

Der LLM-Dedicated-Endpoint von Novita AI ist ein neu eingeführter Dienst, der Ihnen die einfache Bereitstellung eigener oder feinabgestimmter Hugging Face-Modelle ermöglicht.
Mit dedizierten H100-GPUs ab 1,86 $/Std. und H200 ab 2,99 $/Std. bietet Novita AI hoch wettbewerbsfähige Preise – oft kostengünstiger als Alternativen wie Together AI, Fireworks AI und Friendli AI.
Profitieren Sie von flexibler LoRA-Unterstützung, einer Verfügbarkeitsgarantie von 99,5 % und skalierbaren GPU-Optionen. Richten Sie in Minuten produktionsreife LLM-Endpunkte ein und verwalten Sie Ihre Ressourcen dank transparenter, vorhersagbarer Preise zuversichtlich.
Was ist ein LLM-Dedicated-Endpoint?
Ein LLM-Dedicated-Endpoint stellt eine private, cloudbasierte API zum Ausführen großer Sprachmodelle auf einer ausschließlich für Ihre Nutzung reservierten Infrastruktur bereit. Dieses Setup gewährleistet, dass Ihre Modelle mit gleichbleibender Leistung, hoher Zuverlässigkeit und vollständiger Ressourcenisolierung arbeiten – anders als bei geteilten oder serverlosen Alternativen.
Mit einem dedizierten Endpoint können Sie sowohl Open-Source- als auch private Modelle auf Hugging Face bereitstellen, einschließlich Ihrer eigenen oder feinabgestimmten Varianten. Sensible Daten und geistiges Eigentum bleiben geschützt, da Ihre Modelle und Ihr Datenverkehr niemals anderen Benutzern ausgesetzt werden.
Warum den LLM-Dedicated-Endpoint wählen?
Mit dem LLM-Dedicated-Endpoint von Novita AI erhalten Sie eine robuste und flexible Umgebung für Ihre KI-Workloads:
- Bereitstellung benutzerdefinierter Modelle: Stellen Sie mühelos jedes Hugging Face-Modell bereit, einschließlich privater und feinabgestimmter Versionen, in einer isolierten, dedizierten Umgebung.
- Flexibles LoRA-Adapter-Management: Fügen Sie mehrere LoRA-Adapter an einem einzigen Endpoint hinzu und wechseln Sie zwischen ihnen. Experimentieren Sie, iterieren Sie und unterstützen Sie verschiedene Aufgaben, ohne Ihr Basismodell neu bereitzustellen.
- Vorhersagbare Leistung: Dedizierte Ressourcen sorgen für konsistenten Durchsatz und niedrige Latenz, unbeeinflusst von anderen Benutzern. Es gibt keine harten Ratenbegrenzungen; die Kapazität Ihres Endpoints wird durch Ihre gewählte Hardware und Konfiguration bestimmt.
- Skalierbare Hardware: Skalieren Sie von Leerlauf (0 Replikate) auf bis zu 10 Replikate pro Endpoint und wählen Sie den GPU-Typ, der Ihren Anforderungen entspricht. Jeder Benutzer kann auf bis zu 8 GPUs zugreifen, mit Möglichkeit zur Unternehmenserweiterung.
- Transparente Preise: H100 ab 1,86 $/Std., H200 ab 2,99 $/Std. – Sie zahlen nur für das, was Sie nutzen. Dedizierte Endpoints sind bei hoher oder dauerhafter Nutzung oft kostengünstiger als serverlose Lösungen.
- Benutzerfreundliche Verwaltung: Intuitive Weboberfläche für Bereitstellung und Verwaltung sowie sofortiges Testen im Playground zur schnellen Validierung.
- Produktionsreife Zuverlässigkeit: 99,5 % Verfügbarkeitsgarantie, vollständig von Novita AI verwaltet für ein sorgenfreies Erlebnis.
Auswahlhilfe: Dedicated Endpoint vs. Serverless Endpoint
Die Wahl des richtigen Typs von LLM-Inferenz-Endpoint hängt von Ihrem Anwendungsfall, Ihrer Workload und Ihren betrieblichen Anforderungen ab. Hier eine Kurzanleitung für Ihre Entscheidung:
Wählen Sie den LLM-Serverless-Endpoint, wenn:
- Sie schnellen, flexiblen Zugriff auf öffentliche LLMs ohne Infrastrukturverwaltung wünschen.
- Ihre Nutzung gering, variabel oder für Prototypen ist.
- Sie eine einfache, nutzungsbasierte Abrechnung wünschen.
Wählen Sie den LLM-Dedicated-Endpoint, wenn:
- Sie ein beliebiges Hugging Face-Modell (einschließlich privater, feinabgestimmter oder gated-Modelle) bereitstellen möchten.
- Sie LoRA-Adapter und -Parameter flexibel konfigurieren müssen.
- Sie dedizierte Hardware, stabilen hohen Durchsatz und Produktionszuverlässigkeit benötigen.
- Sie die niedrigsten GPU-Kosten der Branche erzielen möchten.
- Sie bis zu 8 GPUs pro Benutzer oder mehr benötigen.
Falls Sie mehr Ressourcen benötigen, kontaktieren Sie bitte unser Vertriebsteam für eine individuelle Unternehmenslösung.
| Aspekt | LLM-Serverless-Endpoint | LLM-Dedicated-Endpoint (DE) |
| Abrechnungsmodell | Nutzungsbasiert (pro Token) | Pro GPU pro Stunde |
| Ressourcentyp | Geteilt, serverlos (Multi-Tenant) | Dediziert, benutzergesteuert (Single-Tenant) |
| Leistungskonsistenz | Kann schwanken (geteilte Last) | Vorhersagbar, nicht von anderen Benutzern beeinflusst |
| Ratenbegrenzungen | Ja (TPM, RPM je nach Benutzerstufe) | Keine harten Begrenzungen; begrenzt durch GPU-Kontingent des Benutzers |
| Modellauswahl | Nur öffentliche Modelle | Laden benutzerdefinierter Basismodelle aus Hugging Face-Repos (öffentlich, privat oder gated); unterstützt LoRA-Parameterkonfiguration |
| Hardware-Auswahl | Nicht wählbar | Flexibel: H100, H200, 4090 usw. |
| Bereitstellungsregion | Nicht vom Benutzer wählbar | Benutzer kann Region wählen |
| SLA | Keine formelle Garantie | 99,5 % SLA |
| Kosten bei hoher Auslastung | Teurer im großen Maßstab | Günstiger bei hoher Auslastung |
| Sicherheit & Datenisolierung | Geteilte Umgebung | Vollständige Mandantentrennung, private Endpoints |
| Am besten geeignet für | Startups, Prototyping, schwankende Nutzung | Unternehmen, Produktion, stabiler hoher Durchsatz, benutzerdefinierte Basismodelle |
GPU-Preisvergleich für Dedicated Endpoints
Bei der Wahl eines Anbieters ist die Kosteneffizienz entscheidend – insbesondere für produktionsnahe Bereitstellungen. Novita AI bietet die niedrigsten Stundensätze für dedizierte H100- und H200-GPUs unter den führenden Anbietern:
| Anbieter | H100 (1 Karte/h) | H200 (1 Karte/h) |
| Novita AI | 1,86 $ | 2,99 $ |
| Fireworks AI | 5,80 $ | 9,99 $ |
| Friendli AI | 4,90 $ | 5,90 $ |
| Together AI | 3,36 $ | 4,99 $ |
| Deepinfra | 2,40 $ | 3,00 $ |
Wie oben zu sehen, bietet Novita AI durchweg die wettbewerbsfähigsten Preise für sowohl H100- als auch H200-GPUs – bis zu 60 % günstiger als andere bekannte Anbieter.
Das bedeutet, dass Sie Ihre Infrastrukturkosten für durchsatzstarke oder langlebige LLM-Bereitstellungen durch die Wahl von Novita AI erheblich senken können.
Erste Schritte mit den LLM-Dedicated-Endpoints von Novita AI
1. Auf die Konsole zugreifen
- Melden Sie sich bei Ihrer Novita AI Console an.
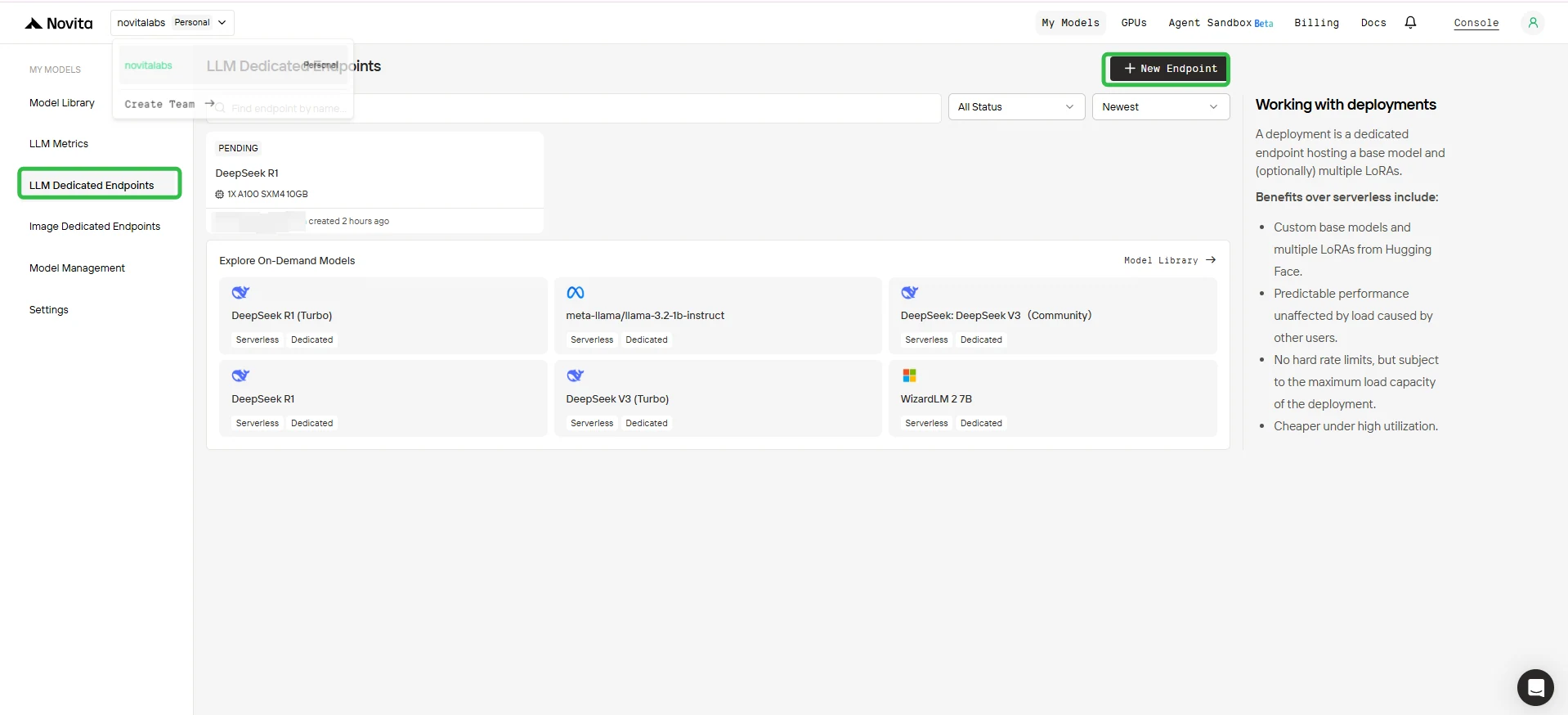
- Klicken Sie in der linken Seitenleiste auf LLM Dedicated Endpoints.
2. Einen neuen Endpoint erstellen
- Klicken Sie auf die Schaltfläche + New Endpoint in der oberen rechten Ecke.
3. Endpoint konfigurieren
Füllen Sie das Konfigurationsformular mit den folgenden Optionen aus:
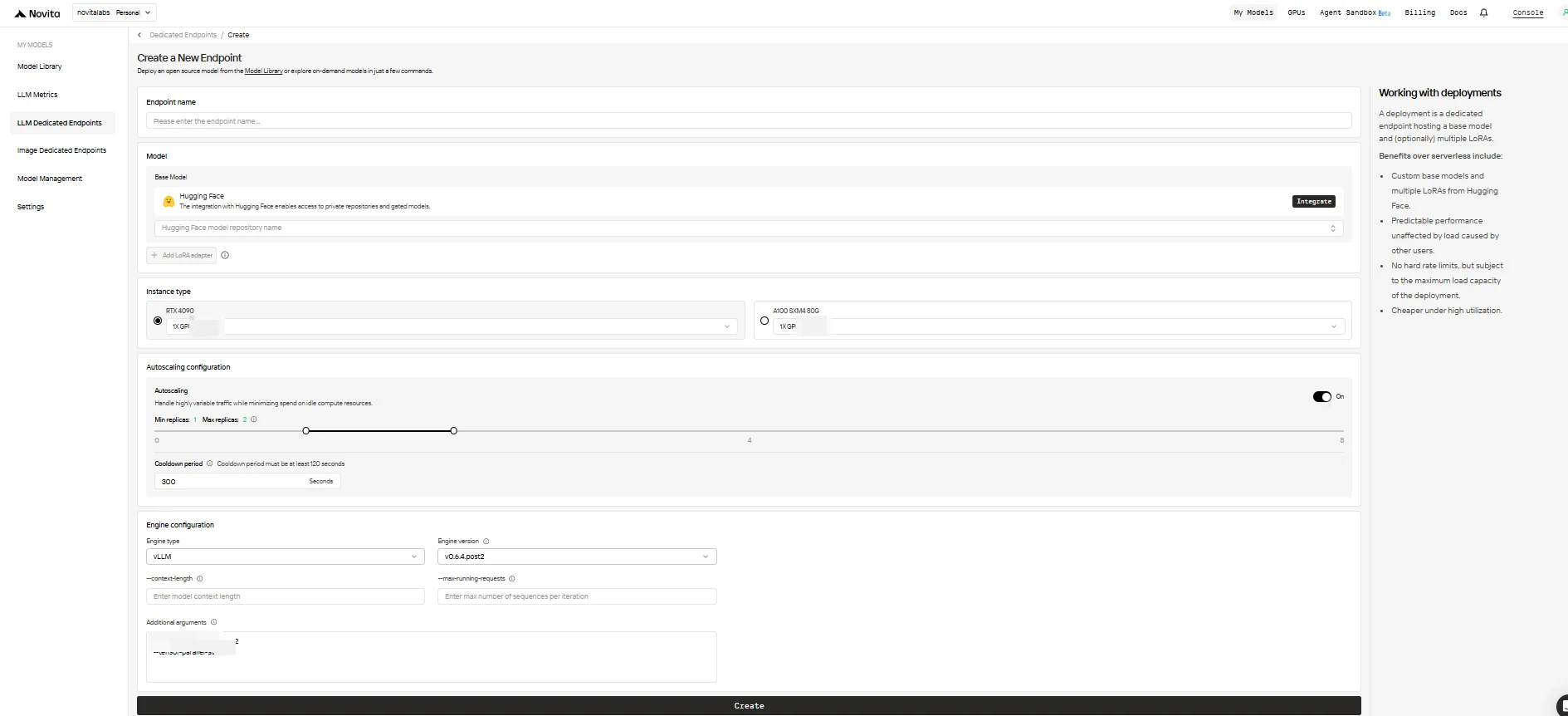
-
Endpoint Name: Geben Sie Ihrem Deployment einen eindeutigen und beschreibenden Namen.
-
Base Model: Geben Sie den Hugging Face-Repository-Namen für Ihr Basismodell ein (nur Hugging Face-Modelle werden unterstützt, einschließlich öffentlicher, privater oder gated-Modelle).
-
LoRA Adapters (optional): Fügen Sie eine oder mehrere Hugging Face-Modell-IDs hinzu, um LoRA-Adapter an Ihr Basismodell anzuhängen.
-
Instance Type: Wählen Sie die GPU-Hardware (z. B. H100, H200, RTX4090). Jeder Benutzer kann bis zu 8 GPUs über alle Endpoints hinweg nutzen.
-
Autoscaling-Konfiguration:
- Minimum Replicas: Setzen Sie
0, damit der Endpoint im Leerlauf in den Ruhezustand wechseln kann (Kosteneinsparung), oder einen höheren Wert, um immer eine Mindestanzahl aktiver Replikate zu halten. - Maximum Replicas: Legen Sie die maximale Anzahl von Replikaten für die Skalierung fest (bis zu 10).
- Cooldown Period: Geben Sie die Verzögerung (in Sekunden) vor dem Herunterskalieren von Replikaten an, um ein vorzeitiges Herunterskalieren bei kurzzeitigen Verkehrseinbrüchen zu vermeiden.
- Minimum Replicas: Setzen Sie
-
Engine-Konfiguration:
- Engine Type: Wählen Sie die Inferenz-Engine (
vLLModerSGLang). - Engine Version: Verwenden Sie die Standardeinstellung (neueste) oder geben Sie eine Version an.
- Context Length: Optional: Legen Sie die maximale Token-Kontextlänge fest; falls nicht angegeben, wird sie aus der Modellkonfiguration abgeleitet.
- Max Running Requests: Legen Sie die maximale Anzahl von Sequenzen fest, die pro Iteration verarbeitet werden.
- Additional Arguments: Fügen Sie zusätzliche Engine-Parameter für erweiterte Anpassungen hinzu.
- Engine Type: Wählen Sie die Inferenz-Engine (
Wenn Sie fertig sind, klicken Sie auf Create, um Ihren Endpoint bereitzustellen.
4. Bereitstellungsstatus des Endpoints
Nach der Erstellung durchläuft Ihr Endpoint mehrere Status:
- Sleeping: Der Endpoint ist im Leerlauf und verbraucht keine Rechenressourcen (wenn Minimum Replicas auf 0 gesetzt ist).
- Pending: Die Bereitstellung wird initialisiert.
- Rolling: Das Modell und die Infrastruktur werden eingerichtet.
- Running: Der Endpoint ist aktiv und bereit, Anfragen zu bedienen.
Sie können diesen Status auf der Endpoints-Seite in der Konsole überwachen.
5. Testen Sie Ihren Endpoint im Playground
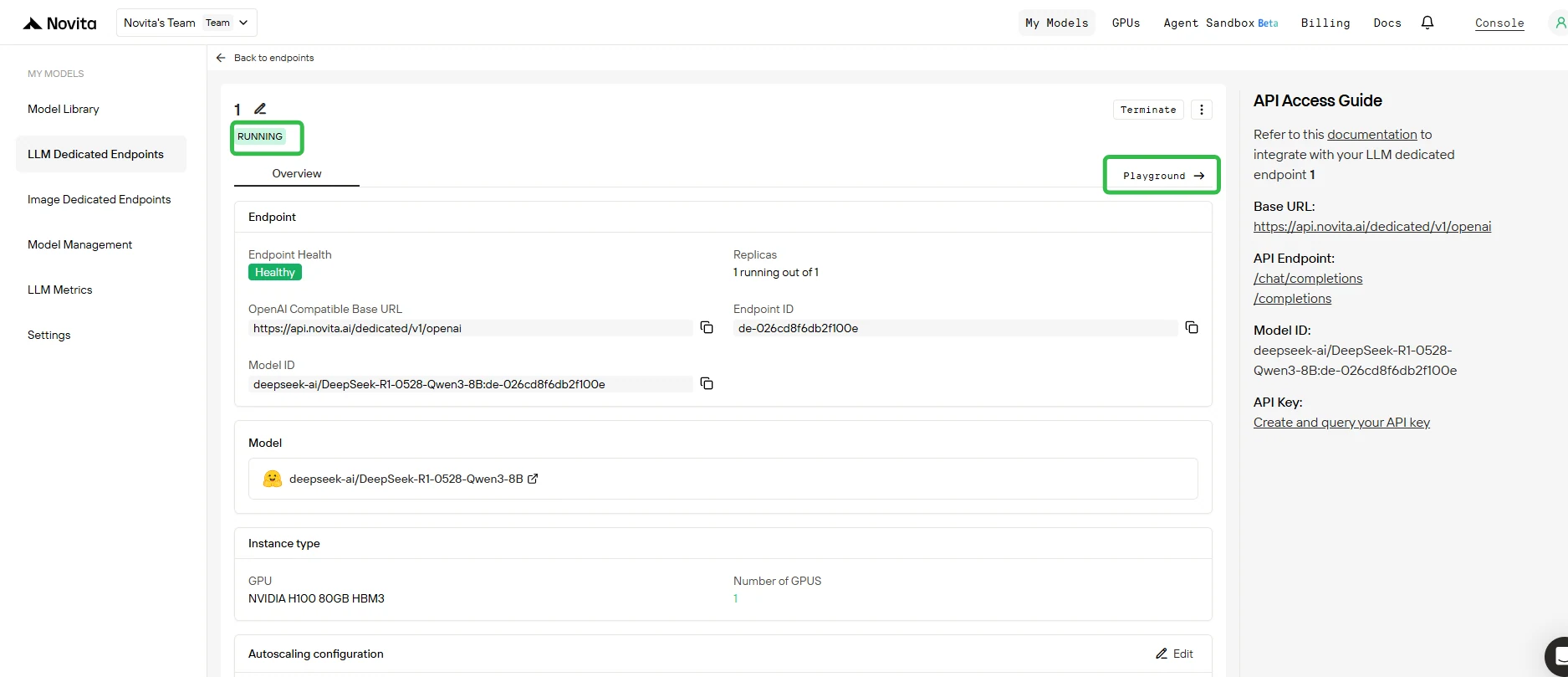
- Sobald die Bereitstellung abgeschlossen ist und der Status Running lautet, klicken Sie auf Ihren Endpoint und öffnen Sie den Tab Playground.
- Im Playground können Sie:
- Test-Prompts an Ihr Basismodell und alle angehängten LoRA-Adapter senden.
- Sofort die Ausgabe verschiedener Adapter im Vergleich zum Basismodell sehen.
6. Nächste Schritte
- Multi-LoRA-Endpoints: Stellen Sie mehrere LoRA-Adapter auf einem einzigen Endpoint bereit, um flexibel zwischen Modellen wechseln zu können.
- API-Integration: Nutzen Sie die bereitgestellten API-Endpunkte, um Anfragen zu senden und Ihr Modell in Ihre eigenen Anwendungen zu integrieren.
- Optimieren und skalieren: Passen Sie Autoscaling, Engine-Konfiguration und GPU-Kontingent an, wenn Ihre Anforderungen wachsen.
- Mehr Ressourcen benötigt? Kontaktieren Sie unser Vertriebsteam für eine Unternehmenslösung, wenn Sie mehr als 8 GPUs benötigen oder Funktionen auf Unternehmensebene wünschen.
Codebeispiele (für Python-Benutzer)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fazit
Der neue LLM-Dedicated-Endpoint von Novita AI ermöglicht es Ihnen, benutzerdefinierte Hugging Face-Modelle sicher bereitzustellen und zu skalieren. Profitieren Sie von der flexiblen LoRA-Adapter-Integration, unkompliziertem Autoscaling, wettbewerbsfähigen transparenten Preisen und der Sicherheit einer 99,5 % SLA. Egal, ob Sie Ihr erstes feinabgestimmtes Modell starten oder Produktions-Workloads verwalten – mit Novita AI wird der Weg vom Prototyp zur Produktion einfach, schnell, sicher und effizient.
Bereit für eine nahtlose LLM-Bereitstellung? Jetzt registrieren oder kontaktieren Sie unser Vertriebsteam für eine Demo und einen maßgeschneiderten Enterprise-Plan.
Häufig gestellte Fragen
Welche Modelle kann ich auf einem Dedicated Endpoint bereitstellen?
Sie können jedes Modell von Hugging Face bereitstellen, einschließlich öffentlicher, privater, feinabgestimmter oder proprietärer Modelle. Sowohl Basismodelle als auch Modelle mit benutzerdefinierten oder LoRA-Adaptern werden unterstützt.
Wie unterscheidet sich ein Dedicated Endpoint von einem Serverless Endpoint?
Ein Dedicated Endpoint bietet reservierte, isolierte Hardware für gleichbleibende Leistung, erweiterte Anpassungsmöglichkeiten und höheren Durchsatz. Serverless Endpoints hingegen laufen auf gemeinsam genutzter Infrastruktur, eignen sich am besten für geringe oder variable Nutzung und sind ideal für schnelles Prototyping ohne Hardwareverwaltung.
Kann ich meinen Dedicated Endpoint skalieren, wenn meine Workload wächst?
Ja. Dedicated Endpoints unterstützen Autoscaling basierend auf der Echtzeit-Nachfrage. Sie können mit einer GPU beginnen und auf bis zu 8 GPUs pro Benutzer skalieren (mit Enterprise-Optionen für mehr), sodass Ihre Anwendungen auch bei Spitzenlast reaktionsfähig bleiben.
Wie überwache und verwalte ich meinen Dedicated Endpoint?
Jeder Dedicated Endpoint wird mit detaillierten Metriken und Protokollen geliefert. Sie können Leistung verfolgen, Nutzung überwachen und Probleme über die Weboberfläche oder die API beheben, was Verwaltung und Optimierung unkompliziert macht.
Welche Preismodelle gibt es und wie kann ich die Kosten kontrollieren?
Die Preisgestaltung ist transparent und nutzungsbasiert, ab 1,86 $/Std. für H100-GPUs und 3,00 $/Std. für H200-GPUs. Sie zahlen nur für das, was Sie nutzen. Autoscaling und flexible Verwaltung helfen Ihnen, die Auslastung zu optimieren und die Kosten vorhersagbar zu halten, insbesondere für Produktions-Workloads.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über eine einfache API bereitzustellen, und dabei eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



