

Le LLM Dedicated Endpoint de Novita AI est un service nouvellement lancé qui vous permet de déployer facilement vos propres modèles Hugging Face personnalisés ou affinés.
Avec des GPU H100 dédiés à partir de 1,86 $/h et des H200 à partir de 2,99 $/h, Novita AI propose des prix très compétitifs – souvent plus avantageux que des alternatives comme Together AI, Fireworks AI et Friendli AI.
Profitez du support flexible de LoRA, d’un SLA de 99,5 % et d’options GPU évolutives. Mettez en place des endpoints LLM prêts pour la production en quelques minutes et gérez vos ressources en toute confiance grâce à une tarification transparente et prévisible.
Qu’est-ce qu’un LLM Dedicated Endpoint ?
Un LLM Dedicated Endpoint fournit une API cloud privée pour exécuter des grands modèles de langage sur une infrastructure réservée exclusivement à votre usage. Cette configuration garantit que vos modèles fonctionnent avec des performances constantes, une fiabilité élevée et un isolement complet des ressources – contrairement aux alternatives partagées ou serverless.
Avec un endpoint dédié, vous pouvez déployer des modèles open source et privés depuis Hugging Face, y compris vos variantes personnalisées ou affinées. Les données sensibles et la propriété intellectuelle restent protégées, car vos modèles et votre trafic ne sont jamais exposés à d’autres utilisateurs.
Pourquoi choisir LLM Dedicated Endpoint ?
Avec le LLM Dedicated Endpoint de Novita AI, vous bénéficiez d’un environnement robuste et flexible pour vos charges de travail d’IA :
- Déploiement de modèles personnalisés : Servez facilement n’importe quel modèle Hugging Face, y compris les versions privées et affinées, dans un environnement isolé et dédié.
- Gestion flexible des adaptateurs LoRA : Attachez et basculez entre plusieurs adaptateurs LoRA sur un seul endpoint. Expérimentez, itérez et prenez en charge diverses tâches sans redéployer votre modèle de base.
- Performances prévisibles : Des ressources dédiées garantissent un débit constant et une faible latence, sans être affecté par d’autres utilisateurs. Il n’y a pas de limites de débit strictes ; la capacité de votre endpoint est déterminée par le matériel et la configuration choisis.
- Matériel évolutif : Passez de l’inactivité (0 réplicas) à un maximum de 10 réplicas par endpoint, et choisissez le type de GPU qui correspond à vos besoins. Chaque utilisateur peut accéder à jusqu’à 8 GPU, avec une extension possible pour les entreprises.
- Tarification transparente : H100 à partir de 1,86 $/h, H200 à partir de 2,99 $/h – payez uniquement pour ce que vous utilisez. Les endpoints dédiés sont souvent plus rentables que les solutions serverless en cas d’utilisation élevée ou soutenue.
- Gestion conviviale : Console web intuitive pour le déploiement et la gestion, plus un Playground instantané pour une validation rapide.
- Fiabilité prête pour la production : Garantie de disponibilité de 99,5 %, entièrement gérée par Novita AI pour une tranquillité d’esprit.
Comment choisir : endpoint dédié vs. endpoint serverless
Le choix du type d’endpoint d’inférence LLM dépend de votre cas d’usage, de votre charge de travail et de vos exigences opérationnelles. Voici un guide rapide pour vous aider à décider :
Choisissez un endpoint LLM Serverless si :
- Vous souhaitez un accès rapide et flexible aux LLM publics sans gestion d’infrastructure.
- Votre utilisation est faible, variable ou pour du prototypage.
- Vous voulez une tarification simple à l’utilisation.
Choisissez un endpoint LLM Dedicated si :
- Vous souhaitez déployer n’importe quel modèle Hugging Face (y compris privé, affiné ou à accès restreint).
- Vous devez configurer des adaptateurs LoRA et des paramètres de manière flexible.
- Vous avez besoin de matériel dédié, d’un débit élevé stable et d’une fiabilité de niveau production.
- Vous souhaitez optimiser le coût GPU le plus bas du secteur.
- Vous avez besoin de jusqu’à 8 GPU par utilisateur, ou plus.
Si vous avez besoin de plus de ressources, veuillez contacter notre équipe commerciale pour une solution entreprise personnalisée.
| Aspect | Endpoint LLM Serverless | Endpoint LLM Dédié (DE) |
| Modèle de facturation | À l’utilisation (par token) | Par GPU et par heure |
| Type de ressources | Partagé, serverless (multi-tenant) | Dédié, contrôlé par l’utilisateur (mono-tenant) |
| Cohérence des performances | Peut fluctuer (charge partagée) | Prévisible, non affecté par les autres utilisateurs |
| Limites de débit | Oui (TPM, RPM par niveau utilisateur) | Pas de limites strictes ; limité par le quota GPU de l’utilisateur |
| Sélection de modèles | Modèles publics uniquement | Chargez des modèles de base personnalisés depuis les dépôts Hugging Face (publics, privés ou à accès restreint) ; supporte la configuration des paramètres LoRA |
| Choix du matériel | Non sélectionnable | Flexible : H100, H200, 4090, etc. |
| Région de déploiement | Non sélectionnable par l’utilisateur | L’utilisateur peut choisir la région |
| SLA | Aucune garantie formelle | SLA de 99,5 % |
| Coût en cas d’utilisation élevée | Plus cher à grande échelle | Moins cher en cas d’utilisation élevée |
| Sécurité et isolation des données | Environnement partagé | Isolation totale des locataires, endpoints privés |
| Idéal pour | Startups, prototypage, utilisation variable | Entreprises, production, débit élevé stable, modèles de base personnalisés |
Comparaison des prix des GPU pour endpoint dédié
Lors du choix d’un fournisseur, l’efficacité des coûts est cruciale – surtout pour les déploiements en production. Novita AI propose les tarifs horaires les plus bas pour les GPU H100 et H200 dédiés parmi les principaux fournisseurs :
| Fournisseur | H100 (1 carte/h) | H200 (1 carte/h) |
| Novita AI | 1,86 $ | 2,99 $ |
| Fireworks AI | 5,80 $ | 9,99 $ |
| Friendli AI | 4,90 $ | 5,90 $ |
| Together AI | 3,36 $ | 4,99 $ |
| Deepinfra | 2,40 $ | 3,00 $ |
Comme indiqué ci-dessus, Novita AI propose systématiquement les prix les plus compétitifs pour les GPU H100 et H200 – jusqu’à 60 % de moins que d’autres fournisseurs populaires.
Cela signifie que vous pouvez réduire considérablement les coûts d’infrastructure pour les déploiements LLM à haut débit ou de longue durée en choisissant Novita AI.
Comment démarrer avec les endpoints LLM Dedicated de Novita AI
1. Accéder à la console
- Connectez-vous à votre console Novita AI.
- Dans la barre latérale gauche, cliquez sur LLM Dedicated Endpoints.
2. Créer un nouvel endpoint
- Cliquez sur le bouton + New Endpoint dans le coin supérieur droit.
3. Configurer votre endpoint
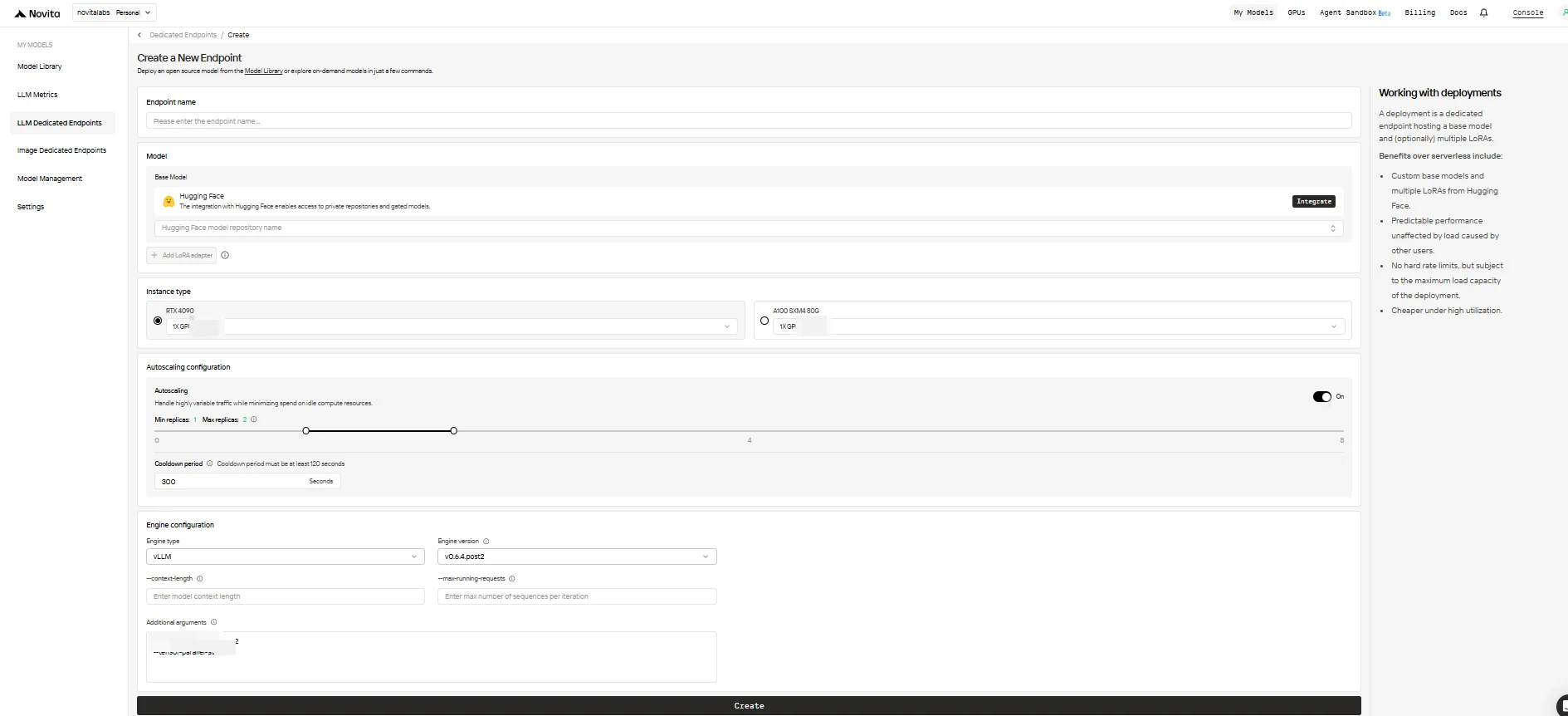
Remplissez le formulaire de configuration avec les options suivantes :
-
Endpoint Name : Donnez à votre déploiement un nom unique et descriptif.
-
Base Model : Saisissez le nom du dépôt Hugging Face pour votre modèle de base (seuls les modèles Hugging Face sont pris en charge, y compris les modèles publics, privés ou à accès restreint).
-
LoRA Adapters (facultatif) : Ajoutez un ou plusieurs identifiants de modèles Hugging Face pour attacher des adaptateurs LoRA à votre modèle de base.
-
Instance Type : Sélectionnez le matériel GPU (par ex. H100, H200, RTX4090). Chaque utilisateur peut utiliser jusqu’à 8 GPU sur tous les endpoints.
-
Configuration d’autoscaling :
- Minimum Replicas : Définissez sur
0pour permettre à l’endpoint de se mettre en veille en cas d’inactivité (économies), ou sur une valeur supérieure pour toujours conserver un nombre minimum de réplicas actifs. - Maximum Replicas : Définissez le nombre maximum de réplicas pour la mise à l’échelle (jusqu’à 10).
- Cooldown Period : Définissez le délai (en secondes) avant de réduire le nombre de réplicas afin d’éviter une réduction prématurée lors de brèves baisses de trafic.
- Minimum Replicas : Définissez sur
-
Engine Configuration :
- Engine Type : Choisissez le moteur d’inférence (
vLLMouSGLang). - Engine Version : Utilisez la version par défaut (la plus récente) ou spécifiez une version.
- Context Length : Définissez éventuellement la longueur maximale du contexte en tokens ; si omis, elle sera dérivée de la configuration du modèle.
- Max Running Requests : Définissez le nombre maximum de séquences traitées par itération.
- Additional Arguments : Ajoutez des paramètres supplémentaires pour une personnalisation avancée.
- Engine Type : Choisissez le moteur d’inférence (
Lorsque vous avez terminé, cliquez sur Create pour déployer votre endpoint.
4. Statut du déploiement de l’endpoint
Après la création, votre endpoint passe par plusieurs statuts :
- Sleeping : L’endpoint est inactif, ne consomme pas de ressources de calcul (si le nombre minimum de réplicas est défini sur 0).
- Pending : Le déploiement est en cours d’initialisation.
- Rolling : Le modèle et l’infrastructure sont en cours de configuration.
- Running : L’endpoint est actif et prêt à répondre aux requêtes.
Vous pouvez surveiller ce statut sur la page Endpoints de la console.
5. Tester votre endpoint dans le Playground
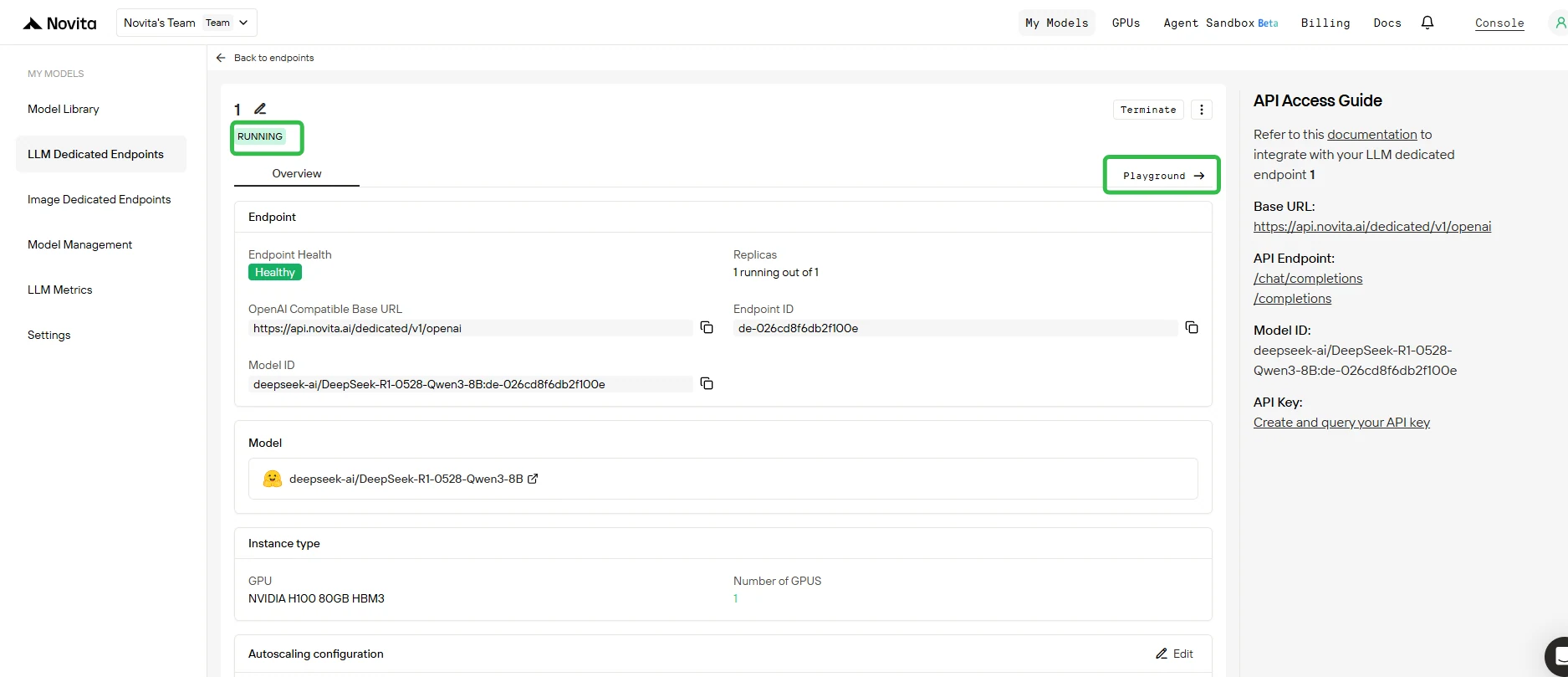
- Une fois le déploiement terminé et le statut Running, cliquez sur votre endpoint et ouvrez l’onglet Playground.
- Dans le Playground, vous pouvez :
- Envoyer des requêtes de test à votre modèle de base et à tous les adaptateurs LoRA attachés.
- Comparer instantanément la sortie de différents adaptateurs par rapport au modèle de base.
6. Prochaines étapes
- Endpoints multi-LoRA : Déployez plusieurs adaptateurs LoRA sur un seul endpoint pour un changement flexible de modèle.
- Intégration API : Utilisez les endpoints API fournis pour envoyer des requêtes et intégrer votre modèle dans vos propres applications.
- Optimiser et passer à l’échelle : Ajustez l’autoscaling, la configuration du moteur et le quota GPU selon l’évolution de vos besoins.
- Besoin de plus de ressources ? Contactez notre équipe commerciale pour une solution entreprise si vous avez besoin de plus de 8 GPU ou de fonctionnalités de niveau entreprise.
Exemples de code (pour les utilisateurs Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Conclusion
Le nouveau LLM Dedicated Endpoint de Novita AI vous permet de déployer et de faire évoluer des modèles Hugging Face personnalisés en toute confiance. Profitez d’une intégration flexible des adaptateurs LoRA, d’un autoscaling simple, d’une tarification transparente et compétitive, et de l’assurance d’un SLA de 99,5 %. Que vous lanciez votre premier modèle affiné ou que vous gériez des charges de travail de production, Novita AI simplifie le passage du prototype à la production – rapidement, en toute sécurité et efficacement.
Prêt à vivre une expérience de déploiement LLM fluide ? Inscrivez-vous dès maintenant ou contactez notre équipe commerciale pour une démonstration entreprise et un plan personnalisé.
Questions fréquemment posées
Quels modèles puis-je déployer sur un endpoint dédié ?
Vous pouvez déployer n’importe quel modèle de Hugging Face, y compris les modèles publics, privés, affinés ou propriétaires. Les modèles de base et les modèles avec des adaptateurs personnalisés ou LoRA sont pris en charge.
En quoi un endpoint dédié est-il différent d’un endpoint serverless ?
Un endpoint dédié vous fournit du matériel réservé et isolé pour des performances constantes, une personnalisation avancée et un débit plus élevé. En revanche, les endpoints serverless fonctionnent sur une infrastructure partagée, sont idéaux pour une utilisation faible ou variable, et parfaits pour un prototypage rapide sans gestion matérielle.
Puis-je faire évoluer mon endpoint dédié en fonction de ma charge de travail ?
Oui. Les endpoints dédiés prennent en charge l’autoscaling en fonction de la demande en temps réel. Vous pouvez commencer avec un GPU et passer à jusqu’à 8 GPU par utilisateur (avec des options entreprises pour plus), garantissant ainsi la réactivité de vos applications même en période de pointe.
Comment surveiller et gérer mon endpoint dédié ?
Chaque endpoint dédié est accompagné de métriques et de journaux détaillés. Vous pouvez suivre les performances, surveiller l’utilisation et résoudre les problèmes via la console web ou l’API, ce qui facilite la gestion et l’optimisation.
Quelles sont les options de tarification et comment contrôler les coûts ?
La tarification est transparente et basée sur l’utilisation, à partir de 1,86 $/h pour les GPU H100 et 3,00 $/h pour les GPU H200. Vous ne payez que pour ce que vous utilisez. L’autoscaling et la gestion flexible vous aident à optimiser l’utilisation et à maintenir des coûts prévisibles, en particulier pour les charges de travail de production.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour le passage à l’échelle.



