

Novita AIのLLM Dedicated Endpointは、カスタムまたはファインチューニングしたHugging Faceモデルを簡単にデプロイできる新サービスです。
専用H100 GPUが1時間あたり1.86ドルから、H200が2.99ドルからと、Novita AIは非常に競争力のある価格を実現しています。Together AI、Fireworks AI、Friendli AIなどの代替サービスよりもコスト効率が高いことが多いです。
柔軟なLoRAサポート、99.5%のSLA、スケーラブルなGPUオプションをお楽しみいただけます。数分で本番環境対応のLLMエンドポイントをセットアップし、透明で予測可能な価格設定でリソースを自信を持って管理できます。
What is LLM Dedicated Endpoint?
LLM Dedicated Endpoint は、お客様専用のインフラ上で大規模言語モデルを実行するためのプライベートなクラウドベースAPIを提供します。このセットアップにより、共有型やサーバーレスの代替手段とは異なり、モデルは一貫したパフォーマンス、高い信頼性、完全なリソース分離のもとで動作します。
専用エンドポイントを使用すると、オープンソースモデルとプライベートモデルの両方をHugging Faceにデプロイできます。カスタムバリアントやファインチューニングバリアントも含まれます。機密データや知的財産は保護され、モデルとトラフィックが他のユーザーに公開されることはありません。
Why Choose LLM Dedicated Endpoint?
Novita AIのLLM Dedicated Endpointを使用すると、AIワークロード向けの堅牢で柔軟な環境が得られます:
- カスタムモデルのデプロイ: プライベートモデルやファインチューニングモデルを含むあらゆるHugging Faceモデルを、分離された専用環境で簡単に提供できます。
- 柔軟なLoRAアダプター管理: 単一のエンドポイントで複数のLoRAアダプターをアタッチし、切り替えることができます。ベースモデルを再デプロイすることなく、実験、反復、多様なタスクをサポートできます。
- 予測可能なパフォーマンス: 専用リソースにより、他のユーザーの影響を受けることなく、一貫したスループットと低レイテンシーを実現します。ハードなレート制限はなく、エンドポイントの容量は選択したハードウェアと構成によって決まります。
- スケーラブルなハードウェア: アイドル状態(レプリカ0)からエンドポイントあたり最大10レプリカまでスケーリングでき、要件に合ったGPUタイプを選択できます。各ユーザーは最大8GPUまで利用可能で、エンタープライズ向けの拡張も可能です。
- 透明な価格設定: H100は1時間あたり1.86ドルから、H200は2.99ドルから。使用した分だけお支払いいただきます。専用エンドポイントは、高負荷または継続的な使用において、サーバーレスソリューションよりもコスト効率が高いことがよくあります。
- ユーザーフレンドリーな管理: 直感的なWebコンソールでデプロイと管理が可能で、即座にPlaygroundでテストして迅速に検証できます。
- 本番環境対応の信頼性: 99.5%のアップタイム保証、Novita AIによる完全管理で安心です。
How to Choose: Dedicated Endpoint vs. Serverless Endpoint
適切なLLM推論エンドポイントの選択は、ユースケース、ワークロード、運用要件によって異なります。ここでは、決定に役立つ簡単なガイドを紹介します。
次の場合はLLM Serverless Endpointを選択してください:
- インフラ管理なしでパブリックLLMに高速かつ柔軟にアクセスしたい場合。
- 使用量が少ない、変動がある、またはプロトタイピング用途の場合。
- シンプルな従量課金制を希望する場合。
次の場合はLLM Dedicated Endpointを選択してください:
- 任意のHugging Faceモデル(非公開、ファインチューニング、ゲート付きを含む)をデプロイしたい場合。
- LoRAアダプターとパラメーターを柔軟に構成する必要がある場合。
- 専用ハードウェア、安定した高スループット、本番グレードの信頼性が必要な場合。
- 業界最安のGPUコストを実現したい場合。
- ユーザーあたり最大8GPU、またはそれ以上が必要な場合。
より多くのリソースが必要な場合は、営業チームまでお問い合わせいただき、カスタムエンタープライズソリューションをご検討ください。
| 項目 | LLM Serverless Endpoint | LLM Dedicated Endpoint (DE) |
| 課金モデル | 従量課金(トークン単位) | GPU1時間あたりの従量課金 |
| リソースタイプ | 共有、サーバーレス(マルチテナント) | 専用、ユーザー制御(シングルテナント) |
| パフォーマンスの一貫性 | 変動する可能性あり(共有負荷) | 予測可能、他のユーザーの影響を受けない |
| レート制限 | あり(ユーザー階層に応じたTPM、RPM) | ハードなレート制限なし、ユーザーGPUクォータによる制限 |
| モデル選択 | パブリックモデルのみ | Hugging Faceリポジトリからのカスタムベースモデル読み込み(公開、非公開、ゲート付き)、LoRAパラメータ構成対応 |
| ハードウェア選択 | 選択不可 | 柔軟:H100、H200、4090など |
| デプロイリージョン | ユーザー選択不可 | ユーザーがリージョンを選択可能 |
| SLA | 正式な保証なし | 99.5%のSLA |
| 高使用率時のコスト | 大規模になると高コスト | 高使用率ではより安価 |
| セキュリティとデータ分離 | 共有環境 | 完全なテナント分離、プライベートエンドポイント |
| 最適な用途 | スタートアップ、プロトタイピング、変動する使用量 | エンタープライズ、本番環境、安定した高スループット、カスタムベースモデル |
Dedicated Endpoint GPU Price Comparison
プロバイダーを選ぶ際、コスト効率は非常に重要です。特に本番規模のデプロイでは。Novita AIは、主要プロバイダーの中で専用H100およびH200 GPUの最低時間料金を提供しています。
| プロバイダー | H100 (1 card/H) | H200 (1 card/H) |
| Novita AI | $1.86 | $2.99 |
| Fireworks AI | $5.80 | $9.99 |
| Friendli AI | $4.90 | $5.90 |
| Together AI | $3.36 | $4.99 |
| Deepinfra | $2.40 | $3.00 |
上記のように、Novita AIはH100とH200の両方のGPUで最も競争力のある価格を一貫して提供しており、他の人気プロバイダーと比較して最大60%低くなっています。
つまり、Novita AIを選ぶことで、高スループットまたは長時間実行されるLLMデプロイのインフラコストを大幅に削減できます。
How to Get Started with Novita AI LLM Dedicated Endpoints
1. コンソールにアクセス
- Novita AI Consoleにログインします。
- 左側のサイドバーで、LLM Dedicated Endpoints をクリックします。
2. 新しいエンドポイントを作成
- 右上の + New Endpoint ボタンをクリックします。
3. エンドポイントを構成
設定フォームに以下のオプションを入力します:
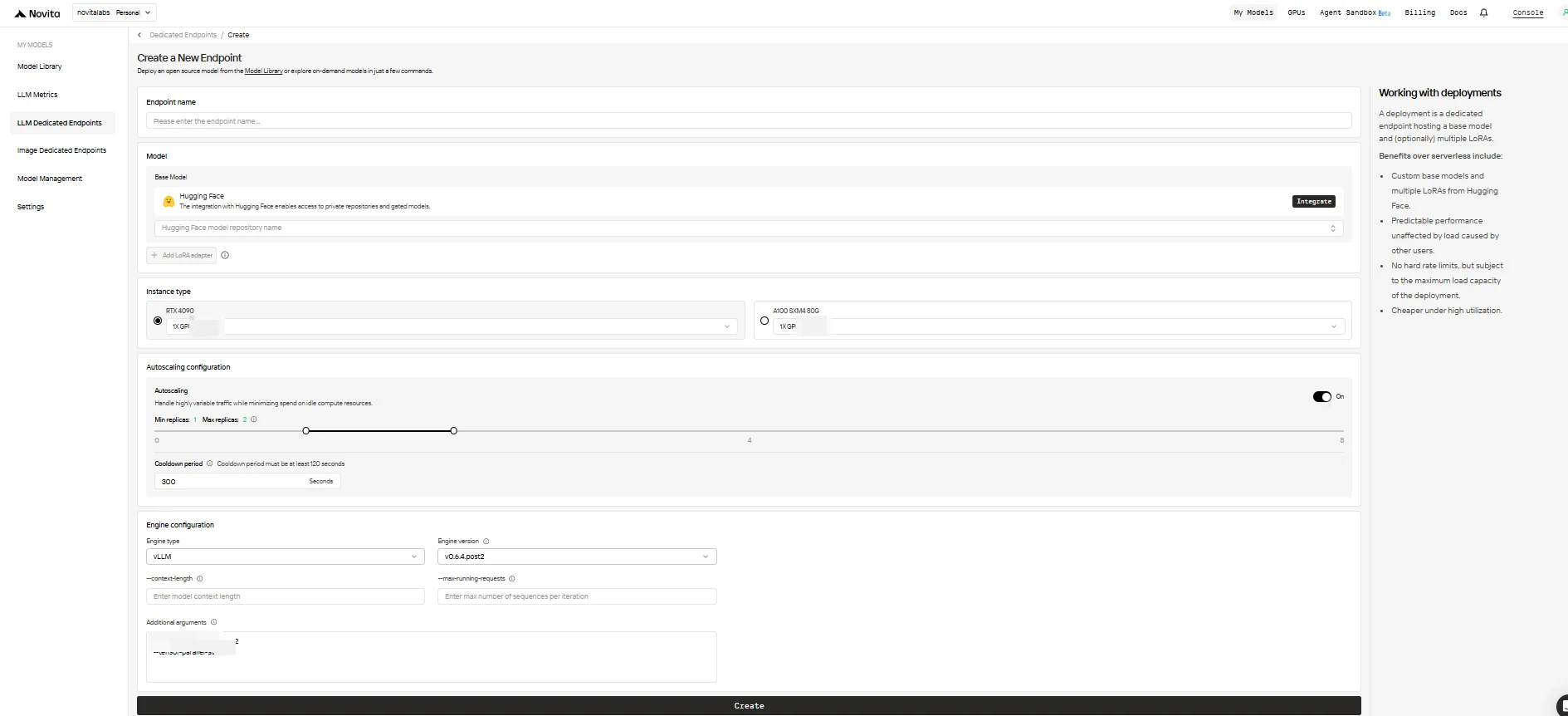
- エンドポイント名: デプロイに一意でわかりやすい名前を付けます。
- ベースモデル: ベースモデルのHugging Faceリポジトリ名を入力します(公開、非公開、ゲート付きのHugging Faceモデルのみサポート)。
- LoRAアダプター(オプション): 1つ以上のHugging Face Model IDを追加して、ベースモデルにLoRAアダプターをアタッチします。
- インスタンスタイプ: GPUハードウェアを選択します(例:H100、H200、RTX4090)。各ユーザーは全エンドポイントで最大8GPUまで使用できます。
- オートスケーリング構成:
- 最小レプリカ数: アイドル時にエンドポイントをスリープさせる場合は
0に設定(コスト節約)、または常にアクティブなレプリカを維持するために高い値を設定します。 - 最大レプリカ数: スケーリングのための最大レプリカ数を設定します(最大10)。
- クールダウン期間: トラフィックの一時的な低下時に早期のスケールダウンを防ぐため、レプリカをスケールダウンするまでの遅延(秒)を設定します。
- 最小レプリカ数: アイドル時にエンドポイントをスリープさせる場合は
- エンジン構成:
- エンジンタイプ: 推論エンジンを選択します(
vLLMまたはSGLang)。 - エンジンバージョン: デフォルト(最新)を使用するか、バージョンを指定します。
- コンテキスト長: オプションで最大トークンコンテキスト長を設定します。省略した場合はモデル構成から導出されます。
- 最大実行リクエスト数: イテレーションごとに処理されるシーケンスの最大数を設定します。
- 追加引数: 高度なカスタマイズのために、追加のエンジンパラメーターを追加します。
- エンジンタイプ: 推論エンジンを選択します(
完了したら、Create をクリックしてエンドポイントをデプロイします。
4. エンドポイントのデプロイステータス
作成後、エンドポイントはいくつかのステータスを遷移します:
- Sleeping: エンドポイントはアイドル状態で、コンピューティングリソースを消費しません(最小レプリカ数が0に設定されている場合)。
- Pending: デプロイの初期化中。
- Rolling: モデルとインフラストラクチャのセットアップ中。
- Running: エンドポイントがアクティブで、リクエストを処理可能。
このステータスはコンソールのエンドポイントページで確認できます。
5. Playgroundでエンドポイントをテスト
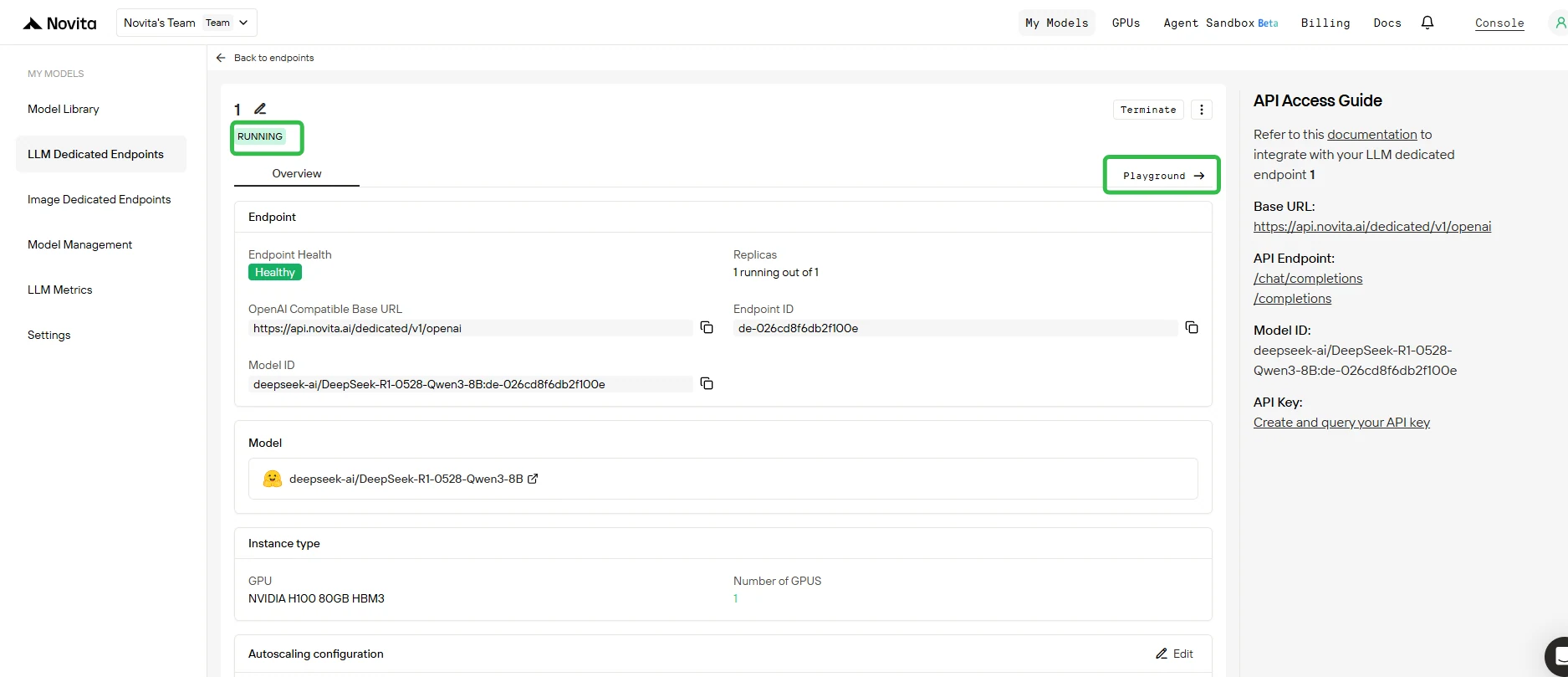
- デプロイが完了しステータスが Running になったら、エンドポイントをクリックして Playground タブを開きます。
- Playgroundでは、以下のことができます:
- ベースモデルとアタッチされたLoRAアダプターにテストプロンプトを送信できます。
- 異なるアダプターの出力をベースモデルと即座に比較できます。
6. 次のステップ
- マルチLoRAエンドポイント: 単一のエンドポイントに複数のLoRAアダプターをデプロイし、柔軟なモデル切り替えを実現します。
- API統合: 提供されたAPIエンドポイントを使用してリクエストを送信し、モデルを独自のアプリケーションに統合します。
- 最適化とスケーリング: ニーズの成長に合わせて、オートスケーリング、エンジン構成、GPUクォータを調整します。
- さらにリソースが必要ですか? 8GPU以上が必要な場合やエンタープライズレベルの機能が必要な場合は、営業チームまでお問い合わせください。
コード例(Pythonユーザー向け)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
まとめ
Novita AIの新しいLLM Dedicated Endpointは、カスタムHugging Faceモデルを自信を持ってデプロイおよびスケーリングできるようにします。柔軟なLoRAアダプター統合、シンプルなオートスケーリング、競争力のある透明な価格設定、そして99.5%のSLA保証をお楽しみいただけます。最初のファインチューニングモデルを立ち上げる場合でも、本番ワークロードを管理する場合でも、Novita AIはプロトタイプから本番環境への移行を迅速、安全、かつ効率的に実現します。
シームレスなLLMデプロイを体験しませんか? サインアップ ** するか、** 営業チームに連絡 ** してエンタープライズデモとカスタマイズされたプランをご確認ください。**
よくある質問
専用エンドポイントにどのようなモデルをデプロイできますか?
Hugging Faceから公開モデル、非公開モデル、ファインチューニングモデル、独自モデルを含むあらゆるモデルをデプロイできます。ベースモデルとカスタムまたはLoRAアダプターを備えたモデルの両方をサポートしています。
Dedicated EndpointとServerless Endpointの違いは何ですか?
Dedicated Endpointは、予約された分離されたハードウェアを提供し、一貫したパフォーマンス、高度なカスタマイズ、より高いスループットを実現します。対照的に、Serverless Endpointは共有インフラストラクチャ上で動作し、低使用量や変動する使用量に最適で、ハードウェア管理なしでの迅速なプロトタイピングに理想的です。
ワークロードの増加に合わせてDedicated Endpointをスケーリングできますか?
はい。Dedicated Endpointはリアルタイムの需要に基づくオートスケーリングをサポートしています。1GPUから始めて、ユーザーあたり最大8GPUまでスケールアップできます(エンタープライズオプションでさらに拡張可能)。ピーク時でもアプリケーションの応答性を維持できます。
Dedicated Endpointを監視および管理するにはどうすればよいですか?
各Dedicated Endpointには詳細なメトリクスとログが付属しています。WebコンソールまたはAPIを通じて、パフォーマンスの追跡、使用状況の監視、問題のトラブルシューティングが可能で、管理と最適化が簡単です。
価格オプションはどのようなものですか?また、コストをどのように管理できますか?
価格は透明で使用量ベースです。H100 GPUは1時間あたり1.86ドルから、H200 GPUは1時間あたり3.00ドルからです。使用した分だけお支払いいただきます。オートスケーリングと柔軟な管理により、特に本番ワークロードにおいて使用率を最適化し、コストを予測可能に保つのに役立ちます。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、AIアプリケーションの構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。



