

نقطة نهاية LLM المخصصة من Novita AI هي خدمة تم إطلاقها حديثًا تمكنك من نشر نماذج Hugging Face الخاصة بك أو المعدلة بسهولة.
بدءًا من $1.86/ساعة لوحدات H100 و$2.99/ساعة لوحدات H200، تقدم Novita AI أسعارًا تنافسية للغاية—غالبًا ما تكون أكثر فعالية من حيث التكلفة من البدائل مثل Together AI وFireworks AI وFriendli AI.
استمتع بدعم LoRA المرن، وضمان SLA بنسبة 99.5%، وخيارات GPU قابلة للتوسع. قم بإعداد نقاط نهاية LLM جاهزة للإنتاج في دقائق، وأدر مواردك بثقة مع تسعير شفاف وقابل للتنبؤ.
ما هي نقطة نهاية LLM المخصصة؟
نقطة نهاية LLM المخصصة توفر واجهة برمجة تطبيقات خاصة قائمة على السحابة لتشغيل نماذج اللغة الكبيرة على بنية تحتية محجوزة لاستخدامك فقط. يضمن هذا الإعداد أن تعمل نماذجك بأداء ثابت وموثوقية عالية وعزل كامل للموارد—على عكس البدائل المشتركة أو التي لا تحتوي على خادم.
مع نقطة نهاية مخصصة، يمكنك نشر النماذج مفتوحة المصدر والخاصة على Hugging Face، بما في ذلك المتغيرات المخصصة أو المعدلة. تظل البيانات الحساسة والملكية الفكرية محمية، حيث لا تتعرض نماذجك وحركة المرور الخاصة بك أبدًا لمستخدمين آخرين.
لماذا تختار نقطة نهاية LLM المخصصة؟
مع نقطة نهاية LLM المخصصة من Novita AI، تحصل على بيئة قوية ومرنة لأعباء عمل الذكاء الاصطناعي الخاصة بك:
- نشر النماذج المخصصة: قم بسهولة بخدمة أي نموذج من Hugging Face، بما في ذلك الإصدارات الخاصة والمعدلة، داخل بيئة مخصصة ومعزولة.
- إدارة محولات LoRA المرنة: قم بإرفاق والتبديل بين عدة محولات LoRA على نقطة نهاية واحدة. جرب وكرر وادعم مهام متنوعة دون إعادة نشر النموذج الأساسي.
- أداء يمكن التنبؤ به: تضمن الموارد المخصصة إنتاجية ثابتة وزمن انتقال منخفض، دون تأثر بمستخدمين آخرين. لا توجد حدود صارمة للمعدل؛ يتم تحديد سعة نقطة النهاية الخاصة بك حسب الأجهزة والتكوين الذي تختاره.
- أجهزة قابلة للتوسع: توسع من الخمول (0 نسخ متماثلة) إلى ما يصل إلى 10 نسخ متماثلة لكل نقطة نهاية، واختر نوع GPU الذي يناسب متطلباتك. يمكن لكل مستخدم الوصول إلى ما يصل إلى 8 وحدات GPU، مع إمكانية التوسع للمؤسسات.
- تسعير شفاف: H100 من $1.86/ساعة، H200 من $2.99/ساعة—ادفع فقط مقابل ما تستخدمه. غالبًا ما تكون نقاط النهاية المخصصة أكثر فعالية من حيث التكلفة من الحلول بدون خادم تحت الاستخدام العالي أو المستمر.
- إدارة سهلة الاستخدام: وحدة تحكم ويب بديهية للنشر والإدارة، بالإضافة إلى بيئة اختبار فورية للتحقق السريع.
- موثوقية جاهزة للإنتاج: ضمان تشغيل بنسبة 99.5%، تتم إدارتها بالكامل بواسطة Novita AI لراحة البال.
كيفية الاختيار: نقطة نهاية مخصصة مقابل نقطة نهاية بدون خادم
يعتمد اختيار النوع المناسب من نقطة نهاية استدلال LLM على حالة الاستخدام وحجم العمل والمتطلبات التشغيلية. إليك دليل سريع لمساعدتك في اتخاذ القرار:
اختر نقطة نهاية LLM بدون خادم إذا:
- تريد وصولًا سريعًا ومرنًا إلى نماذج LLM العامة دون إدارة البنية التحتية.
- كان استخدامك منخفضًا أو متغيرًا أو للنماذج الأولية.
- تريد تسعيرًا بسيطًا يعتمد على الدفع حسب الاستخدام.
اختر نقطة نهاية LLM المخصصة إذا:
- تريد نشر أي نموذج من Hugging Face (بما في ذلك الخاص أو المعدل أو المقيد).
- كنت بحاجة إلى تكوين محولات LoRA والمعلمات بمرونة.
- تحتاج إلى أجهزة مخصصة وإنتاجية عالية مستقرة وموثوقية من الدرجة الإنتاجية.
- تريد تحسين أقل تكلفة GPU في الصناعة.
- تحتاج إلى ما يصل إلى 8 وحدات GPU لكل مستخدم، أو أكثر.
إذا كنت بحاجة إلى موارد إضافية، يرجى الاتصال بفريق المبيعات للحصول على حل مؤسسي مخصص.
| الجانب | نقطة نهاية LLM بدون خادم | نقطة نهاية LLM المخصصة |
| نموذج الفوترة | الدفع حسب الاستخدام (حسب الرمز) | الدفع لكل GPU في الساعة |
| نوع المورد | مشترك، بدون خادم (متعدد المستأجرين) | مخصص، يتحكم فيه المستخدم (مستأجر واحد) |
| ثبات الأداء | قد يتقلب (تحميل مشترك) | يمكن التنبؤ به، لا يتأثر بمستخدمين آخرين |
| حدود المعدل | نعم (TPM، RPM حسب طبقة المستخدم) | لا توجد حدود صارمة للمعدل؛ محدود بحصة GPU للمستخدم |
| اختيار النموذج | نماذج عامة فقط | تحميل نماذج أساسية مخصصة من مستودعات Hugging Face (عامة أو خاصة أو مقيدة)؛ يدعم تكوين معلمة LoRA |
| اختيار الأجهزة | غير قابل للاختيار | مرن: H100، H200، 4090، إلخ. |
| منطقة النشر | غير قابلة للاختيار من قبل المستخدم | يمكن للمستخدم اختيار المنطقة |
| SLA | لا يوجد ضمان رسمي | SLA بنسبة 99.5% |
| تكلفة الاستخدام العالي | أكثر تكلفة على نطاق واسع | أرخص عند الاستخدام العالي |
| الأمان وعزل البيانات | بيئة مشتركة | عزل كامل للمستأجر، نقاط نهاية خاصة |
| الأفضل لـ | الشركات الناشئة، النماذج الأولية، الاستخدام المتقلب | المؤسسات، الإنتاج، الإنتاجية العالية المستقرة، النماذج الأساسية المخصصة |
مقارنة أسعار GPU لنقاط النهاية المخصصة
عند اختيار مزود، تعتبر فعالية التكلفة أمرًا بالغ الأهمية—خاصة لنشر الإنتاج على نطاق واسع. تقدم Novita AI أقل أسعار بالساعة لوحدات GPU H100 وH200 المخصصة بين المزودين الرائدين:
| المزود | H100 (بطاقة واحدة/ساعة) | H200 (بطاقة واحدة/ساعة) |
| Novita AI | $1.86 | $2.99 |
| Fireworks AI | $5.80 | $9.99 |
| Friendli AI | $4.90 | $5.90 |
| Together AI | $3.36 | $4.99 |
| Deepinfra | $2.40 | $3.00 |
كما هو موضح أعلاه، تقدم Novita AI باستمرار الأسعار الأكثر تنافسية لكل من وحدات GPU H100 وH200—أقل بنسبة تصل إلى 60% من المزودين الآخرين المشهورين.
هذا يعني أنه يمكنك تقليل تكاليف البنية التحتية بشكل كبير لنشر LLM عالي الإنتاجية أو طويل الأمد باختيار Novita AI.
كيفية البدء مع نقاط نهاية LLM المخصصة من Novita AI
1. الوصول إلى وحدة التحكم
- سجل الدخول إلى وحدة تحكم Novita AI.
- في الشريط الجانبي الأيسر، انقر على نقاط نهاية LLM المخصصة.
2. إنشاء نقطة نهاية جديدة
- انقر على زر + نقطة نهاية جديدة في الزاوية العلوية اليمنى.
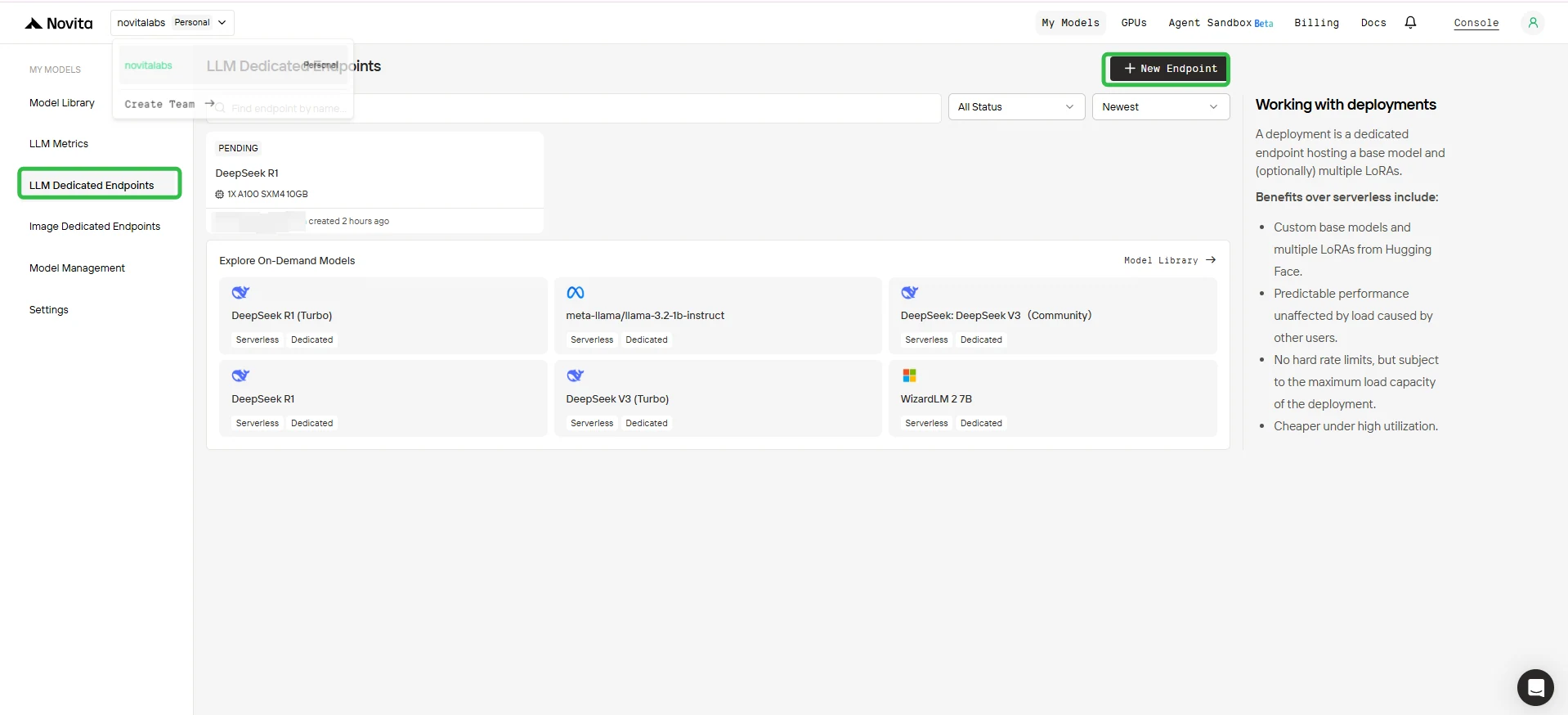
3. تكوين نقطة النهاية الخاصة بك
املأ نموذج التكوين بالخيارات التالية:
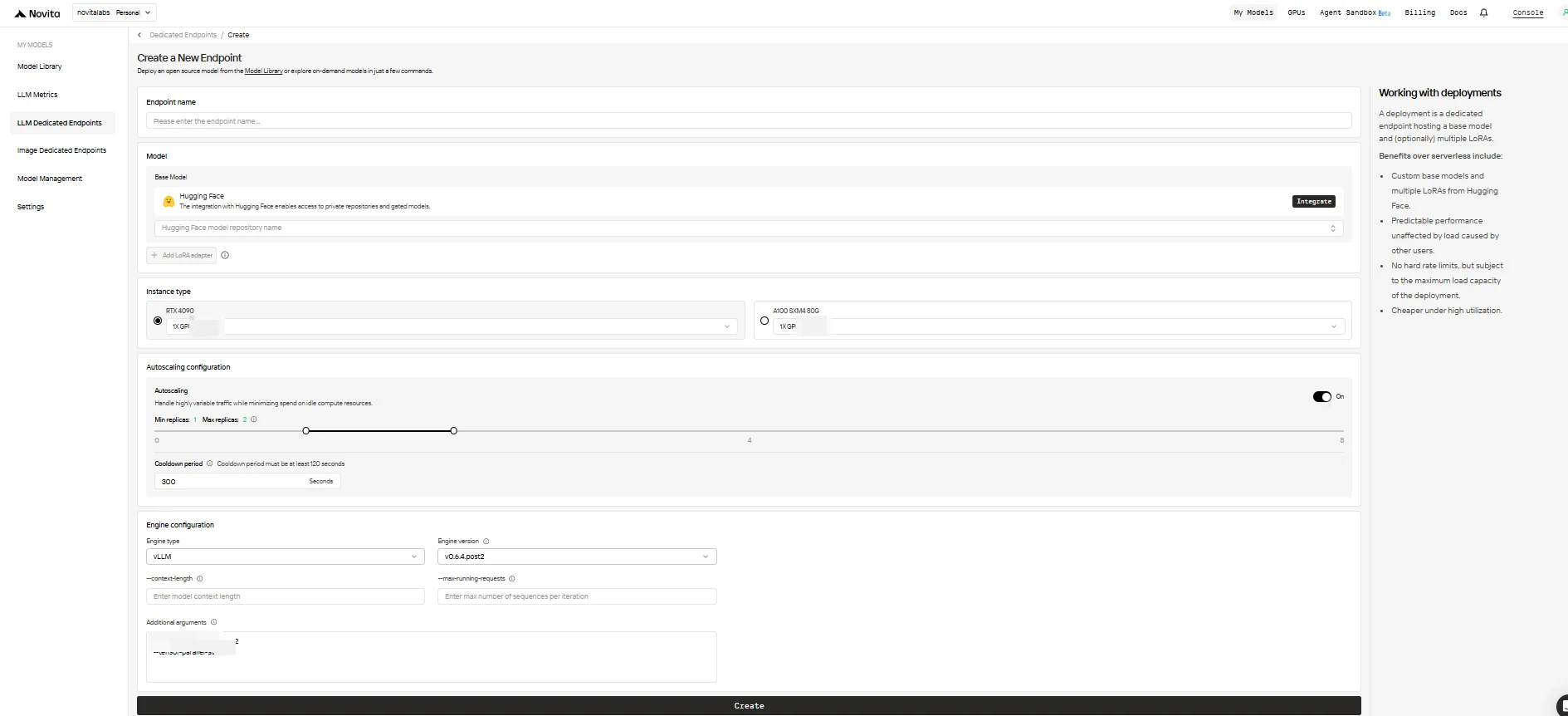
-
اسم نقطة النهاية: أعطِ لنشرك اسمًا فريدًا ووصفيًا.
-
النموذج الأساسي: أدخل اسم مستودع Hugging Face للنموذج الأساسي الخاص بك (يتم دعم نماذج Hugging Face فقط، بما في ذلك العامة أو الخاصة أو المقيدة).
-
محولات LoRA (اختياري): أضف معرفًا أو أكثر لنماذج Hugging Face لإرفاق محولات LoRA بنموذجك الأساسي.
-
نوع المثيل: حدد أجهزة GPU (مثل H100، H200، RTX4090). يمكن لكل مستخدم استخدام ما يصل إلى 8 وحدات GPU عبر جميع نقاط النهاية.
-
تكوين التوسع التلقائي:
- الحد الأدنى للنسخ المتماثلة: اضبط على
0للسماح لنقطة النهاية بالنوم عند الخمول (توفير التكاليف)، أو قيمة أعلى للحفاظ دائمًا على عدد أدنى من النسخ المتماثلة النشطة. - الحد الأقصى للنسخ المتماثلة: عيّن الحد الأقصى لعدد النسخ المتماثلة للتوسع (حتى 10).
- فترة التهدئة: عيّن التأخير (بالثواني) قبل تقليل النسخ المتماثلة لتجنب التخفيض المبكر خلال فترات انخفاض حركة المرور المؤقتة.
- الحد الأدنى للنسخ المتماثلة: اضبط على
-
تكوين المحرك:
- نوع المحرك: اختر محرك الاستدلال (
vLLMأوSGLang). - إصدار المحرك: استخدم الافتراضي (الأحدث) أو حدد إصدارًا.
- طول السياق: اختياريًا، عيّن الحد الأقصى لطول سياق الرمز؛ إذا تم حذفه، سيتم استخلاصه من تكوين النموذج.
- الحد الأقصى لطلبات التشغيل: عيّن الحد الأقصى لعدد التسلسلات التي تتم معالجتها لكل تكرار.
- وسائط إضافية: أضف أي معلمات محرك إضافية للتخصيص المتقدم.
- نوع المحرك: اختر محرك الاستدلال (
عند الانتهاء، انقر على إنشاء لنشر نقطة النهاية الخاصة بك.
4. حالة نشر نقطة النهاية
بعد الإنشاء، ستنتقل نقطة النهاية الخاصة بك عبر عدة حالات:
- نائم: نقطة النهاية في وضع الخمول، لا تستهلك موارد حاسوبية (إذا تم ضبط الحد الأدنى للنسخ المتماثلة على 0).
- قيد الانتظار: جارٍ تهيئة النشر.
- قيد التدوير: جارٍ إعداد النموذج والبنية التحتية.
- قيد التشغيل: نقطة النهاية نشطة وجاهزة لخدمة الطلبات.
يمكنك مراقبة هذه الحالة على صفحة نقاط النهاية في وحدة التحكم.
5. اختبار نقطة النهاية الخاصة بك في بيئة الاختبار
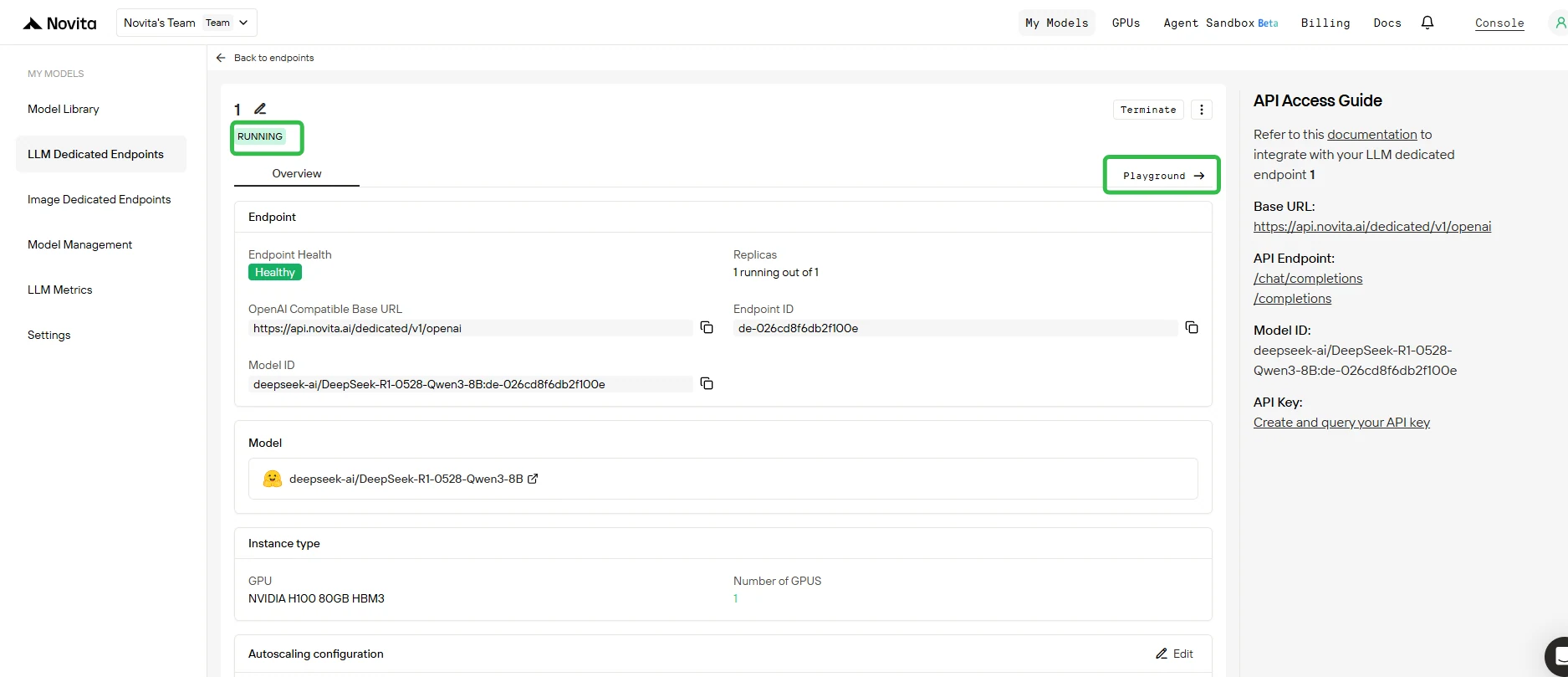
- بمجرد اكتمال النشر وكانت الحالة قيد التشغيل، انقر على نقطة النهاية الخاصة بك وافتح علامة التبويب بيئة الاختبار.
- في بيئة الاختبار، يمكنك:
- إرسال مطالبات اختبار إلى نموذجك الأساسي وأي محولات LoRA مرفقة.
- مقارنة مخرجات المحولات المختلفة مقابل النموذج الأساسي على الفور.
6. الخطوات التالية
- نقاط نهاية متعددة LoRA: انشر عدة محولات LoRA على نقطة نهاية واحدة للتبديل المرن بين النماذج.
- تكامل API: استخدم نقاط نهاية API المتاحة لإرسال الطلبات ودمج نموذجك في تطبيقاتك الخاصة.
- تحسين وتوسيع: اضبط التوسع التلقائي وتكوين المحرك وحصة GPU مع نمو احتياجاتك.
- هل تحتاج إلى موارد إضافية؟ اتصل بفريق المبيعات للحصول على حل مؤسسي إذا كنت بحاجة إلى أكثر من 8 وحدات GPU أو تتطلب ميزات على مستوى المؤسسات.
أمثلة على الكود (لمستخدمي Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
الخاتمة
نقطة نهاية LLM المخصصة الجديدة من Novita AI تمكنك من نشر وتوسيع نماذج Hugging Face المخصصة بثقة. استمتع بتكامل محول LoRA المرن، والتوسع التلقائي المباشر، والتسعير الشفاف التنافسي، وضمان SLA بنسبة 99.5%. سواء كنت تطلق أول نموذج معدّل لك أو تدير أعباء عمل إنتاجية، تجعل Novita AI الأمر بسيطًا للانتقال من النموذج الأولي إلى الإنتاج—بسرعة وأمان وكفاءة.
هل أنت مستعد لتجربة نشر LLM سلس؟ سجل الآن أو اتصل بفريق المبيعات لطلب عرض تجريبي مؤسسي وخطة مخصصة.
الأسئلة الشائعة
ما النماذج التي يمكنني نشرها على نقطة نهاية مخصصة؟
يمكنك نشر أي نموذج من Hugging Face، بما في ذلك النماذج العامة والخاصة والمعدلة والمملوكة. يتم دعم كل من النماذج الأساسية والنماذج ذات المحولات المخصصة أو LoRA.
كيف تختلف نقطة النهاية المخصصة عن نقطة النهاية بدون خادم؟
توفر نقطة النهاية المخصصة أجهزة محجوزة ومعزولة لأداء ثابت وتخصيص متقدم وإنتاجية أعلى. في المقابل، تعمل نقاط النهاية بدون خادم على بنية تحتية مشتركة، وهي أفضل للاستخدام المنخفض أو المتغير، ومثالية للنماذج الأولية السريعة دون إدارة الأجهزة.
هل يمكنني توسيع نقطة النهاية المخصصة الخاصة بي مع نمو عبء العمل؟
نعم. تدعم نقاط النهاية المخصصة التوسع التلقائي بناءً على الطلب في الوقت الفعلي. يمكنك البدء بوحدة GPU واحدة والتوسع حتى 8 وحدات GPU لكل مستخدم (مع خيارات مؤسسية للمزيد)، مما يضمن استمرار استجابة تطبيقاتك حتى خلال فترات الذروة.
كيف يمكنني مراقبة وإدارة نقطة النهاية المخصصة؟
تأتي كل نقطة نهاية مخصصة مع مقاييس وسجلات مفصلة. يمكنك تتبع الأداء ومراقبة الاستخدام واستكشاف المشكلات وإصلاحها من خلال وحدة التحكم عبر الويب أو API، مما يجعل الإدارة والتحسين أمرًا مباشرًا.
ما هي خيارات التسعير وكيف يمكنني التحكم في التكاليف؟
التسعير شفاف ويعتمد على الاستخدام، بدءًا من $1.86/ساعة لوحدات GPU H100 و$3.00/ساعة لوحدات GPU H200. أنت تدفع فقط مقابل ما تستخدمه. يساعدك التوسع التلقائي والإدارة المرنة على تحسين الاستخدام والحفاظ على التكاليف قابلة للتنبؤ، خاصة لأعباء العمل الإنتاجية.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



