

Новый сервис Novita AI — LLM Dedicated Endpoint — предоставляет возможность легко развертывать собственные или доработанные модели Hugging Face.
Благодаря выделенным GPU H100 от $1,86/час и H200 от $2,99/час, Novita AI предлагает крайне конкурентоспособные цены — зачастую более выгодные, чем у альтернатив, таких как Together AI, Fireworks AI и Friendli AI.
Наслаждайтесь гибкой поддержкой LoRA, соглашением об уровне обслуживания 99,5% и масштабируемыми вариантами GPU. Настройте готовые к эксплуатации конечные точки LLM за считанные минуты и уверенно управляйте ресурсами благодаря прозрачному и предсказуемому ценообразованию.
Что такое LLM Dedicated Endpoint?
LLM Dedicated Endpoint предоставляет частный облачный API для работы с большими языковыми моделями на инфраструктуре, зарезервированной исключительно для вашего использования. Такая конфигурация гарантирует стабильную производительность, высокую надежность и полную изоляцию ресурсов — в отличие от общих или бессерверных альтернатив.
С помощью выделенной конечной точки вы можете развертывать как открытые, так и приватные модели на Hugging Face, включая собственные или доработанные варианты. Конфиденциальные данные и интеллектуальная собственность остаются защищенными, поскольку ваши модели и трафик никогда не будут доступны другим пользователям.
Почему стоит выбрать LLM Dedicated Endpoint?
С LLM Dedicated Endpoint от Novita AI вы получаете надежную и гибкую среду для ваших AI-нагрузок:
- Развертывание пользовательских моделей: Легко обслуживайте любую модель Hugging Face, включая приватные и доработанные версии, в изолированной выделенной среде.
- Гибкое управление адаптерами LoRA: Подключайте и переключайтесь между несколькими адаптерами LoRA в рамках одной конечной точки. Экспериментируйте, итеративно улучшайте и поддерживайте разнообразные задачи без повторного развертывания базовой модели.
- Предсказуемая производительность: Выделенные ресурсы обеспечивают стабильную пропускную способность и низкую задержку, не зависящие от других пользователей. Отсутствуют жесткие лимиты на количество запросов — емкость вашей конечной точки определяется выбранным оборудованием и конфигурацией.
- Масштабируемое оборудование: Масштабируйтесь от бездействия (0 реплик) до 10 реплик на конечную точку и выбирайте тип GPU, соответствующий вашим требованиям. Каждый пользователь может использовать до 8 GPU, с возможностью корпоративного расширения.
- Прозрачное ценообразование: H100 от $1,86/час, H200 от $2,99/час — вы платите только за то, что используете. Выделенные конечные точки часто оказываются более экономичными, чем бессерверные решения, при высокой или постоянной нагрузке.
- Удобное управление: Интуитивно понятная веб-консоль для развертывания и управления, а также мгновенное тестирование в Playground для быстрой проверки.
- Готовая к эксплуатации надежность: Гарантия безотказной работы 99,5%, полное управление со стороны Novita AI для вашего спокойствия.
Как выбрать: выделенная конечная точка vs. бессерверная конечная точка
Выбор правильного типа конечной точки для LLM зависит от вашего сценария использования, рабочей нагрузки и эксплуатационных требований. Вот краткое руководство, которое поможет вам принять решение:
Выберите бессерверную конечную точку LLM (Serverless Endpoint), если:
- Вам нужен быстрый и гибкий доступ к публичным LLM без управления инфраструктурой.
- Ваша нагрузка невелика, изменчива или вы работаете над прототипом.
- Вы предпочитаете простое ценообразование по мере использования.
Выберите выделенную конечную точку LLM (Dedicated Endpoint), если:
- Вы хотите развернуть любую модель Hugging Face (включая приватные, доработанные или с ограниченным доступом).
- Вам требуется гибко настраивать адаптеры LoRA и параметры.
- Вам необходимо выделенное оборудование, стабильная высокая пропускная способность и надежность уровня production.
- Вы хотите оптимизировать затраты на GPU с самыми низкими ценами в отрасли.
- Вам нужно до 8 GPU на одного пользователя или больше.
Если вам требуется больше ресурсов, свяжитесь с нашей командой продаж для индивидуального корпоративного решения.
| Аспект | Бессерверная конечная точка LLM | Выделенная конечная точка LLM (DE) |
| Модель оплаты | Оплата за использование (за токены) | Оплата за GPU в час |
| Тип ресурсов | Общие, бессерверные (мультитенантные) | Выделенные, управляемые пользователем (однотенантные) |
| Стабильность производительности | Может колебаться (из-за общей нагрузки) | Предсказуемая, не зависит от других пользователей |
| Лимиты на запросы | Да (TPM, RPM в зависимости от уровня пользователя) | Нет жестких лимитов; ограничено квотой GPU пользователя |
| Выбор моделей | Только публичные модели | Загрузка пользовательских базовых моделей из репозиториев Hugging Face (публичных, приватных или с ограниченным доступом); поддержка настройки параметров LoRA |
| Выбор оборудования | Недоступен | Гибкий: H100, H200, 4090 и т.д. |
| Регион развертывания | Не выбирается пользователем | Пользователь может выбрать регион |
| SLA | Без формальных гарантий | SLA 99,5% |
| Стоимость при высокой нагрузке | Дороже при масштабировании | Дешевле при высокой нагрузке |
| Безопасность и изоляция данных | Общая среда | Полная изоляция арендаторов, частные конечные точки |
| Для кого подходит | Стартапы, прототипирование, переменная нагрузка | Предприятия, production, стабильная высокая пропускная способность, пользовательские базовые модели |
Сравнение цен на GPU для выделенных конечных точек
При выборе провайдера экономическая эффективность имеет решающее значение — особенно для развертываний на уровне production. Novita AI предлагает самые низкие почасовые тарифы на выделенные GPU H100 и H200 среди ведущих провайдеров:
| Провайдер | H100 (1 карта/ч) | H200 (1 карта/ч) |
| Novita AI | $1,86 | $2,99 |
| Fireworks AI | $5,80 | $9,99 |
| Friendli AI | $4,90 | $5,90 |
| Together AI | $3,36 | $4,99 |
| Deepinfra | $2,40 | $3,00 |
Как показано выше, Novita AI стабильно предлагает самые конкурентоспособные цены как для H100, так и для H200 GPU — до 60% ниже, чем у других популярных провайдеров.
Это означает, что вы можете значительно сократить расходы на инфраструктуру для высоконагруженных или долгосрочных развертываний LLM, выбрав Novita AI.
Как начать работу с LLM Dedicated Endpoints от Novita AI
1. Доступ к консоли
- Войдите в консоль Novita AI.
- На левой боковой панели нажмите LLM Dedicated Endpoints.
2. Создание новой конечной точки
- Нажмите кнопку + New Endpoint в правом верхнем углу.
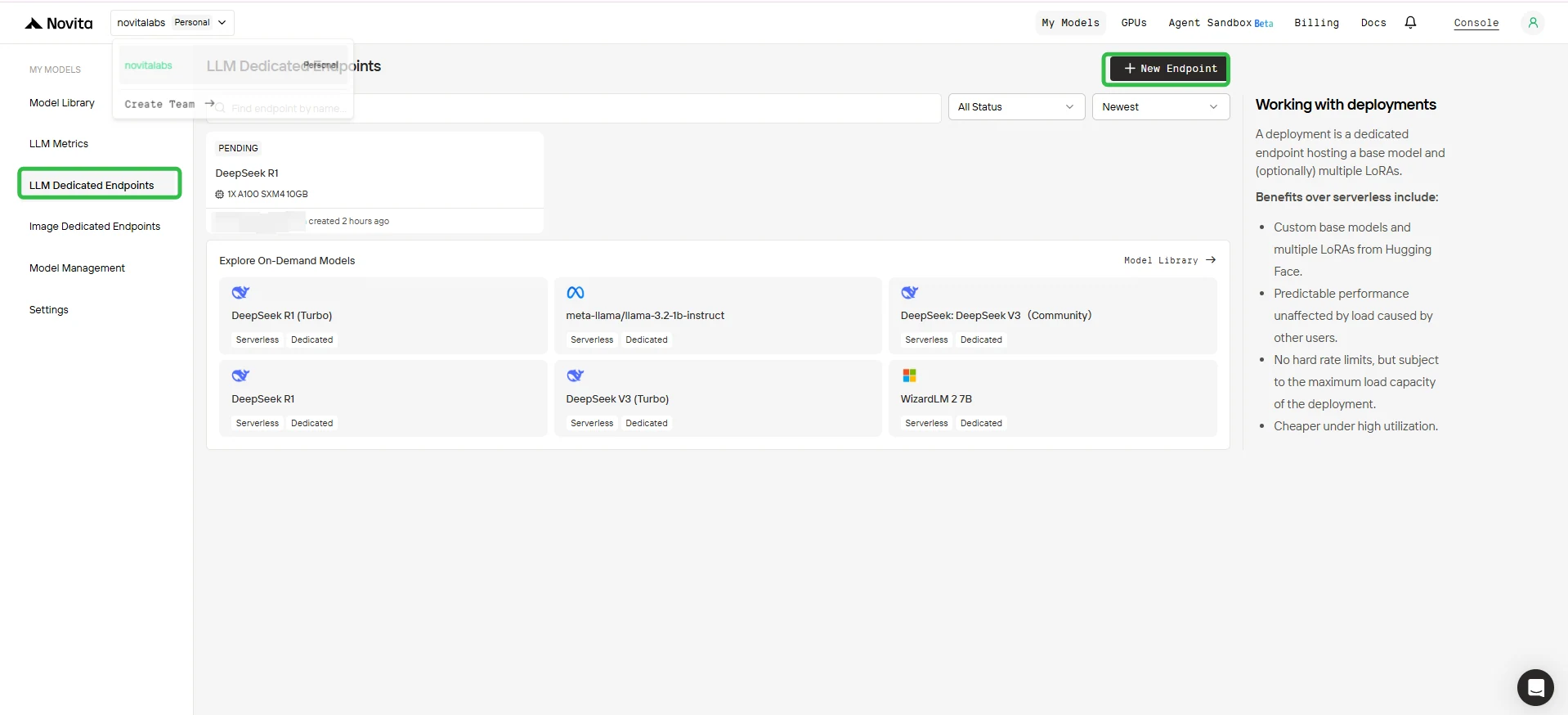
3. Настройка конечной точки
Заполните форму конфигурации, указав следующие параметры:
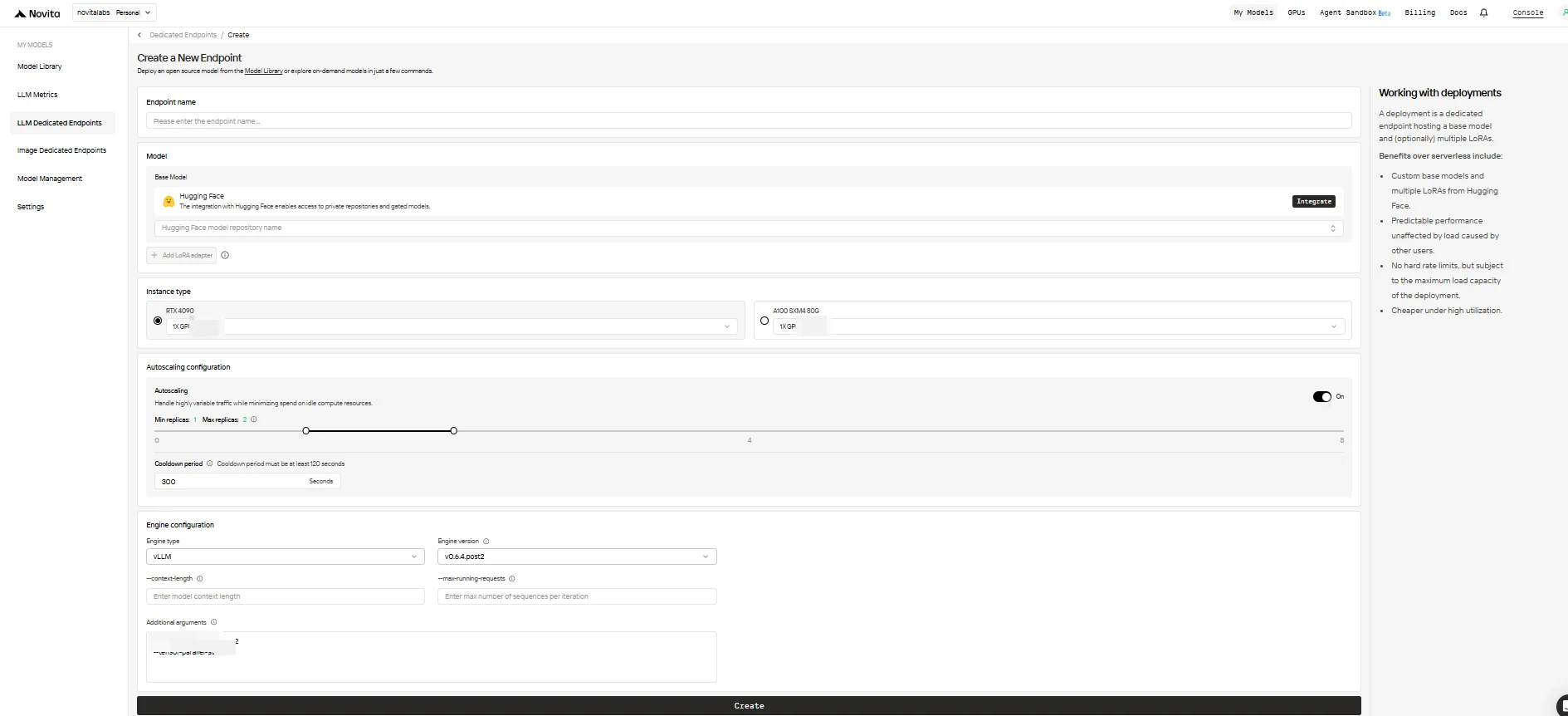
- Endpoint Name: Дайте вашему развертыванию уникальное и описательное имя.
- Base Model: Введите имя репозитория Hugging Face для вашей базовой модели (поддерживаются только модели Hugging Face, включая публичные, приватные или с ограниченным доступом).
- LoRA Adapters (необязательно): Добавьте один или несколько идентификаторов моделей Hugging Face, чтобы подключить адаптеры LoRA к вашей базовой модели.
- Instance Type: Выберите тип GPU (например, H100, H200, RTX4090). Каждый пользователь может использовать до 8 GPU во всех конечных точках.
- Autoscaling Configuration:
- Minimum Replicas: Установите
0, чтобы конечная точка «засыпала» в режиме ожидания (экономия средств), или укажите более высокое значение, чтобы всегда поддерживать минимальное количество активных реплик. - Maximum Replicas: Максимальное количество реплик для масштабирования (до 10).
- Cooldown Period: Задержка (в секундах) перед уменьшением количества реплик, чтобы избежать преждевременного сокращения при кратковременном падении трафика.
- Minimum Replicas: Установите
- Engine Configuration:
- Engine Type: Выберите движок вывода (
vLLMилиSGLang). - Engine Version: Используйте версию по умолчанию (последнюю) или укажите конкретную версию.
- Context Length: При необходимости укажите максимальную длину контекста в токенах; если не указано, будет взято из конфигурации модели.
- Max Running Requests: Количество последовательностей, обрабатываемых за одну итерацию.
- Additional Arguments: Добавьте любые дополнительные параметры движка для расширенной настройки.
- Engine Type: Выберите движок вывода (
Когда закончите, нажмите Create, чтобы развернуть конечную точку.
4. Статус развертывания конечной точки
После создания конечная точка будет проходить через несколько статусов:
- Sleeping: Конечная точка простаивает, не потребляя вычислительные ресурсы (если минимальное количество реплик установлено в 0).
- Pending: Идет инициализация развертывания.
- Rolling: Настраивается модель и инфраструктура.
- Running: Конечная точка активна и готова обрабатывать запросы.
Вы можете отслеживать этот статус на странице конечных точек в консоли.
5. Тестирование конечной точки в Playground
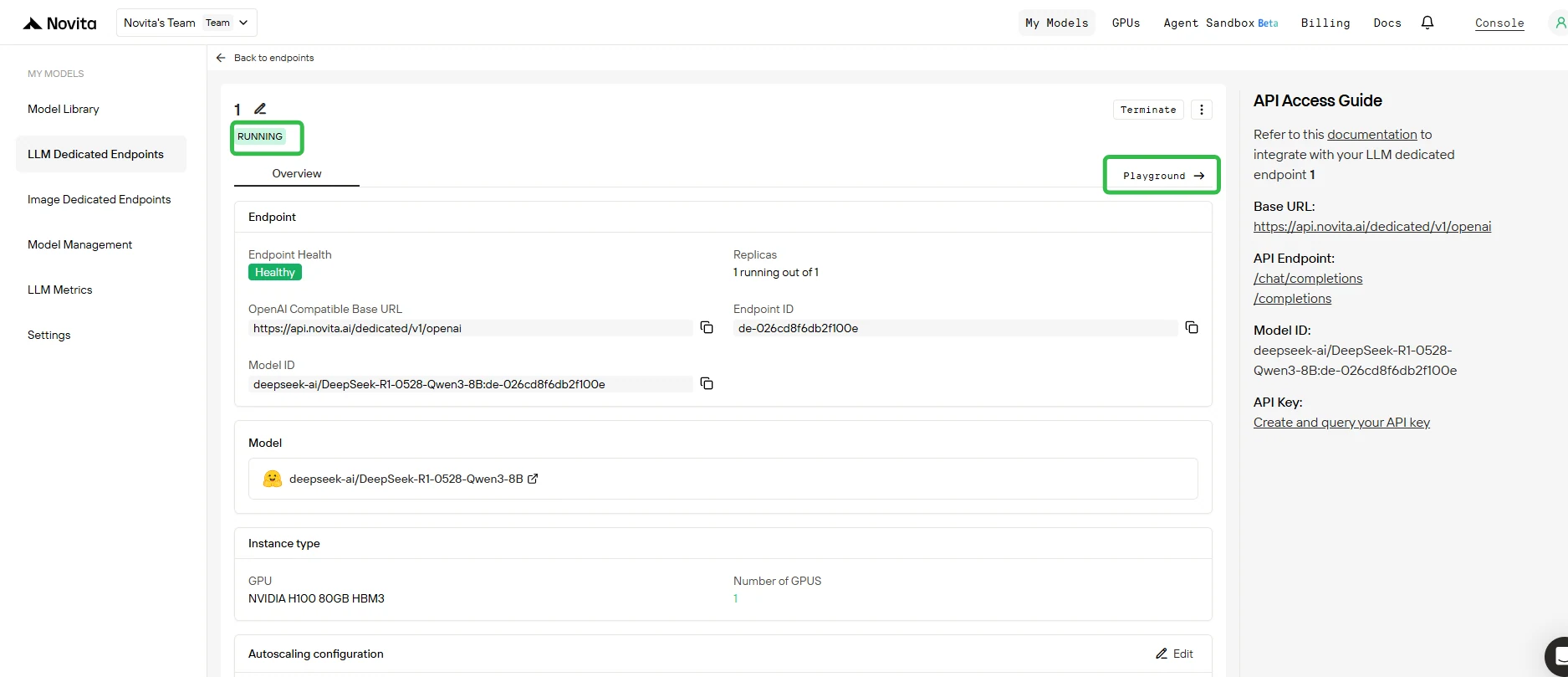
- Как только развертывание завершено и статус изменился на Running, нажмите на вашу конечную точку и откройте вкладку Playground.
- В Playground вы можете:
- Отправлять тестовые запросы к базовой модели и любым подключенным адаптерам LoRA.
- Мгновенно сравнивать вывод разных адаптеров с выводом базовой модели.
6. Дальнейшие шаги
- Много-LoRA конечные точки: Разверните несколько адаптеров LoRA на одной конечной точке для гибкого переключения моделей.
- Интеграция через API: Используйте предоставленные конечные точки API для отправки запросов и интеграции вашей модели в собственные приложения.
- Оптимизация и масштабирование: Настраивайте автоскалинг, конфигурацию движка и квоту GPU по мере роста ваших потребностей.
- Нужно больше ресурсов? Свяжитесь с нашей командой продаж для корпоративного решения, если вам требуется более 8 GPU или функции корпоративного уровня.
Примеры кода (для пользователей Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Заключение
Новый LLM Dedicated Endpoint от Novita AI позволяет развертывать и масштабировать пользовательские модели Hugging Face с уверенностью. Наслаждайтесь гибкой интеграцией адаптеров LoRA, простым автоскалингом, конкурентоспособными прозрачными ценами и гарантией уровня 99,5% SLA. Независимо от того, запускаете ли вы свою первую доработанную модель или управляете производственными нагрузками, Novita AI делает переход от прототипа к production быстрым, безопасным и эффективным.
Готовы к бесшовному развертыванию LLM? Зарегистрируйтесь сейчас или свяжитесь с нашей командой продаж для демонстрации корпоративного решения и индивидуального плана.
Часто задаваемые вопросы
Какие модели я могу развернуть на выделенной конечной точке?
Вы можете развернуть любую модель из Hugging Face, включая публичные, приватные, доработанные или проприетарные модели. Поддерживаются как базовые модели, так и модели с пользовательскими адаптерами или адаптерами LoRA.
Чем выделенная конечная точка отличается от бессерверной?
Выделенная конечная точка предоставляет вам зарезервированное изолированное оборудование для стабильной производительности, расширенной настройки и более высокой пропускной способности. Бессерверные конечные точки работают на общей инфраструктуре, лучше всего подходят для низкой или переменной нагрузки и идеальны для быстрого прототипирования без управления оборудованием.
Могу ли я масштабировать выделенную конечную точку по мере роста нагрузки?
Да. Выделенные конечные точки поддерживают автоскалинг на основе спроса в реальном времени. Вы можете начать с одного GPU и масштабироваться до 8 GPU на пользователя (с возможностью корпоративного расширения), гарантируя, что ваши приложения останутся отзывчивыми даже при пиковом трафике.
Как отслеживать и управлять выделенной конечной точкой?
Каждая выделенная конечная точка поставляется с подробными метриками и журналами. Вы можете отслеживать производительность, наблюдать за использованием и устранять неполадки через веб-консоль или API, что делает управление и оптимизацию простыми.
Какие варианты ценообразования и как контролировать расходы?
Ценообразование прозрачно и основано на использовании: от $1,86/час для GPU H100 и $3,00/час для GPU H200. Вы платите только за то, что используете. Автоскалинг и гибкое управление помогают оптимизировать использование и делать расходы предсказуемыми, особенно для производственных нагрузок.
Novita AI — это облачная платформа AI, предоставляющая разработчикам простой способ развертывания AI-моделей через наш простой API, а также доступное и надежное облако GPU для масштабирования.



