

Qwen3-VL-235B-A22BがNovita AIプラットフォームで利用可能になりました。最適化されたインフラを通じて、Qwenシリーズ中最強の視覚言語モデルを開発者に提供します。今回の世代では全面的なアップグレードが行われており、優れたテキスト理解・生成能力、より深い視覚認識・推論能力、拡張されたコンテキスト長、空間・動画ダイナミクスの理解力の向上、エージェント連携能力の強化が図られています。
Instruct版と推論能力を強化したThinking版の2種類を用意しており、多様なアプリケーションに向けて柔軟なオンデマンドデプロイを提供します。ビジュアルAIアプリケーションの開発、自動化ソリューションの構築、高度なマルチモーダル機能の探索のいずれにおいても、Novita AI上のQwen3-VL-235B-A22Bは開発者に優しい統合機能とともに、必要なツールを提供します。
Qwen3-VL-235B-A22Bとは?
Qwen3-VL-235B-A22Bは、Qwenシリーズでこれまでで最も強力な視覚言語モデルです。今回の世代では全面的なアップグレードが行われており、優れたテキスト理解・生成能力、より深い視覚認識・推論能力、拡張されたコンテキスト長、空間・動画ダイナミクスの理解力の向上、エージェント連携能力の強化が図られています。エッジからクラウドまでスケーラブルなDenseアーキテクチャとMoEアーキテクチャを用意し、Instruct版と推論能力を強化したThinking版で柔軟なオンデマンドデプロイを提供します。本モデルは高度な視覚理解と洗練された推論能力を組み合わせることで、マルチモーダルAI能力の大きな進歩を表しています。
2つのバリアントは同じコアアーキテクチャを利用していますが、用途に応じて最適化されています - Instruct版は直接的なタスク完了や対話型アプリケーション向け、Thinking版は複雑な問題解決シナリオ向けに強化された推論能力を提供します。
主な強化点
ビジュアルエージェント:PC/モバイルのGUIを操作し、要素を認識、機能を理解、ツールを呼び出し、タスクを完了します。この画期的な機能により、モデルがグラフィカルユーザーインターフェースと直接対話できるようになり、複雑なワークフローの自動化や、ソフトウェアアプリケーションをナビゲート・制御できる高度なAIエージェントの構築が可能になります。
ビジュアルコーディング機能の強化:画像・動画からDraw.io/HTML/CSS/JSを生成します。モデルがビジュアルデザインやモックアップを分析して対応するコードを自動生成するため、開発ワークフローを大幅に加速し、ビジュアル入力からのAI支援コーディングを実現します。
高度な空間認識:物体の位置、視点、遮蔽を判定し、より強力な2Dグラウンディングを提供し、空間推論や身体化AI向けの3Dグラウンディングを可能にします。この強化により、ロボット工学、自律システム、高度な空間理解を必要とするアプリケーションにおいて特に価値のあるモデルとなります。
長コンテキスト・動画理解:ネイティブで256Kのコンテキスト長をサポートし、1Mまで拡張可能。書籍や数時間に及ぶ動画を完全な記憶と秒単位のインデックス作成で処理します。この機能により、長文のドキュメントや長い動画コンテンツの包括的な分析を、シーケンス全体のコンテキストを維持したまま行うことができます。
マルチモーダル推論の強化:STEM/数学分野で優れた性能を発揮し、因果分析や論理的・証拠に基づいた回答を提供します。視覚情報とテキスト情報に基づいた詳細な分析レスポンスを提供することで、科学・数学の推論タスクで優れた性能を発揮します。
ビジュアル認識機能のアップグレード:より広範で高品質な事前学習により、「あらゆるものを認識可能」になりました - 有名人、アニメ、製品、ランドマーク、動植物などです。この包括的な認識機能により、多様なビジュアルコンテンツの種類やドメイン全体で堅牢な性能を発揮します。
OCR機能の拡張:32言語をサポート(従来の19言語から増加)。低光量、ぼやけ、傾きにも頑健に対応し、珍しい文字・古代文字・専門用語の認識精度が向上。長文ドキュメントの構造解析も改善されました。強化された光学文字認識機能により、ドキュメント処理やテキスト抽出タスクで高い効果を発揮します。
純粋なLLMと同等のテキスト理解:シームレスなテキスト・視覚融合により、損失のない統合的理解を実現します。専用の言語モデルと同等のテキスト処理能力を維持しつつ、優れたマルチモーダル理解能力を発揮します。
モデルアーキテクチャのアップデート
Interleaved-MRoPE
堅牢な位置エンコーディングを介して時間・幅・高さの全周波数割り当てを行い、長い動画の推論能力を強化します。このアーキテクチャの革新により、動画コンテンツの時間的シーケンスの処理・理解能力が大幅に向上します。
DeepStack 特徴融合
マルチレベルViT特徴を融合して細部の詳細を捉え、画像とテキストのアライメントを高精度化します。DeepStackアーキテクチャは視覚情報とテキスト情報の最適な統合を保証し、全体的なマルチモーダル性能を向上させます。
テキスト・タイムスタンプアライメント
T-RoPEを超えて、正確なタイムスタンプに基づいたイベント局所化を実現し、動画の時間的モデリングを強化します。この先進的なアプローチにより、動画コンテンツの時間的理解とイベント局所化の精度が向上します。
利用可能なモデルバリアント
Qwen3-VL-235B-A22B-Instruct
これはQwen3-VL-235B-A22B-Instructの重みリポジトリです。Instructバリアントは直接的なタスク完了と対話型アプリケーション向けに最適化されており、ユーザーのクエリやコマンドに即座に応答します。本モデルは、マルチモーダル入力に対して迅速かつ正確な応答が求められるシナリオで特に優れた性能を発揮します。
Qwen3-VL-235B-A22B-Thinking
これはQwen3-VL-235B-A22B-Thinkingの重みリポジトリです。Thinkingバリアントは強化された推論能力を搭載しており、詳細な分析と段階的な推論を必要とする複雑な問題解決タスクに最適です。本モデルは、深い分析的思考と包括的な評価を必要とするアプリケーションにおいて特に価値があります。
パフォーマンスベンチマーク
Qwen3-VL-235B-A22Bは、Instructバリアント・Thinkingバリアントの両方で複数のドメインで卓越した性能を発揮し、視覚言語理解能力と推論能力の大幅な向上を示しています。
Thinkingバリアントのパフォーマンス
Qwen3-VL-235B-A22B-Thinkingモデルは、視覚言語ベンチマークで際立った結果を出しています:
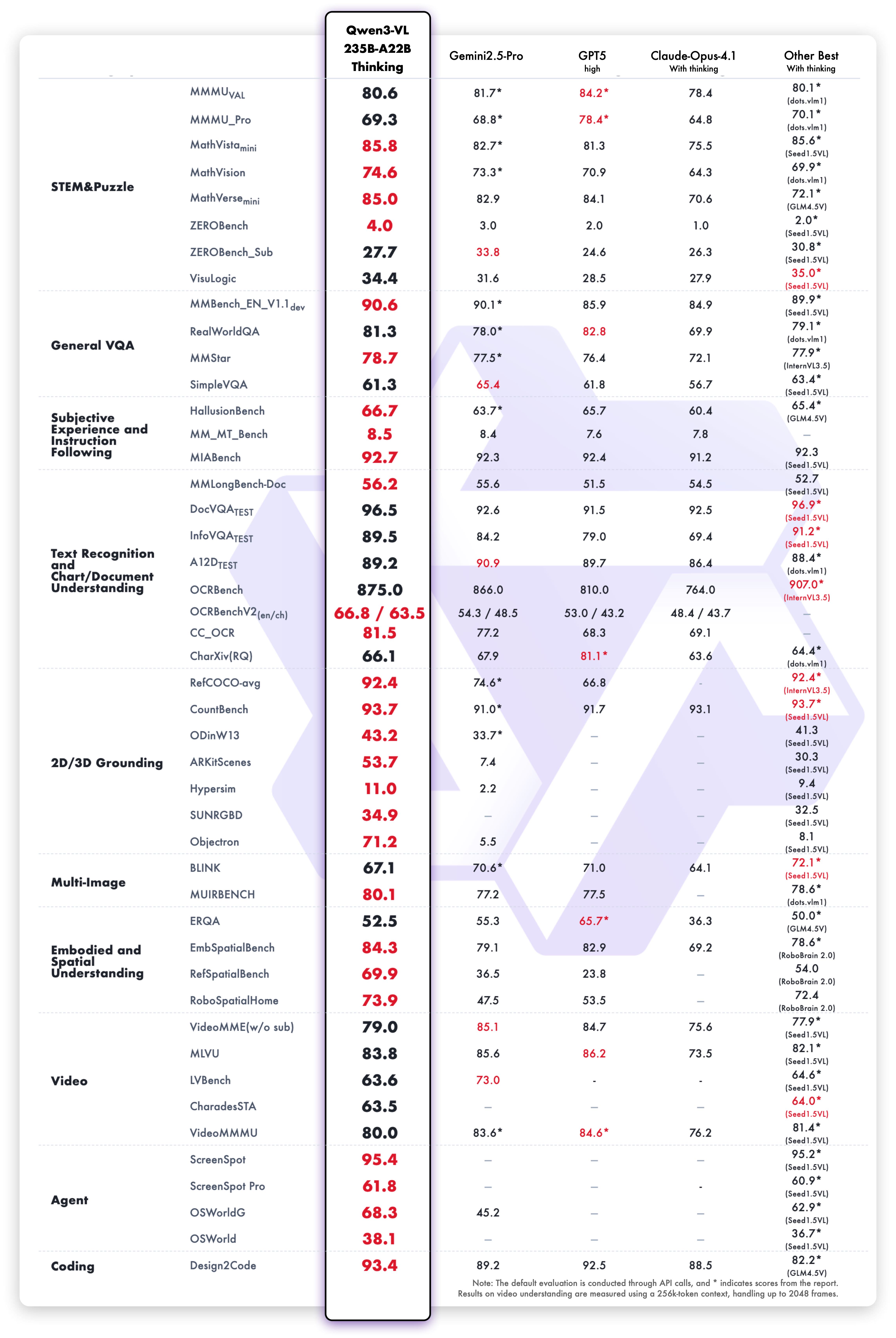
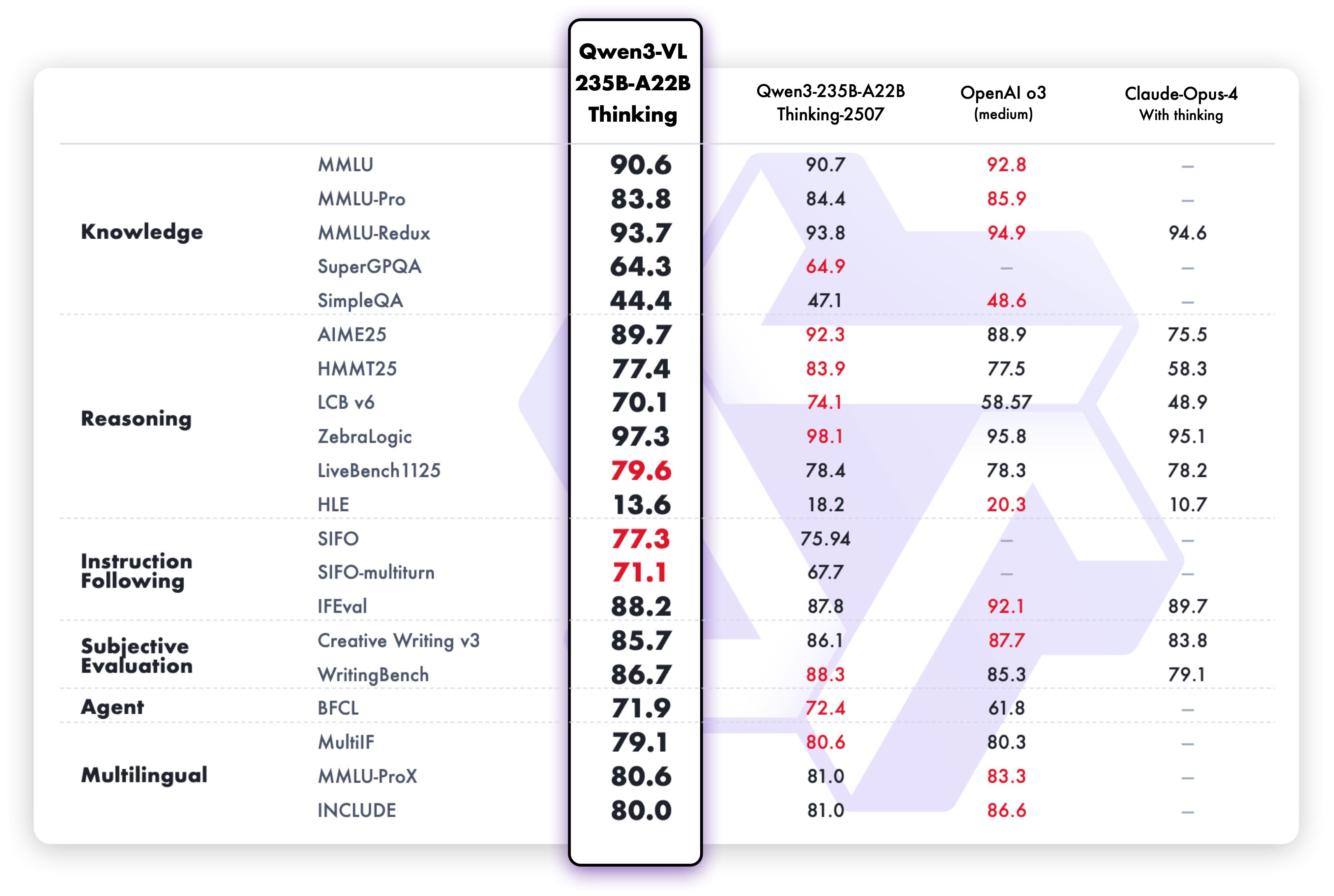
Thinkingバリアントのテキスト推論能力は優れた性能を発揮します:
Instructバリアントのパフォーマンス
Qwen3-VL-235B-A22B-Instructモデルは、視覚言語評価指標で競争力のある結果を達成しています:
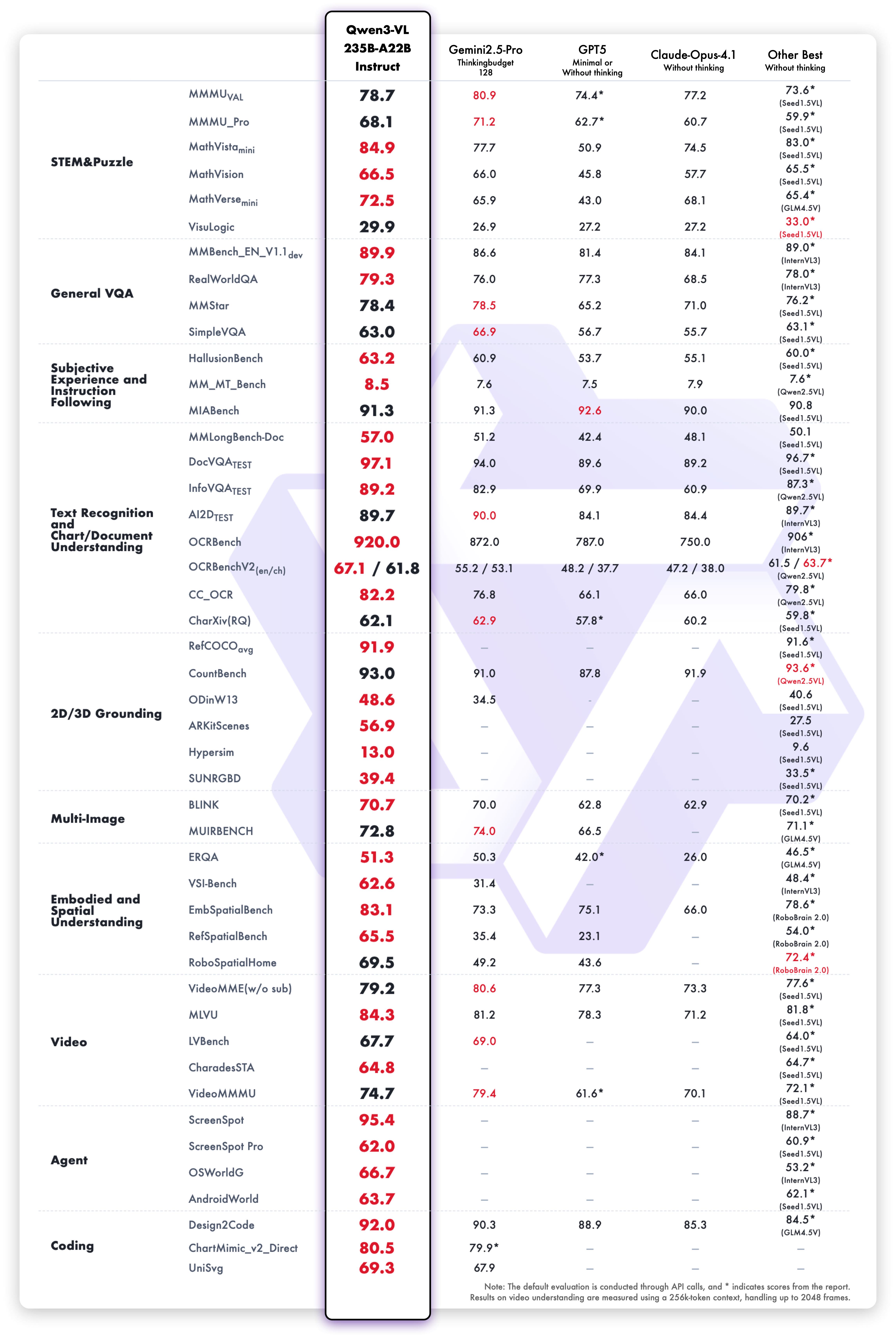
Instructバリアントのテキスト理解・生成性能:
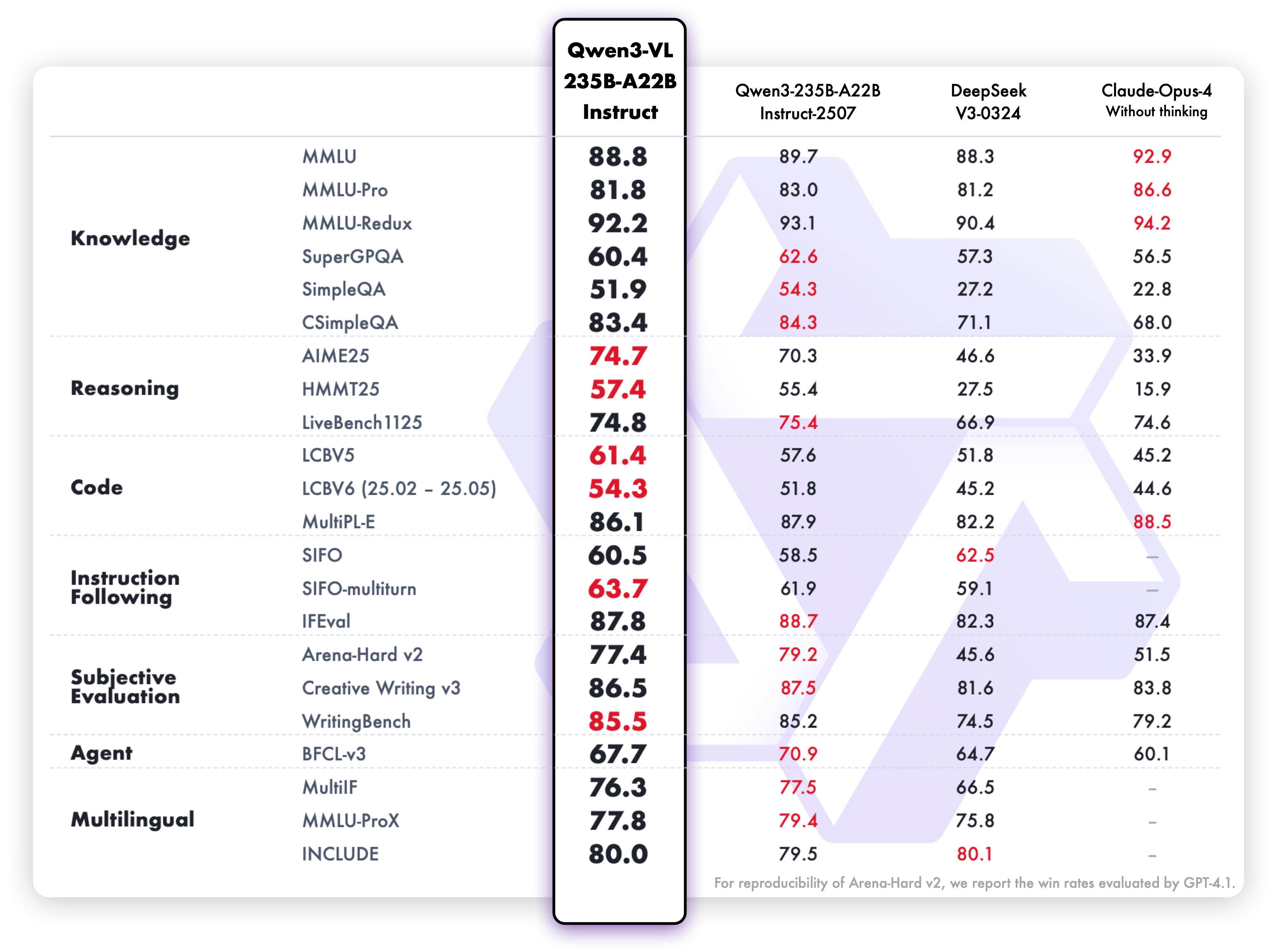
これらのベンチマーク結果は、多様な評価基準におけるマルチモーダル理解、推論、テキスト生成の優れた能力を強調しています。両バリアントはそれぞれの分野で高い性能を発揮し、想定される用途に対して非常に効果的です。
Novita AIプラットフォームでQwen3-VL-235B-A22Bを始める
Novita AIを通じてQwen3-VL-235B-A22Bを利用するには、技術的専門知識のレベルや用途に合わせた複数の方法が用意されています。AI機能を探索するビジネスユーザーでも、本番環境のアプリケーションを構築する開発者でも、Novita AIは必要なツールを提供します。
プレイグラウンドを利用する(今すぐ利用可能 - コーディング不要)
- 即時アクセス:数秒でサインアップしてQwen3-VL-235B-A22Bモデルの実験を開始できます
- 対話型インターフェース:プロンプトをテストし、結果をリアルタイムで視覚化できます
- モデル比較:特定の用途に向けてQwen3-VL-235B-A22Bを他の主要モデルと比較できます
プレイグラウンドでは、技術的なセットアップなしにさまざまなプロンプトをテストして即座に結果を確認できます。プロトタイピング、アイデアの検証、本番実装前にモデルの能力を理解するのに最適です。
APIを介して統合する(本番運用可能 - 開発者向け)
Novita AIの統合REST APIを使用して、Qwen3-VL-235B-A22Bをアプリケーションに接続できます。
オプション1:直接API統合(Python例)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
オプション2:OpenAI Agents SDKを使用したマルチエージェントワークフロー
Qwen3-VL-235B-A22Bの高度な機能を活用して、高度なマルチエージェントシステムを構築できます:
- プラグアンドプレイ統合:任意のOpenAI AgentsワークフローでQwen3-VL-235B-A22Bを利用できます
- 高度なエージェント機能:視覚理解を備えたハンドオフ、ルーティング、ツール統合をサポートします
- スケーラブルなアーキテクチャ:Qwen3-VL-235B-A22Bのマルチモーダル機能を活用するエージェントを設計できます
オプション3:サードパーティプラットフォームとの連携
開発ツール:OpenAI互換APIやAnthropic互換APIを介して、Cursor、Trae、Qwen Code、Clineなどの人気IDEや開発環境とシームレスに統合できます。
オーケストレーションフレームワーク:公式コネクタを使用して、LangChain、Dify、CrewAI、LangflowなどのAIオーケストレーションプラットフォームと接続できます。
Hugging Faceとの統合:Novita AIはHugging Faceの公式推論プロバイダーであり、幅広いエコシステム互換性を保証します。
ユースケースとアプリケーション
ビジュアルエージェント開発
ビジュアルエージェント機能を活用して、GUIと対話し、ワークフローを自動化し、視覚的理解を通じて複雑なタスクを完了するアプリケーションを構築できます。
ビジュアルコーディングと開発
ビジュアルコーディング強化機能を利用して、ビジュアル入力からHTML、CSS、JavaScript、Draw.io図を生成し、開発ワークフローを加速できます。
ドキュメント・動画分析
256Kのコンテキスト長と強化されたOCR機能を活用して、ドキュメント処理と動画コンテンツ分析を包括的に行えます。
STEM・教育アプリケーション
強化されたマルチモーダル推論を活用して、教育技術、科学分析、数学の問題解決アプリケーションを構築できます。
空間推論アプリケーション
高度な空間認識機能を実装して、ロボット工学、自律システム、3D理解を必要とするアプリケーションを構築できます。
まとめ
Novita AI上のQwen3-VL-235B-A22Bは、現在利用可能な最も高度な視覚言語機能を提供します。InstructバリアントとThinkingバリアントの両方が多様なアプリケーション向けの柔軟なデプロイオプションを提供し、視覚認識、推論、エージェント機能の包括的な強化、拡張されたコンテキスト長、優れたマルチモーダル理解能力の組み合わせにより、最先端のAI開発における最適な選択肢となります。
今すぐNovita AIでQwen3-VL-235B-A22Bの革新的な機能を探索し、開発者に優しいプラットフォームとシームレスな統合オプションで視覚言語AIの未来を体験してください。
Novita AIは、シンプルなAPIを使用してAIモデルを簡単にデプロイできる方法を開発者に提供するとともに、構築・スケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。



