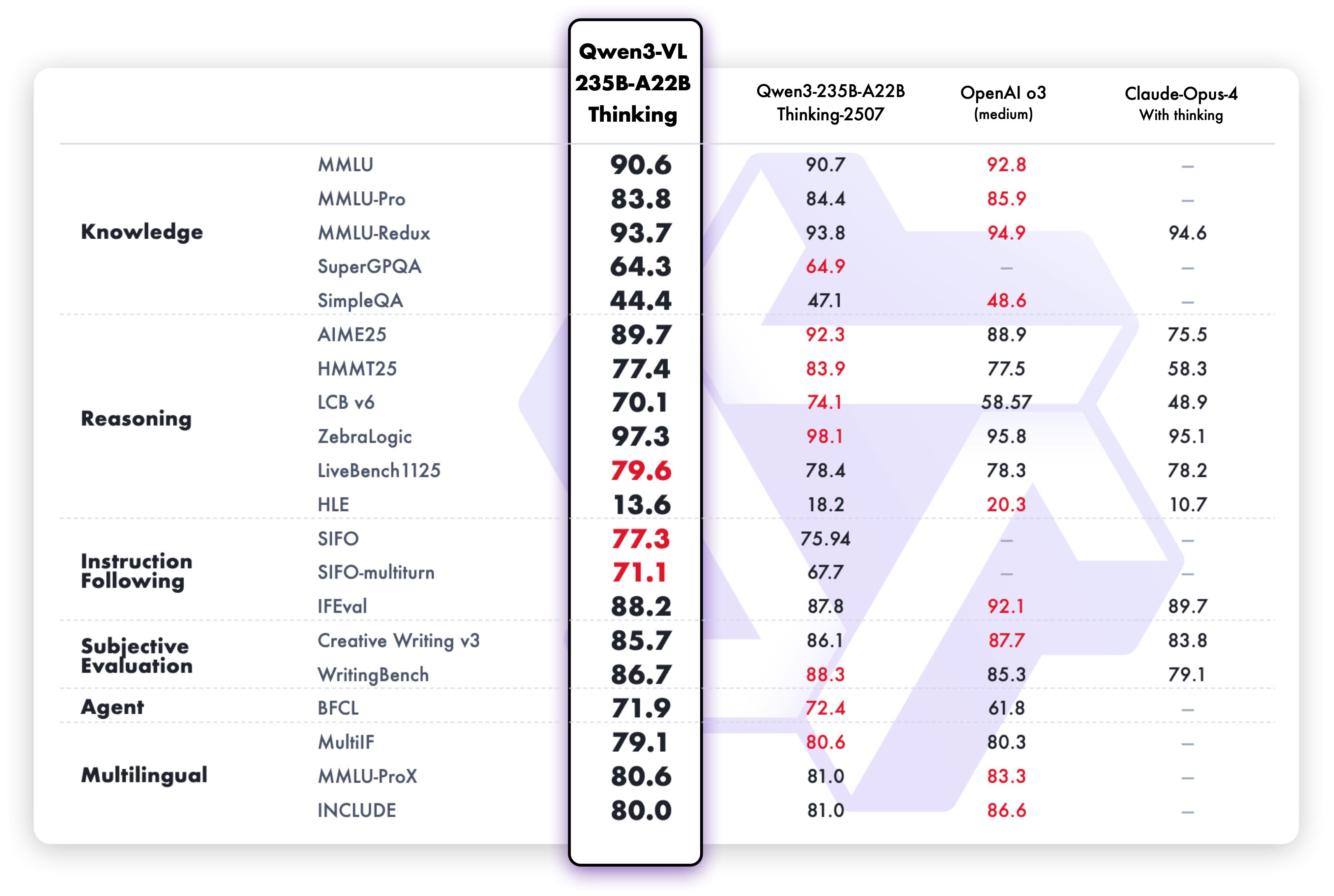
Les capacités de raisonnement textuel de la variante Thinking démontrent des performances supérieures :
Performances de la variante Instruct
Le modèle Qwen3-VL-235B-A22B-Instruct obtient des résultats compétitifs sur les métriques d’évaluation vision-langage :
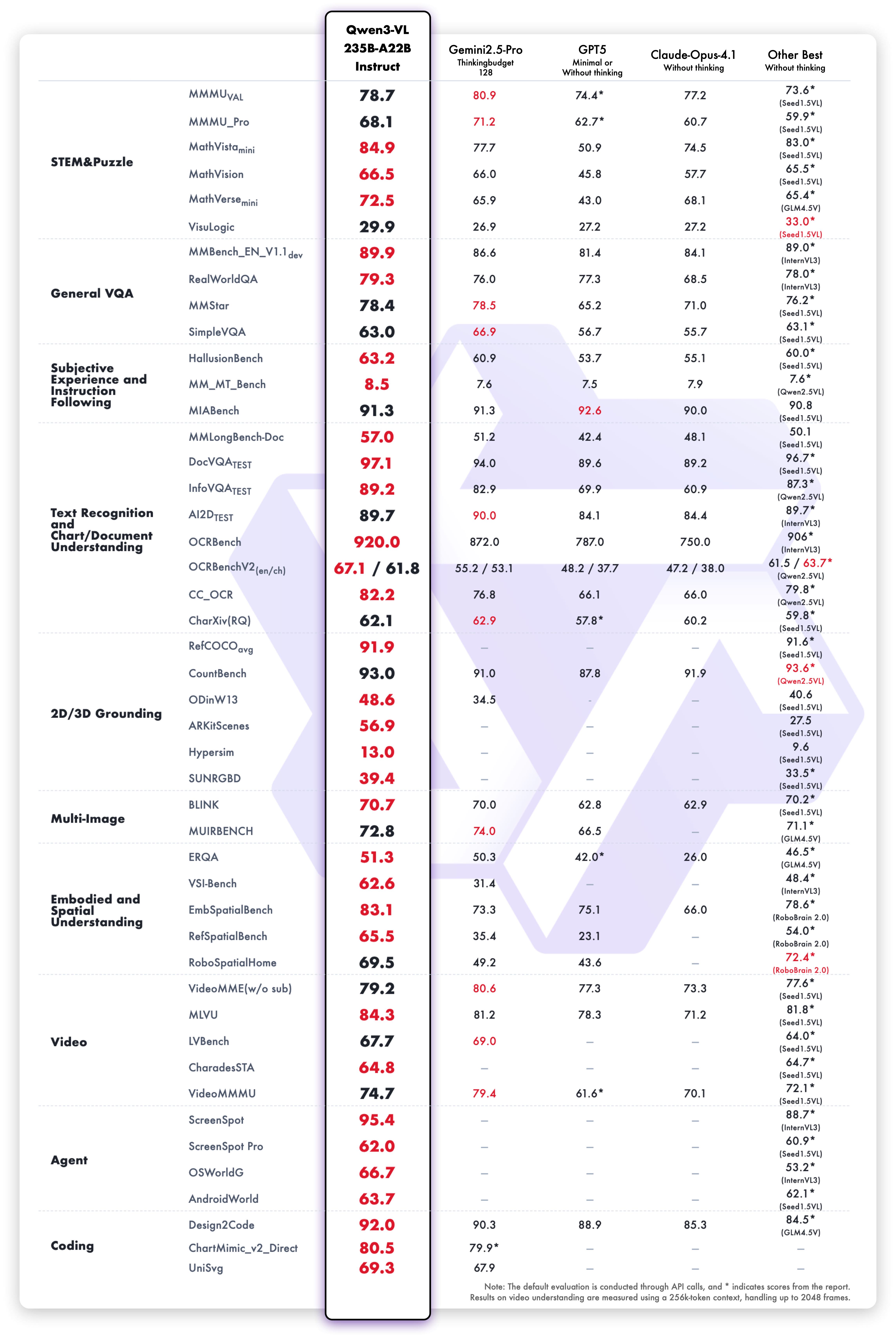
Performances de compréhension et de génération de texte de la variante Instruct :
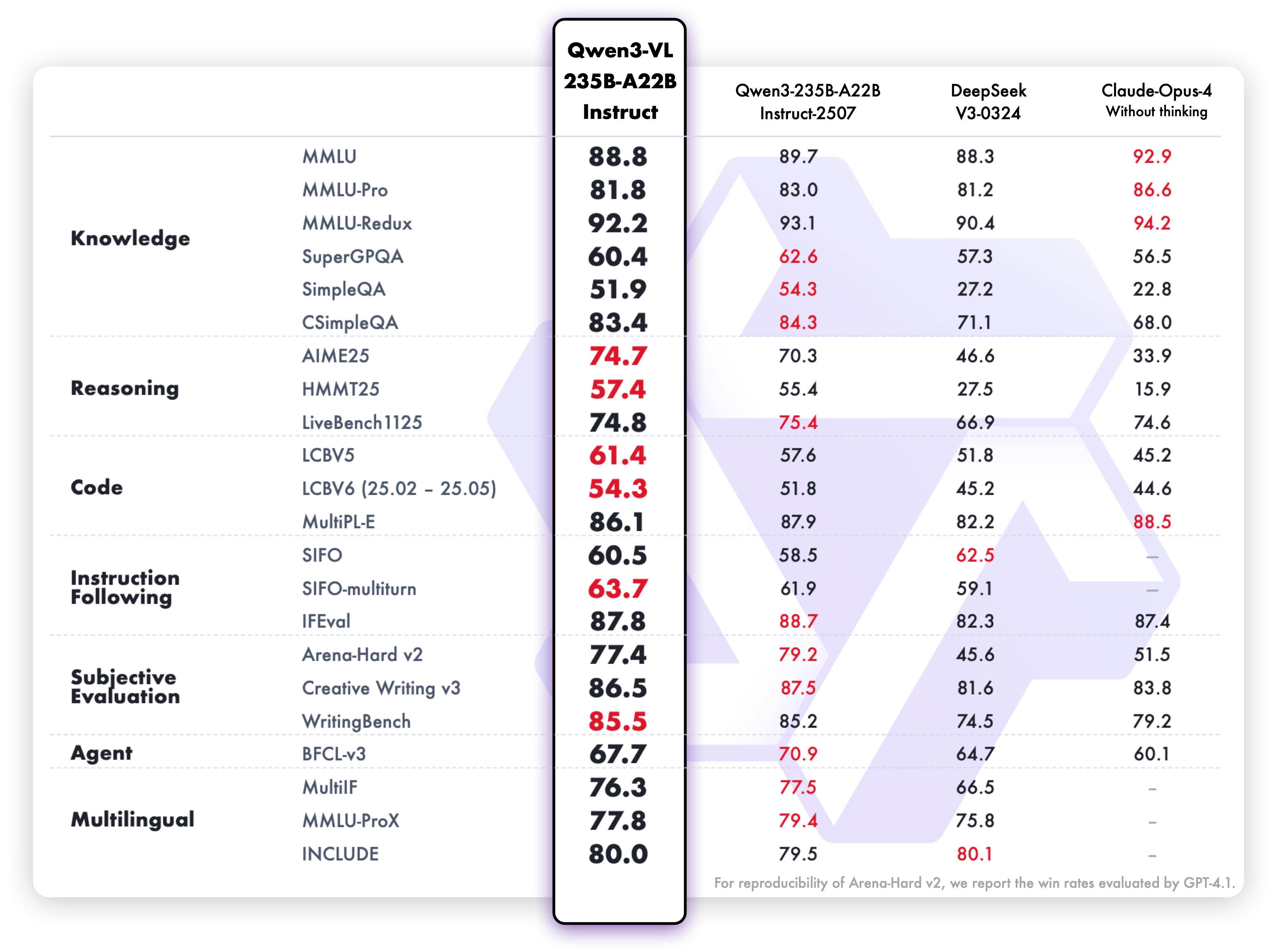
Ces résultats de benchmark mettent en évidence les capacités exceptionnelles du modèle en compréhension multimodale, raisonnement et génération de texte sur des critères d’évaluation variés. Les deux variantes démontrent de solides performances dans leurs domaines respectifs, ce qui les rend très efficaces pour les cas d’usage auxquels elles sont destinées.
Démarrage avec Qwen3-VL-235B-A22B sur la plateforme Novita AI
L’accès à Qwen3-VL-235B-A22B via Novita AI propose plusieurs voies adaptées à différents niveaux d’expertise technique et cas d’usage. Que vous soyez un utilisateur professionnel explorant les capacités de l’IA ou un développeur construisant des applications de production, Novita AI vous fournit les outils dont vous avez besoin.
Utiliser le playground (disponible dès maintenant – aucun code requis)
- Accès instantané : Inscrivez-vous et commencez à expérimenter avec les modèles Qwen3-VL-235B-A22B en quelques secondes
- Interface interactive : Testez des prompts et visualisez les sorties en temps réel
- Comparaison de modèles : Comparez Qwen3-VL-235B-A22B avec d’autres modèles leaders pour votre cas d’usage spécifique
Le playground vous permet de tester différents prompts et d’obtenir des résultats immédiats sans aucune configuration technique. Parfait pour le prototypage, le test d’idées et la compréhension des capacités du modèle avant une mise en œuvre complète.
Intégration via API (disponible et prêt – pour les développeurs)
Connectez Qwen3-VL-235B-A22B à vos applications avec l’API REST unifiée de Novita AI.
Option 1 : Intégration API directe (exemple Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2 : Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents sophistiqués en exploitant les capacités avancées de Qwen3-VL-235B-A22B :
- Intégration plug-and-play : Utilisez Qwen3-VL-235B-A22B dans tout flux de travail OpenAI Agents
- Capacités d’agents avancées : Prise en charge des transferts, du routage et de l’intégration d’outils avec compréhension visuelle
- Architecture évolutive : Concevez des agents qui exploitent les capacités multimodales de Qwen3-VL-235B-A22B
Option 3 : Connexion avec des plateformes tierces
Outils de développement : Intégrez-vous de manière transparente avec les IDE et environnements de développement populaires comme Cursor, Trae, Qwen Code et Cline via des API compatibles OpenAI et des API compatibles Anthropic.
Frameworks d’orchestration : Connectez-vous avec LangChain, Dify, CrewAI, Langflow et autres plateformes d’orchestration IA en utilisant les connecteurs officiels.
Intégration Hugging Face : Novita AI est un fournisseur d’inférence officiel de Hugging Face, garantissant une compatibilité large avec l’écosystème.
Cas d’usage et applications
Développement d’agents visuels
Exploitez les capacités d’agent visuel pour construire des applications capables d’interagir avec des interfaces graphiques, d’automatiser des flux de travail et d’accomplir des tâches complexes grâce à la compréhension visuelle.
Codage et développement visuels
Utilisez l’amélioration de codage visuel pour générer du code HTML, CSS, JavaScript et des diagrammes Draw.io à partir d’entrées visuelles, accélérant ainsi les flux de travail de développement.
Analyse de documents et de vidéos
Tirez parti de la longueur de contexte de 256K tokens et des capacités OCR améliorées pour un traitement complet de documents et une analyse de contenu vidéo.
Applications STIM et éducatives
Appliquez le raisonnement multimodal amélioré pour des applications de technologie éducative, d’analyse scientifique et de résolution de problèmes mathématiques.
Applications de raisonnement spatial
Implémentez les capacités de perception spatiale avancées pour la robotique, les systèmes autonomes et les applications nécessitant une compréhension 3D.
Conclusion
Qwen3-VL-235B-A22B sur Novita AI offre les capacités vision-langage les plus avancées disponibles aujourd’hui, avec les deux variantes Instruct et Thinking proposant des options de déploiement flexibles pour des applications variées. Les améliorations complètes en perception visuelle, raisonnement et capacités d’agents, combinées à un contexte étendu et une compréhension multimodale supérieure, en font le choix définitif pour le développement d’IA de pointe.
Commencez dès aujourd’hui à explorer les capacités révolutionnaires de Qwen3-VL-235B-A22B sur Novita AI et découvrez l’avenir de l’IA vision-langage avec notre plateforme adaptée aux développeurs et nos options d’intégration transparentes.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle des projets.



